

本文目的:将爬取的评论数据进行分词,然后使用词云图进行可视化操作。
使用到的工具:结巴中文分词、Wordcloud库
首先介绍一下两个工具,其中结巴中文分词是一个专门将中文句子进行分词的第三方库,当然还有其他的中文分词平台,使用比较多的是结巴中文分词。具体使用以及介绍详看平台的GitHub(https://github.com/fxsjy/jieba/)。目前英语分词比较方便,因为英语每一个单词本身都是有空格隔开的,但中文每个词没有隔开(每个句子有符号隔开),这就给中文分词带来很大的不便之处。相信未来会得到解决,对此感兴趣的可以尝试深挖这个行业。分词之后会带来一些无效的词汇,为了得到更加有效的分词结果,需要将无效的词汇删减,以便更有效的展示出结果。这里就带来了另一个问题,就是使用怎样的停用词汇。目前有”中文停用词汇”、”哈工大停用词汇”、”百度停用词汇”、”四川大学停用词汇”。这几种都是可以直接拿来使用的,但要是追求更好的结果可以自行设定一些停用词汇。本文将使用中文停用词汇。#中文停用词表#中文分词#-数据挖掘文档类资源-CSDN下载中文分词常见的停用词表更多下载资源、学习资料请访问CSDN下载频道. https://download.csdn.net/download/Tobe_01/84423742 ;
https://download.csdn.net/download/Tobe_01/84423742 ;
词云图可视化结果,词云图可视化结果相对平常的绘图显得更加酷炫一些,网上也有很多的平台可以进行绘制词云图,本文使用的是Wordcloud来绘制词云图。
(官方网站:WordCloud for Python documentation — wordcloud 1.8.1 documentation)
本身两个库的使用都比较简单,下面直接上代码,代码中有详细步骤解释。生成的词云图的形状是可以根据自己喜好来设定的,只需要添加图片,并设置成背景即可(如下面注释掉的几行代码所示)。为了简便,就不添加背景图片了。
import wordcloud # 分词
from wordcloud import WordCloud,ImageColorGenerator,STOPWORDS # 词云,颜色生成器,停止词
from PIL import Image # 处理图片
import pandas as pd
import numpy as np
def get_ciyun(data,n):
"""
绘制词云图的函数:data表示评论数据,n表示哪一天的日期。
其中函数会先创建一个TXT文件来保存评论数据,然后使用结巴进行分词,最后使用Wordcloud进行绘制词云图并保存。
"""
# 保存评论数据
for ele in data:
with open("3月{}号.txt".format(n),mode="a") as f:
f.write(ele.split("[")[0])
# 使用结巴进行分词
with open('3月{}号.txt'.format(n),'r',encoding='gbk') as f: #打开新的文本转码为gbk
textfile = f.read() #读取文本内容
seg_list = jieba.cut(textfile, cut_all=False)
space_list = ' '.join(seg_list) #空格链接词语
# backgroud = np.array(Image.open('LME.jpg')) # 添加想要的背景图片
# 制定停用词表
stop_words = set()
content = [line.strip() for line in open('中文停用词表.txt',mode="r",encoding='utf-8').readlines()]
stop_words.update(content)
# 绘制词云图
# backgroud = np.array(Image.open('LME.jpg'))
wc = WordCloud(width=400, height=600,background_color='white',mode='RGB', max_words=500,
font_path='‪C:\Windows\Fonts\SIMLI.TTF', # 字体路径,可以根据电脑字体路径进行更改
max_font_size=150,
relative_scaling=0.6, # 设置字体大小与词频的关联程度为0.4
random_state=50,
scale=3, # 设置字体清晰度,越大表示越清晰
stopwords=stop_words # 设置停用词表
).generate(space_list)
# image_color = ImageColorGenerator(backgroud) #设置生成词云的颜色,如去掉这两行则字体为默认颜色
# wc.recolor(color_func = image_color)
plt.imshow(wc) #显示词云
plt.axis('off') #关闭x,y轴
plt.show()#显示
wc.to_file('3月{}号_ciyun.jpg'.format(n)) #保存词云图
调用函数,会输出并且保存词云图.
