

目录
前言
pivot官方文档:pyspark.sql.GroupedData.pivot
pivot的中文解释是机械装置转动或摆动的中心点。在关系表中,pivot做的就是转换行和列。
官方文档的描述为:”pivot当前DataFrame的一列并执行指定的聚合。”听起来难以理解,但是通过例子就可以很好地理解pivot到底做了什么操作。
实践理解
例子及pivot参数介绍
【例1】如下表,将A表为3个用户在不同时间戳下的不同类型的交互,现在想统计每个用户在A表中每种行为的次数,如表B(B表通常在作为训练特征的一个统计类因子,或作为用户偏好的一个预处理因子)。
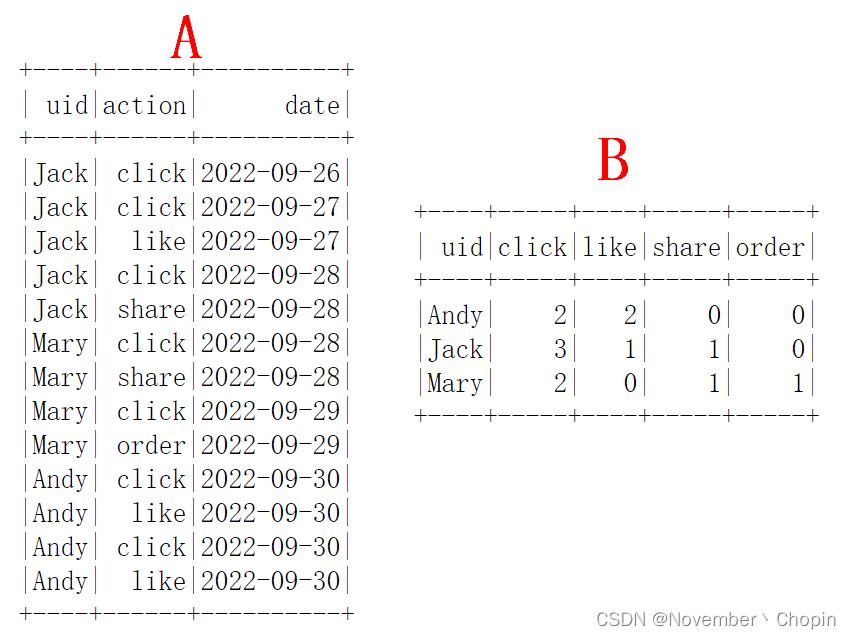

常规做法是,使用
groupby然后 case when过滤每个想要的行为。但使用 pivot就会方便很多。
pyspark.sql.GroupedData.pivot有两个参数:
- pivot_col:要被pivot的列名,如A表中的 action
- values:将要被转换为输出的DataFrame的列名列表。
我们以上述的【例1】为例,通过代码来看一下 pivot的用法及输出结果。
; 代码实践
- 首先,创建A的Spark DataFrame形式:
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
spark=SparkSession.builder.appName("wrs_20220926A").enableHiveSupport().getOrCreate()
sc = spark.sparkContext
mydict = dict()
mydict['uid'] = ['Jack','Jack','Jack','Jack','Jack',
'Mary','Mary',"Mary","Mary",
'Andy','Andy','Andy','Andy']
mydict['action'] = ['click','click','like','click','share',
'click','share','click',"order",
'click','like','click','like']
mydict['date'] = ["2022-09-26","2022-09-27","2022-09-27","2022-09-28","2022-09-28",
"2022-09-28","2022-09-28","2022-09-29","2022-09-29",
"2022-09-30","2022-09-30","2022-09-30","2022-09-30"]
df_A = spark.createDataFrame(pd.DataFrame(mydict))
dfA.show()可以查看A的内容。
+----+------+----------+
| uid|action| date|
+----+------+----------+
|Jack| click|2022-09-26|
|Jack| click|2022-09-27|
|Jack| like|2022-09-27|
|Jack| click|2022-09-28|
|Jack| share|2022-09-28|
|Mary| click|2022-09-28|
|Mary| share|2022-09-28|
|Mary| click|2022-09-29|
|Mary| order|2022-09-29|
|Andy| click|2022-09-30|
|Andy| like|2022-09-30|
|Andy| click|2022-09-30|
|Andy| like|2022-09-30|
+----+------+----------+
- 其次,进行pivot操作。因为我们在uid维度对action进行统计,因此需要先对uid进行groupby生成GroupData,然后调用pivot并传入相应参数生成想要的矩阵B:
df_B = df_A.groupby("uid") \
.pivot(pivot_col='action', values=['click', 'like', 'share', 'order']) \
.count().fillna(0)
dfB.show()可以查看B的内容。
+----+-----+----+-----+-----+
| uid|click|like|share|order|
+----+-----+----+-----+-----+
|Andy| 2| 2| 0| 0|
|Jack| 3| 1| 1| 0|
|Mary| 2| 0| 1| 1|
+----+-----+----+-----+-----+
注意,代码中使用了fillna,因为pivot对于没有值的元素,会填充null。
结尾语
至此,pyspark.sql.GroupedData.pivot的介绍已经结束,由于我的集群不支持SQL版本的pivot,因此在此出放了SQL Server的相应代码:SQL Server PIVOT
但是通过官方文档可以发现,最新版的spark3.0支持直接对DataFrame进行pivot操作,并配有相关demo,可以尝试学习一下。
■ \blacksquare ■
Original: https://blog.csdn.net/u012762410/article/details/127048557
Author: November丶Chopin
Title: PySpark和SQL中的pivot 最佳实践
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/676822/
转载文章受原作者版权保护。转载请注明原作者出处!