

五.借助Torchtext建立vocabulary,把每个单词映射到数字id
六.创建Iterator,每个itartion都是返回一个batch的样本
一.导入需要的库
import collections
import os
import random
import time
from tqdm import tqdm
import numpy as np
import torch
from torch import nn
import torchtext.vocab as Vocab
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plt
import seaborn as sns
#os.environ["CUDA_VISIBLE_DEVICES"] = "6"
#使用GPU运算
device=torch.device("cuda:6" if torch.cuda.is_available() else "cpu")
二.数据读取并查看
#读取处理好的数据
import pandas as pd
data=pd.read_csv("/root/Jupyter/Data_cleaning/Cleaned_data.csv")
#查看数据
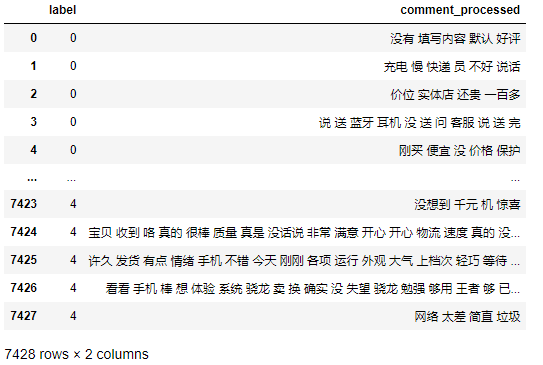
data

三.使用word2vector生成词向量
1.先将评论转化为列表
#首先将comment_processed中的每一条评论转换为列表
word_list=[str(s).split() for s in data["comment_processed"]]
print(word_list)

2.使用w2v进行词向量的生成
from gensim.models import word2vec
import time
start = time.time()
#窗口大小设置为3,词的最小出现次数为1
model_w2v = word2vec.Word2Vec(word_list, window = 3, iter = 5,size=256,min_count=1)
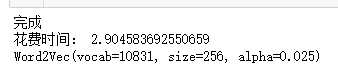
print('完成')
end = time.time()
print('花费时间:', end - start)
print(model_w2v)
#将模型保存
model_w2v.save('w2v')
3.查看生成的词向量
#查看词向量的生成效果
#查看词向量的维度
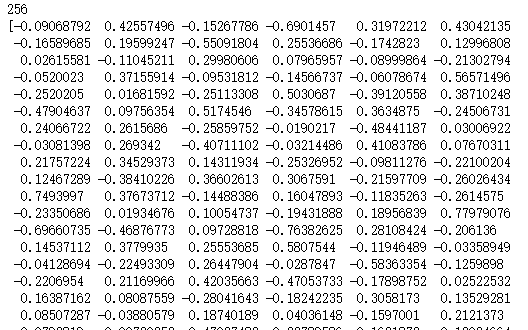
print(len(model_w2v['手机']))
print(model_w2v['手机'])
#查看与手机相近的词
model_w2v.most_similar(["充电"])

四.将数据集划分为训练集和验证集
- 由于现在只有split只能创建train、valid这两个分类,所以我们需要创建一个新的test set。我们可以使用
.split()创建新的分类。 - 默认的数据分割是 70、30,如果我们声明
split_ratio,可以改变split之间的比例,test_size=0.2表示80%的数据是训练集,20%是验证集。 - 我们还声明
random_state这个参数,确保我们每次分割的数据集都是一样的。
from sklearn.model_selection import train_test_split
Temp_trin, valid_data = train_test_split(data,test_size=0.2, random_state=42) #默认split_ratio=0.7
train_data,test_data = train_test_split(Temp_trin,test_size=0.2, random_state=42)
train_data.to_csv("/root/Jupyter/Data_cleaning/train_data.csv",index=False,header=True,encoding="utf-8")
valid_data.to_csv("/root/Jupyter/Data_cleaning/valid_data.csv",index=False,header=True,encoding="utf-8")
test_data.to_csv("/root/Jupyter/Data_cleaning/test_data.csv",index=False,header=True,encoding="utf-8")
查看划分训练集、验证集、测试集后的数据量大小
print(f'Number of training examples: {len(train_data)}')
print(f'Number of validation examples: {len(valid_data)}')
print(f'Number of testing examples: {len(test_data)}')

