

声明
摘要
虽然当前的3D对象识别研究主要集中在实时车载场景中,但许多非车载感知用例在很大程度上没有得到充分的探索,例如使用机器自动生成高质量的3D标签。由于有限的输入和速度限制,现在的三维物体探测器无法满足非车载使用的高质量要求。本文中,提出了一种新的非车载三维目标检测通道使用点云序列数据。观察到不同的帧捕获物体的互补视图,设计了非车载检测器,通过多帧对象检测和新的以物体为中心的细化模型来利用时间点。通过对Waymo开放数据集的评估展现出显著的优势。它的性能甚至等同于通过人类标签研究验证的人类标签。进一步的实验证明了自动标签在半监督学习中的应用。
引言
大多数3D预测研究都集中在实时车载用例上,只考虑来自当前帧或少数历史帧的传感器输入。
对于许多需要最佳感知质量的非车载用例,这些模型是次优的。
其中,一个重要的方向是让机器”自动标记”数据,以节省人工标记的成本。
高质量的感知也可以用于模拟或构建数据集,以监督或评估下游模块,如行为预测。
非车载通道利用整个传感器序列输入(此类视频数据在自动驾驶和增强现实中很常见)
由于对模型因果关系没有约束,对模型推理速度的约束也很小,能够大大扩展3D对象检测器的设计空间,并实现显著更高的性能。


在点云序列中,一个物体的不同视点包含关于其几何结构的补充信息(如Fig2)
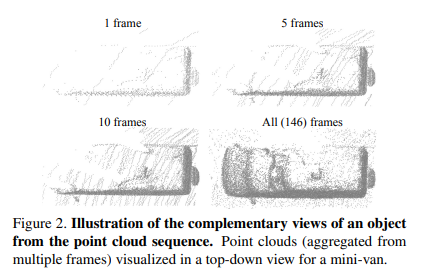

为了充分利用时态点云(例如10s或更长时间),摒弃了基于帧的通用输入结构,其中点云的整个帧被合并。
相反,作者转向 以目标为中心的设计。
首先利用性能最佳的多帧检测器来提供初始目标定位。
然后,通过多目标跟踪链接在不同帧中检测到的目标。
基于检测box和原始点云序列,可以提取物体的整个跟踪数据,包括其所有传感器数据(点云)和检测box,即4D:3D空间+1D时间。
然后,提出了新的深度网络模型来处理这样的4D目标跟踪数据,并输出时间已知且高质量的目标box。
本文主要贡献:
(1)制定非车载3D对象检测问题,并提出利用多帧检测器和新颖的以目标为中心的自动标记模型的特定通发
(2)在极具挑战性的Waymo数据集上实现最先进的3D目标检测性能。
(3)3D物体检测的人体标签研究,以及人体标签和自动标签之间的比较
(4)证明了自动标签在半监督学习中的有效性
; Offboard 3D Object Detection
给定动态环境的一系列传感器输入(时间数据),目标是在3D场景中为每一帧定位和分类对象。
点通道包括传感器坐标X,Y,Z(在每一帧处)和其他可选信息,如颜色和强度。
假设传感器姿态已知。
在世界坐标系的每一帧,我们可以补偿自我运动。
对于每一帧我们输出一个3D边界框(由其中心,大小和方向参数化)、类型以及帧中现实的所有物体的唯一ID。
与仅使用单帧输入相比,访问时间数据(历史和未来)导致检测器的设计空间更大。
一种基准设计是将单帧3D目标检测器扩展为使用多帧输入。尽管之前的工作已经证明了其有效性,但多帧检测器很难放大到多个帧,并且无法补偿物体运动,因为整个场景进行了帧叠加。
