

Abstract & Introduction & Related Work
- 研究任务
持续学习 - 已有方法和相关工作
- 面临挑战
- 虽然无监督和元训练在简单的数据集如MNIST和Omniglot上显示出比较好的结果,但它们缺乏对现实世界基准的扩展性。 相比之下,我们的DualNet将表征学习解耦到慢速学习器中,通过与监督学习阶段的同步训练,在实践中是可以扩展的。此外,我们的工作将自我监督的表征学习纳入持续的学习过程中,不需要任何预训练步骤
- 创新思路
- 提出了 DualNet,其中包括一个 快速学习系统,用于从特定任务中监督学习模式分离的表征,以及一个 慢速学习系统,用于通过自我监督学习(SSL)技术对任务无关的一般表征进行无监督学习,这两个快速和缓慢的学习系统是相辅相成的
- 实验结论
根据神经科学的互补学习系统(CLS)理论[37], 人类通过两个互补的系统进行有效的持续学习:
以海马体为中心的 快速学习系统,用于快速学习具体知识和个人经验;位于新皮质的 慢速学习系统,用于逐步获得关于环境的结构化知识
人类具有在其一生中学习和积累知识以完成不同认知任务的非凡能力。有趣的是,这种能力被归因于不同的相互联系的大脑区域之间的复杂互动。一个突出的模型是 互补学习系统(CLS)理论,该理论认为大脑可以通过 ” 海马体 “和 ” 新皮质 “这两个学习系统实现这种行为。特别是,海马体的重点是快速学习特定经验的模式分离表征。通过记忆巩固过程,海马体的记忆随着时间的推移被转移到新皮层,形成一个更普遍的表征,支持长期保留和对新经验的概括。这两个快速和缓慢的学习系统总是相互作用,促进快速学习和长期记忆。虽然深度神经网络已经取得了令人印象深刻的结果,但它们往往需要获得 大量独立同分布的数据,同时在任务流的持续学习场景中表现不佳。因此,本研究的重点是探索CLS理论如何能够激励一个通用的持续学习框架,在缓解灾难性遗忘和促进知识转移之间进行更好的权衡
在文献中,一些持续学习策略受到CLS理论原理的启发,从使用外显记忆到改进表征。然而,这些技术大多使用单一的主干来模拟海马体和新皮层,将两种表征类型结合到同一个网络中。此外,这类网络的训练是为了最小化监督损失,它们缺乏一个单独的、特定的慢速学习组件来支持 一般的表征学习。在持续学习过程中,通过对少量记忆数据反复进行监督学习得到的表征容易出现过拟合,而且在不同的任务中可能不能很好地泛化。考虑到在持续学习中,无监督的表征与有监督的表征相比,往往更容易被遗忘,而有监督的表征产生的改进很少;我们建议将表征学习与有监督的学习解耦为两个独立的系统。为了实现这一目标,类似于新皮层中的缓慢学习系统,我们建议使用 自我监督学习(SSL) 来实现缓慢的一般表征学习系统。