五.借助Torchtext建立vocabulary,把每个单词映射到数字id
1.创建Filed对象
import torch
import torchtext
from torchtext.data import TabularDataset
torch.backends.cudnn.deterministic = True #在程序刚开始加这条语句可以提升一点训练速度,没什么额外开销。
#首先,我们要创建两个Field 对象:这两个对象包含了我们打算如何预处理文本数据的信息。
#TEXT = data.Field(tokenize='spacy')#torchtext.data.Field : 用来定义字段的处理方法(文本字段,标签字段)
TEXT = torchtext.data.Field(sequential=True)
LABEL = torchtext.data.Field(sequential=False, dtype=torch.long, use_vocab=False)
2.使用TabularDataset方法生成数据集
读取文件生成数据集
fields = [ ('label', LABEL),('comment_processed',TEXT)]
train, valid,test = TabularDataset.splits(
path='/root/Jupyter/Data_cleaning/', format='csv',
train='train_data.csv',
validation = "valid_data.csv",
test='test_data.csv',
skip_header=True, fields=fields)
3.构建词表
构建词表
TEXT.build_vocab(train)
print(train[0].__dict__.keys())
print(vars(train.examples[0]))
print(vars(test.examples[0]))
#语料库单词频率越高,索引越靠前。前两个默认为unk和pad。
print(TEXT.vocab.stoi)
#查看训练数据集中最常见的单词。
print(TEXT.vocab.freqs.most_common(20))
print(TEXT.vocab.itos[:10]) #查看TEXT单词表


4.构建词嵌入矩阵
将词向量和词id进行对应构建矩阵,比如手机的词id为2,在构建的矩阵中,第二行对应的就是手机的词向量。整个矩阵的大小为8491*256,代表通过建立此表一共存在8491个词id,每个词向量的维度为256。
#生成词嵌入矩阵
import numpy as np
embedding_dic = dict(zip(model_w2v.wv.index2word, model_w2v.wv.vectors))
embedding_matrix = np.zeros((len(TEXT.vocab), 256))
for w, i in TEXT.vocab.stoi.items():
embedding_vec = embedding_dic.get(w)
if embedding_vec is not None:
embedding_matrix[i] = embedding_vec
print(embedding_matrix.shape)
六.创建Iterator,每个itartion都是返回一个batch的样本
- 最后一步数据的准备是创建iterators。每个itartion都会返回一个batch的examples。
- 我们会使用
BucketIterator。BucketIterator会把长度差不多的句子放到同一个batch中,确保每个batch中不出现太多的padding。
from torchtext.data import Iterator, BucketIterator
train_batch_size = 64
val_batch_size = 64
test_batch_size = 64
#相当于把样本划分batch,只是多做了一步,把相等长度的单词尽可能的划分到一个batch,不够长的就用padding。
同时对训练集和验证集进行迭代器构建
train_iterator, valid_iterator = BucketIterator.splits(
(train, valid),
batch_sizes=(train_batch_size, val_batch_size),
device=device,
sort_key=lambda x: len(x.comment_processed),
sort_within_batch=False,
repeat=False)
对测试集进行迭代器构建
test_iterator = Iterator(
test,
batch_size=test_batch_size,
device=device,
sort=False,
sort_within_batch=False,
repeat=False)
- 查看batch的信息。
- 查看通过Field格式化之后的文本。
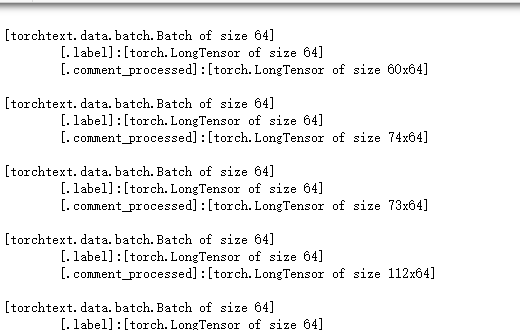
for batch in train_iterator:
print(batch)
{TEXT.vocab.itos[i] for i in batch.comment_processed[:,0]}