get_ciyun(data,n)
本文绘制词云图使用的数据来源于国内财经网页的股吧评论,通过爬虫获得。下面的词云图展示的是3月7号当天的所有评论数据。可以发现最显眼的有”沪镍”、”ni2204″、”镍”等,因为爬取的股吧正是沪镍吧下面的评论数据,所以此类相关的词汇比较多。
此次事件缘由是因为国内一家民企青山集团经营所需,正常持有20万吨的空头期货(作为套期保值),但由于俄乌战争,使得俄方的镍被移出伦敦交易所,无法进入欧洲市场,导致镍的供应不足,镍价因此暴涨(两个交易日涨了248%,见下面走势图),当然也存在多头方从中作怪的可能。如果到期青山集团无法交出这么多镍的现货就只能以高价进行平仓,这必然会导致很大的损失。这是经典的”多逼空”案例。
从词云图中可以看到”沪镍”、”空头”、”ni2204″、”涨停”等字眼比较突出,这些字眼也正是整个事件最突出的部分,其中”沪镍”表示此次的交易场所为上海期货交易所的镍产品,而”ni2204″则是镍产品的交易代码。”空头”正是此次事件的核心,就是青山集团持有的空头期货,”涨停”反应则是镍价的走势。对比于文本类的数据,词云图在突出展示信息重要性方面还是存在优势的,一方面,可以更加简洁清晰的展示结果,另一方面能够突出数据的关键词,有利于更快速的定位事件的核心。除此之外,本文展示的只是3月7号当天的数据,从词云图中也可以看到一些”明天”的字眼,由于7号当天青山集团对此事件并没有做出回应,所以人们很关心明天,或者接下来青山集团会怎么应对此次的”多逼空”。
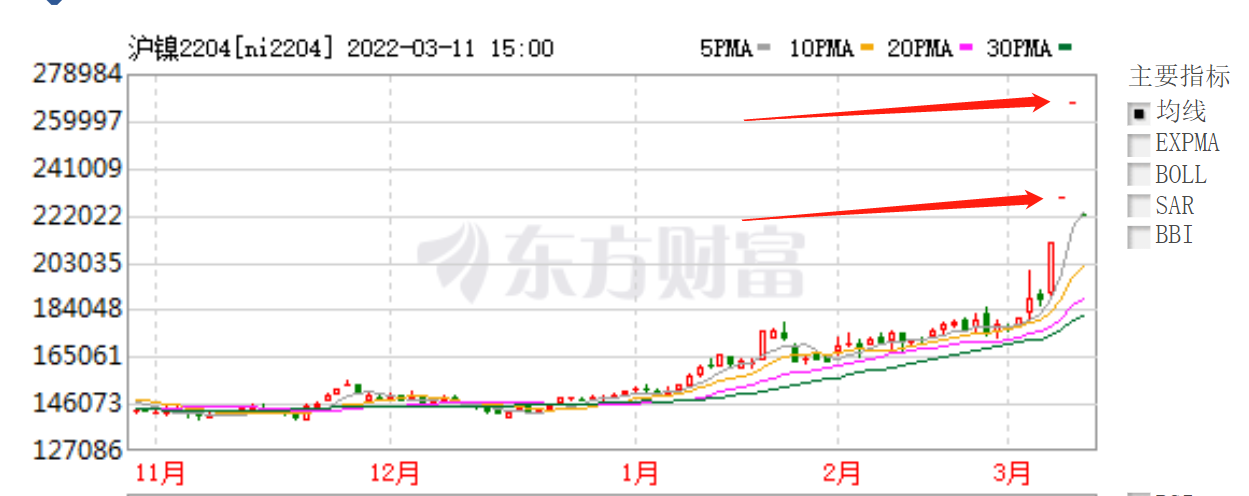
ni2204走势图

3月7号评论词云图
Original: https://blog.csdn.net/Tobe_01/article/details/123427047
Author: TobeZhu
Title: 数据可视化——词云图
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528670/
转载文章受原作者版权保护。转载请注明原作者出处!