请注意,最近的SSL工作集中在预训练阶段,这对于持续学习来说并不是小事,因为它在存储和计算成本方面都很庞大。我们认为,SSL应该被纳入持续学习过程,同时与监督学习阶段脱钩,成为两个独立的系统。因此,SSL的慢速表示法更具有普遍性,可以从数据中捕捉到 内在的特征,这有利于更好地概括新旧任务


; Method
Setting and Notations
数据:D = { x i , t i , y i } \mathcal{D} = {x_i, t_i, y_i}D ={x i ,t i ,y i } ,t i t_i t i 代表一个可选的任务标识符
每个标记的数据样本都是从代表一个任务的潜在分布 P t ( X , Y ) P^t(X,Y )P t (X ,Y )中抽取的,并且可以突然改变为P t + 1 P^{t+1}P t +1,表示任务切换
当任务标识符t被作为输入时, 任务设置遵循task-aware setting,即只选择相应的分类器进行预测
当不提供任务标识符时,该模型对目前观察到的所有类别有一个共享的分类器,这遵循无任务设置
我们在实验中考虑这两种情况。一个常见的持续学习策略是采用一个偶发存储器M来存储观察到的数据子集,并在学习当前样本时将它们交错起来。从M中,我们用M表示一个随机采样的小批量,用 M A M_A M A 、 M B M_B M B 表示通过应用两种不同的数据转换得到的 M M M 的两个视图。最后,我们用 j j j 表示慢速网络的参数,它从输入数据中学习一般的表征,用 θ θθ 表示快速网络的参数,它学习转换系数
DualNet Architecture
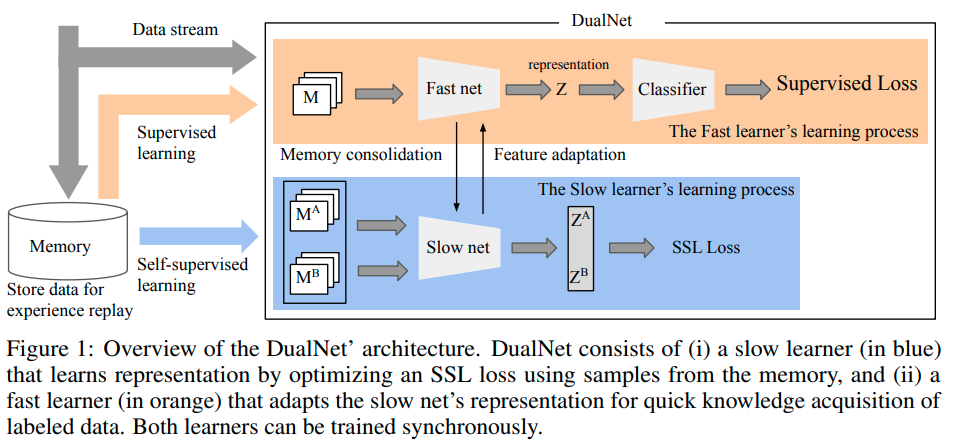
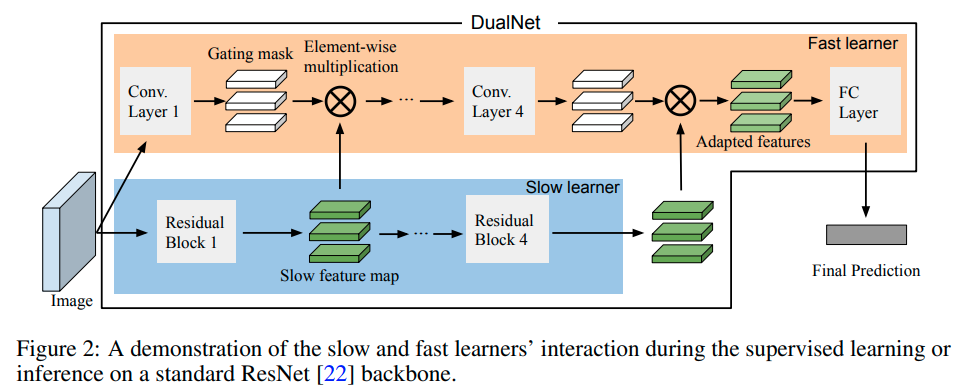
DualNet学习的数据表示独立于任务的标签,这使得在持续学习的情况下,跨任务的概括能力更好。该模型包括两个主要的学习模块(图1)
(i)慢速学习者负责学习一般的、与任务无关的表征;
(ii)快速学习者用连续的标记数据进行学习,快速捕捉新的信息,然后将知识整合到慢速学习者身上。
双网学习可以分解为两个同步阶段。
- 自我监督学习阶段,在这一阶段,慢速学习者使用来自外显记忆M的未标记数据优化自我监督学习(SSL)目标。
- 监督学习阶段,每当有标记样本到达时,就会触发快速学习者首先从慢速学习者那里查询表示,并使其适应学习这个样本。发生的损失将被反向传播到两个学习者中,用于监督知识的巩固。