多帧输入对检测器质量的贡献随着叠加更多的帧而减小。
另一种想法是扩展两级探测器的第二阶段,从多个帧中获取目标点。与对整个场景进行多帧输入相比,第二阶段只处理提案的目标区域。但是,决定使用多少上下文框架并不直观。设置一个固定的数字可能对某些目标很有效,但对其他目标不太理想。
与上述以帧为中心的设计(输入总是来自固定数量的帧)相比, 我们意识到有必要为每个目标独立的自适应的选择时间上下文大小,从而实现以目标为中心的设计。
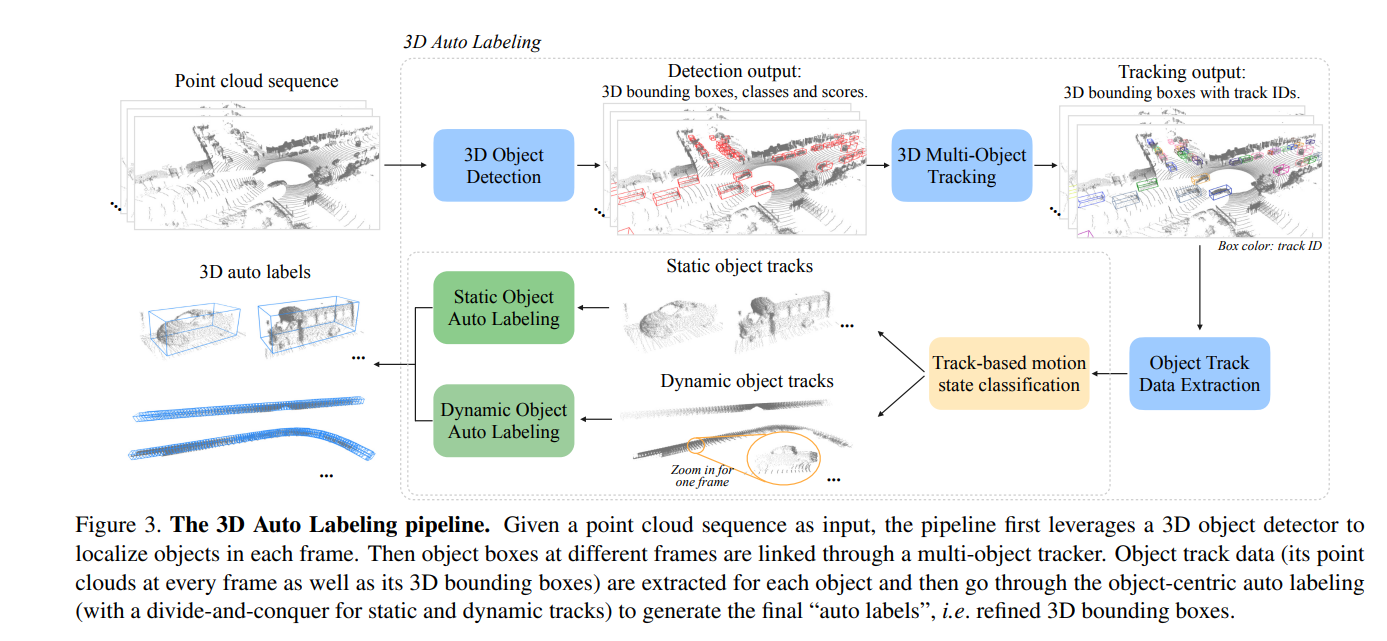
如Fig3可以利用强大的多帧检测器来进行初始目标定位。然后对每个目标,通过跟踪,可以以他出现的所有帧中提取所有相关的目标点云和检测框。后续模型可以获取此类目标轨迹数据,以输出目标的最终轨迹级别细化框。
由于此过程模拟了人工标记如何在点云序列中注释三维目标(随时间定位、跟踪和细化轨迹),因此选择将通道成为三维自动标记。
3D Auto Labeling Pipline
1.Multi-frame 3D Object Detection
MVF++:MVF++作为通道的入口,准确的目标检测对于下游模块至关重要。通过在三个方面扩展性能最好的多视图融合(MVF)检测器。
(1)为了增强点级特征的辨别能力,为3D语义分割添加了一个辅助损失,如果点位于地面真值3D框的内部/外部,则将其标记为正/负
(2)为了获取更精确地训练目标和提高训练率,我们在MVF论文中取消了锚点匹配步骤,并采用了Anchor-free设计
(3)为了在非车载环境中充分利用可用的计算资源,重新设计了网络架构并增加了模型容量。
Multi-frame MVF++:多帧MVF++扩展了MVF模型以使用多个激光雷达扫描。来自多个连续扫描的点将基于ego-motion变换为当前帧。,每个点通过一个额外的通道扩展,对相对时间偏移进行编码。
Test-time augmentation
通过测试时间增强(TTA)通过将点云绕Z轴旋转10个不同角度,以及使用加权box融合预测,进一步增强3D检测。 虽然这回导致计算复杂度过高,但在非车载设置中,TTA可以跨多个设备并行,以便款速执行。
2.Multi-Object Tracking
多目标跟踪模块跨帧链接检测到的目标。考虑到强大的多帧检测器,选择通过检测路径进行跟踪,并有一个单独的非参数跟踪器。与联合检测和跟踪方法相比,这导致了更简单、更模块化的设计。
3.Object Track Data Extraction
介绍如何使用目标轨迹数据”自动标记”目标。
如Fig3所示,该过程包括三个阶段:基于轨迹的运动状态分类、静态对象自动标记和动态对象自动标记。
(1)Divide and conquer:motion state estimation
在现实世界中,很多物体在一段时间内是完全静止的。在非车载检测方面,最好将单个3D边界框指定给静态物体,而不是在不同帧中单独指定框,以避免抖动。
采用分而治之的方法来处理静态和动态物体,在自动标记之前引入一个模块来分类目标的运动状态(精致或运动)。虽然从几帧很难预测物体的运动状态(由于感知噪声),但如果使用所有目标轨迹数据,这就相对容易。