七.搭建神经网络,以Bi-LSTM为例
1.参数说明
embedding_dim:每个单词维度
hidden_size:隐藏层维度
num_layers:神经网络深度,纵向深度
bidirectional:是否双向循环
import torch.nn as nn
import torch.nn.functional as F
class LSTMmodel(nn.Module):
def __init__(self,embedding_size,hidden_size,output_size):
super(LSTMmodel,self).__init__()
self.embedding=nn.Embedding(len(TEXT.vocab),256)
self.lstm=nn.LSTM(embedding_size,hidden_size,num_layers=2,bidirectional=True)
self.fc=nn.Linear(hidden_size*2,output_size)
#向前传播
def forward(self,text):
embedded=self.embedding(text)
output,(hidden,c)=self.lstm(embedded)
#hidden的维度是(num_layers * num_directions, batch, hidden_size)取最后一层的前向和后向输出,[4,64,hidden_size]
h = torch.cat((hidden[-1, :, :], hidden[-2, :, :]), dim=1)
#print("h",h)
#print(h.shape)
output=self.fc(h)
return output
八.构建训练函数和验证函数
1.训练函数
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
total_len = 0
count = 0
model.train() #model.train()代表了训练模式
#这步一定要加,是为了区分model训练和测试的模式的。
#有时候训练时会用到dropout、归一化等方法,但是测试的时候不能用dropout等方法。
for batch in iterator: #iterator为train_iterator
optimizer.zero_grad() #加这步防止梯度叠加
predictions = model(batch.comment_processed)
#print("predictions",predictions)
#batch.comment_processed comment_processed
loss = criterion(predictions, batch.label)
epoch_loss += loss.item()
loss.backward() #反向传播
optimizer.step() #梯度下降
epoch_acc += ((predictions.argmax(axis = 1)) == batch.label).sum().item()
#(acc.item():一个batch的正确率) *batch数 = 正确数
#train_iterator所有batch的正确数累加。
total_len += len(batch.label)
#计算train_iterator所有样本的数量
count += 1
print(f'训练了{count}个batch')
return epoch_loss / total_len, epoch_acc / total_len
#epoch_loss / total_len :train_iterator所有batch的损失
#epoch_acc / total_len :train_iterator所有batch的正确率
2.验证函数
def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
total_len = 0
count = 0
model.eval()
#转换成测试模式,冻结dropout层或其他层。
with torch.no_grad():
for batch in iterator:
#iterator为valid_iterator
#没有反向传播和梯度下降
predictions = model(batch.comment_processed)
loss = criterion(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += ((predictions.argmax(axis = 1)) == batch.label).sum().item()
total_len += len(batch.label)
count += 1
model.train() #调回训练模式
print(f'验证了{count}个batch')
return epoch_loss / total_len, epoch_acc / total_len
九.初始化参数
1.设置超参数
#设置超参数
EMBEDDING_SIZE = 256
HIDDEN_SIZE = 128
OUTPUT_SIZE = 5
2.实例化模型
#实例化模型
model = LSTMmodel(embedding_size = EMBEDDING_SIZE,
hidden_size = HIDDEN_SIZE,
output_size = OUTPUT_SIZE,).to(device)
3.嵌入词向量
#模型词向量初始化成预训练的词向量
#from_munpy ndarray和tensor转换
#将生成的词向量-id矩阵嵌入到我们的网络模型中
model.embedding.weight.data.copy_(torch.from_numpy(embedding_matrix))[2:10]
4.统计模型参数
def count_parameters(model): #统计模型参数
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
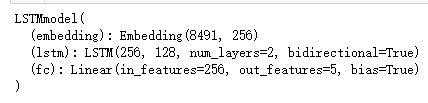
5.查看模型基础架构
#查看模型基础架构
print(model)
十.定义组件
1.定义优化器和损失函数
import torch.optim as optim
optimizer = optim.Adam(model.parameters()) #定义优化器
criterion = nn.CrossEntropyLoss() #定义损失函数,交叉熵损失函数
model = model.to(device) #送到gpu上去
criterion = criterion.to(device) #送到gpu上去
2.定义统计时间组件
import time
def epoch_time(start_time, end_time): #查看每个epoch的时间
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
十一.开始训练
定义训练10个轮次,并且保存效果最好的模型。
N_EPOCHS = 10
best_valid_loss = float('inf') #无穷大
for epoch in tqdm(range (N_EPOCHS),desc='Processing'):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss: #只要模型效果变好,就存模型
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'Best-Checkpoint.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')

十二. 读入模型
1.载入模型
#用保存的模型参数预测数据
model.load_state_dict(torch.load("Best-Checkpoint.pt"))
2.使用测试集测试结果
model.load_state_dict(torch.load('Best-Checkpoint.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
3.测试结果

十三.创建组件
1.建立组件将未知的句子转换成id进行预测
import spacy #分词工具,跟NLTK类似
nlp = spacy.load('zh_core_web_md')
def predict_sentiment(sentence):
tokenized = [tok.text for tok in nlp.tokenizer(sentence)]#分词
indexed = [TEXT.vocab.stoi[t] for t in tokenized]
#sentence的索引
tensor = torch.LongTensor(indexed).to(device) #seq_len
tensor = tensor.unsqueeze(1)
#seq_len * batch_size(1)
prediction = torch.sigmoid(model(tensor))
#tensor与text一样的tensor
#print(prediction)
#转换成numpy
#print(prediction.detach().numpy())
#直接取出numpy中最大的对应位置作为预测值
final_prediction = prediction.detach().numpy().argmax(axis = 1)
#return final_prediction
if final_prediction+1 >= 3:
print(f'手机评论:{sentence}的评价等级为{final_prediction+1}星好评')
else :
print(f'手机评论:{sentence}的评价等级为{final_prediction+1}星差评')
2.预测
predict_sentiment("手机不错,非常好用")
predict_sentiment("手机不好用,掉电严重,并且发烫严重")
3.查看预测结果
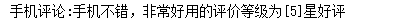
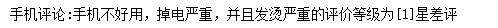
Original: https://blog.csdn.net/weixin_44750512/article/details/121922347
Author: DonngZH
Title: 深度学习进行情感分析(2)–LSTM
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/711090/
转载文章受原作者版权保护。转载请注明原作者出处!