此外,快速学习器的适应是基于每个样本的,不需要额外的信息,如任务标识符。请注意,DualNet使用与其他方法相同的外显存储器预算来存储样本和它们的标签,但慢速学习器只需要样本,而快速学习器则同时使用样本和它们的标签
; The Slow Learner
慢速学习器是一个标准的骨干网络 ϕ ϕϕ ,它被训练来优化SSL损失,用 L S S L \mathcal{L_{SSL}}L S S L 表示。因此,任何SSL目标都可以在这一步骤中应用。然而,为了最大限度地减少额外的计算资源,同时确保一般的代表性,我们只考虑SSL损失:
(i)不需要额外的内存单元(如MoCo[23]中的负队列)
(ii)不总是维护网络的额外副本(如BYOL[21])
(iii)不使用手工制作的借口损失(啥玩意?)(如RotNet[16]或JiGEN[6])
因此,我们考虑Barlow Twins [59],这是一种最近的最先进的SSL方法,以最小的计算开销取得了很好的结果。从形式上看,Barlow Twins需要两个视图 M A M_A M A 和 M B M_B M B ,通过对一批从存储器中采样的图像M应用两种不同的数据转换。然后,增强的数据被传递给慢速网络 j j j,以获得两个表示 Z A Z^A Z A 和 Z B Z^B Z B。Barlow Twins损失被定义为
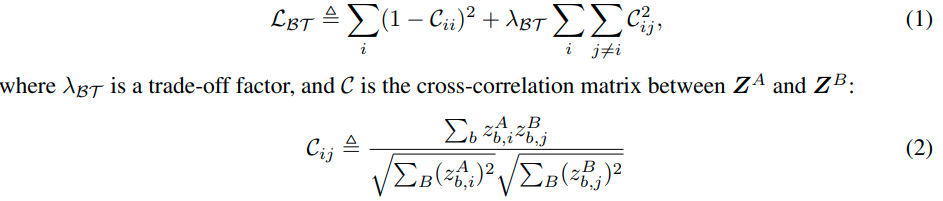
b表示mini-batch 的索引,i,j为矢量维度索引
直观地说,通过优化交叉相关矩阵的同一性,Barlow Twins强制网络学习对扭曲不变的基本信息(对角线上的单位元素),同时消除数据中的冗余信息(其他地方的零元素)。在我们的实现中,我们遵循SSL的标准做法,在慢速网络的最后一层上面采用投影仪来获得表征 Z A Z^A Z A、Z B Z^B Z B。对于快速网络的监督学习,将在第2.4节中描述,我们使用慢速网络的最后一层作为表示 Z Z Z
在大多数SSL方法中,LARS优化器[58]被用于在许多设备上进行分布式训练, 它利用了大量的无标签数据。然而,在持续学习中,外显存储器只存储少量的样本,由于存储器的更新机制,这些样本总是在变化。因此, 在整个学习过程中,外显记忆中的数据分布总是漂移的,与传统的SSL优化相比,DualNet中的SSL损失带来了不同的挑战。特别是,尽管持续学习中的SSL目标可以很容易地使用一个设备进行优化,但我们需要在较新的样本取代它们之前迅速捕捉当前存储的知识。在这项工作中,我们建议使用Look-ahead优化器[61]来优化慢速学习器,它可以执行以下更新
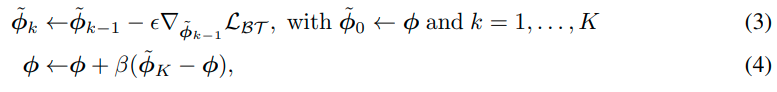