使用来自目标轨迹框的一些启发式特征的线性分类器已经可以实现99%以上的车辆运动状态分类精度。
(2)Static object auto labeling
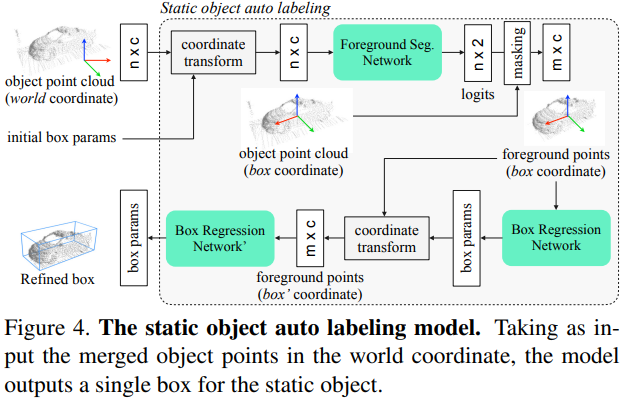
如Fig4,首先(通过旋转和平移)将目标点转换为框坐标,然后在对每个目标进行处理,这样点云在目标之间更加对齐。在长方体坐标中,+X是长方体头坐标,远点是长方体中心。
因为有完整的检测器box序列,所以可以有多个选项选择哪个box作为初始box。这种选择实际上对模型性能有重大影响。根据经验,使用检测器得分最高的box可获得最佳性能。
为了倾向于目标,目标点通过实例分割网络来分割前景(前景点由掩码提取)。受RCNN的启发,迭代回归目标的边界框。测试时,可以通过增加测试时间进一步提高box回归精度。
所有网络均基于PointNet体系结构。该模型由分割和box估计的基本事实监督。
4.Dynamic object auto labeling
对于移动的物体,需要为每个帧预测不同的三维边界框。
由于顺序输入/输出,模型设计空间比静态目标大得多。
基准用于使用裁剪的点云重新估计三维边界框。与跟踪中的滤波类似,还可以根据检测器box的序列细化box。
另一种选择是相对于关键帧(例如,当前帧)”对齐”或配准目标点,以获得更密集的点云,用于框估计。然而,对齐可能是一个比框估计更困难的问题,尤其是对于具有较少点的被遮挡或远离的目标。此外,像行人这样的可变性物体的对齐也是一个挑战。
如Fig5,改设计利用了点云和检测器box序列,而 无需明确地将点云与关键帧对齐。。该模型以滑动窗口的形式预测每一帧的目标框。由两个分支组成,一个采用点序列,一个采用box序列。
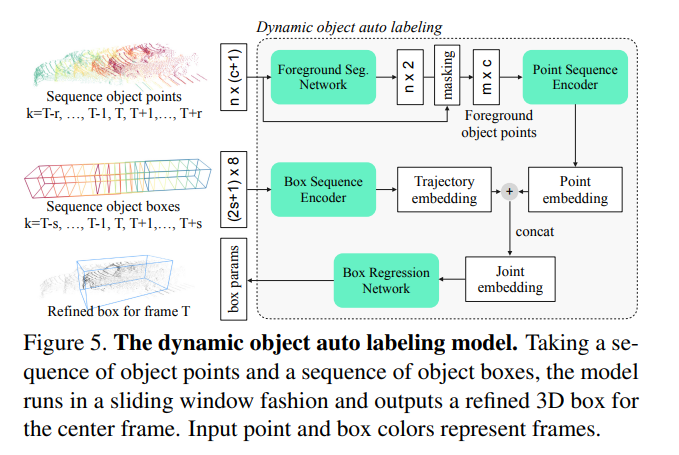
对于点云分支,模型采用目标点云的子序列。向每个点添加时间编码通道后,子序列点通过并集合并,并在中心帧处为检测器box的box坐标。接着有一个基于PointNet的分割网络来对前景点进行分类,然后通过另一个点编码网络将目标点编码为一个embedding。
对于长方体序列分支,长方体序列帧将转换为长方体框架处探测器box的坐标。长方体子序列可以比点子序列长,以捕获长的轨迹嵌入,其中每个box是一个具有7维几何和1维时间编码的点。
然后,将计算出的目标嵌入和轨迹嵌入连接起来,形成联合嵌入,然后通过一个box回归网络预测帧处的目标box。
Original: https://blog.csdn.net/dydwl/article/details/122390614
Author: 学一点@
Title: Offboard 3D Object Detection From Point Cloud Sequences
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/683184/
转载文章受原作者版权保护。转载请注明原作者出处!