其中 β ββ 是Look-ahead的学习率,ϵ ϵϵ 是Look-ahead的SGD学习率。
作为K=1的特殊情况,优化降低到使用SGD的传统 L B T \mathcal{L_{BT}}L B T 优化。通过使用标准的SGD优化器进行K>1的更新, look-ahead权重 ϕ ^ K \hat{\phi}_K ϕ^K 被用来对原始慢速学习器j进行动量更新。因此,慢速学习器优化可以探索传统优化器未发现的区域,并享受更快的训练收敛[61]。
SSL侧重于最小化训练损失,而不是将这种损失泛化到未见过的样本上,而且学到的表征需要适应下游任务的良好表现。因此,这样的特性使得Look-ahead优化器成为比标准SGD更合适的选择来训练慢速学习器。
最后,我们强调,尽管我们在这项工作中选择使用Barlow Twins作为SSL目标,但DualNet与文献中的任何现有方法都是兼容的,我们将在第4.3节中进行经验探索。
此外,我们可以在后台通过优化方程1与快速学习器的持续学习同步来训练慢速学习器
The Fast Learner
给定一个有标签的样本{ x,y},快速学习器的目标是利用慢速学习器的表示,通过适应机制快速学习这个样本
在这项工作中,我们提出了一个新的背景无关的适应机制,通过扩展和改进通道级别的转换[42, 43]到一般的持续学习设置。特别是,我们建议训练快速学习器从图像x的原始像素中学习这些系数,而不是根据任务标识符生成转换系数。重要的是,转换是像素级的,而不是通道级的,以补偿任务标识符的丢失。形式上,让{ h i } i = 1 L {hi}^L_{i=1}{h i }i =1 L 是慢速学习器层在图像x上的特征图,例如h 1 、 h 2 、 h 3 、 h 4 h1、h2、h3、h4 h 1 、h 2 、h 3 、h 4 是ResNets[22]中四个残差块的输出,我们的目标是获得以图像x为条件的适应性特征h L ′ h^′L h L ′。因此,我们将快速学习器设计成一个具有L层的简单CNN,适应的特征h′L的获得方法是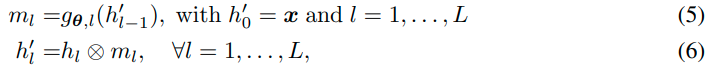
其中 ⊗ ⊗⊗ 表示元素相乘,g θ , l g{\mathbf{θ},l}g θ,l 表示快速网络 θ θθ 的第 l l l 层输出,其维度与相应的慢速特征 h l h_l h l 相同。最后一层转换后的特征 h L ′ h^′_L h L ′ 将被送入分类器进行预测。由于转换的简单性,快速学习器是轻量级的,但仍然可以利用慢速学习器的丰富表示。因此,快速网络可以快速捕捉数据流中的知识,这适合于在线持续学习。图2说明了快速和慢速学习者在监督学习或推理阶段的互动情况
; The Fast Learner’s Objective
为了进一步促进快速学习者在监督学习过程中的知识获取,我们还将当前的样本与以前的数据混合在偶发性记忆中,这是一种经验重放(ER)的形式。特别是,给定传入的标记样本 { x , y } {x,y}{x ,y } 和属于过去任务 k k k 的迷你批内存数据 M M M ,我们考虑在监督学习阶段用软标签损失[53]进行ER:
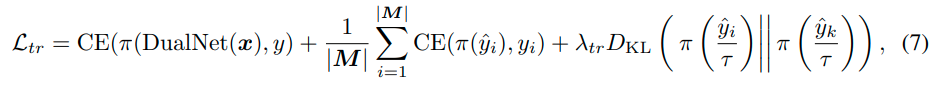
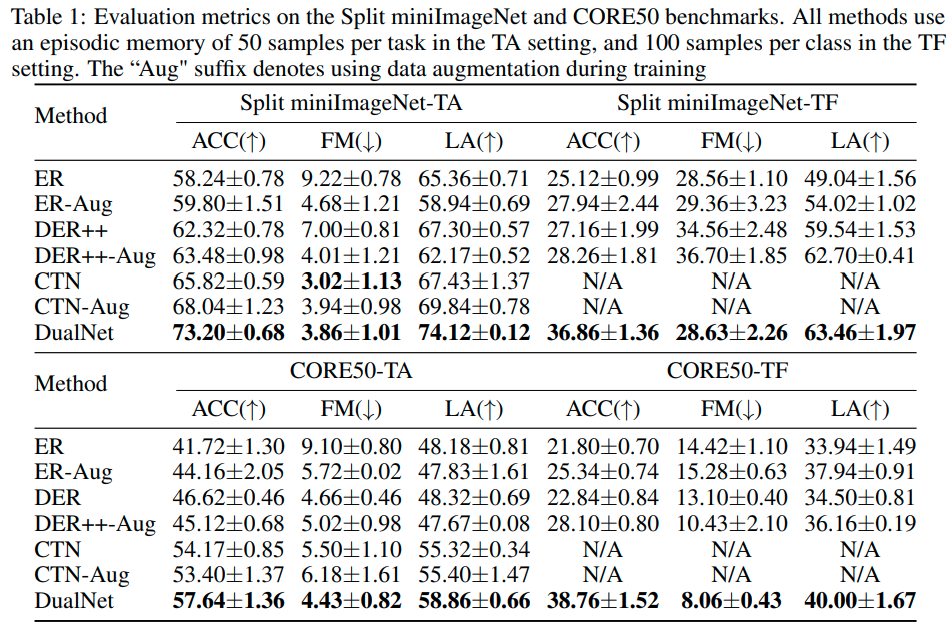
Experiments

; Conclusion
在本文中,我们提出了DualNet,一种新颖的持续学习范式,其灵感来自于神经科学中互补学习系统理论的快慢学习原理。
DualNet包括两个关键的学习组件。
(i) 一个慢速学习器,侧重于使用记忆数据学习一般的、与任务无关的表征
(ii) 一个快速学习器,侧重于通过一个新的适应机制捕捉新的监督学习知识
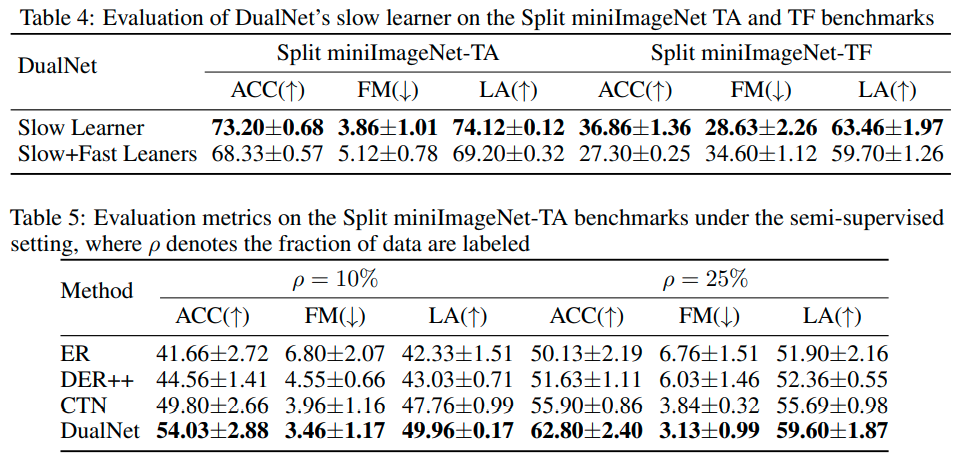
此外,快速和慢速学习器在同步工作时相互补充,形成了一个整体的持续学习方法。我们在两个具有挑战性的基准上进行的实验证明了DualNet的功效。最后,大量精心设计的消减研究表明,DualNet对慢速学习者的目标具有鲁棒性,可随更多的资源而扩展,并适用于半监督式的持续学习环境。
我们的DualNet提出了一个通用的持续学习框架,可以在现实世界的持续学习场景中享有很大的可扩展性。然而,应该妥善管理为连续训练慢速学习者而产生的额外计算成本。此外,在特定领域的应用应考虑到固有的挑战。最后,在这项工作中,我们采用了对比性的SSL方法来训练DualNet的慢速学习器。未来的工作包括设计一个为持续学习量身定做的慢速目标
Remark
ICLR2022里面第二篇把我idea做掉了的paper,并且跟learning fast,learning slow那篇的idea一模一样,我直接惊呆
Original: https://blog.csdn.net/Raki_J/article/details/124059973
Author: 爱睡觉的Raki
Title: Raki的读paper小记:DualNet: Continual Learning, Fast and Slow
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530051/
转载文章受原作者版权保护。转载请注明原作者出处!