

文章目录
*
– 1 模型介绍
– 2 模型结构
– 3 模型创新
– 4 Pytorch模型搭建
1 模型介绍
2012年,A l e x K r i z h e v s k y Alex Krizhevsky A l e x K r i z h e v s k y、I l y a S u t s k e v e r Ilya Sutskever I l y a S u t s k e v e r在多伦多大学Geoff Hinton的实验室设计出了一个深层的卷积神经网络AlexNet,夺得了2012年ImageNet LSVRC的冠军,且准确率远超第二名(top5错误率为15.3%,第二名为26.2%),引起了很大的轰动。AlexNet可以说是具有历史意义的一个网络结构。
2 模型结构
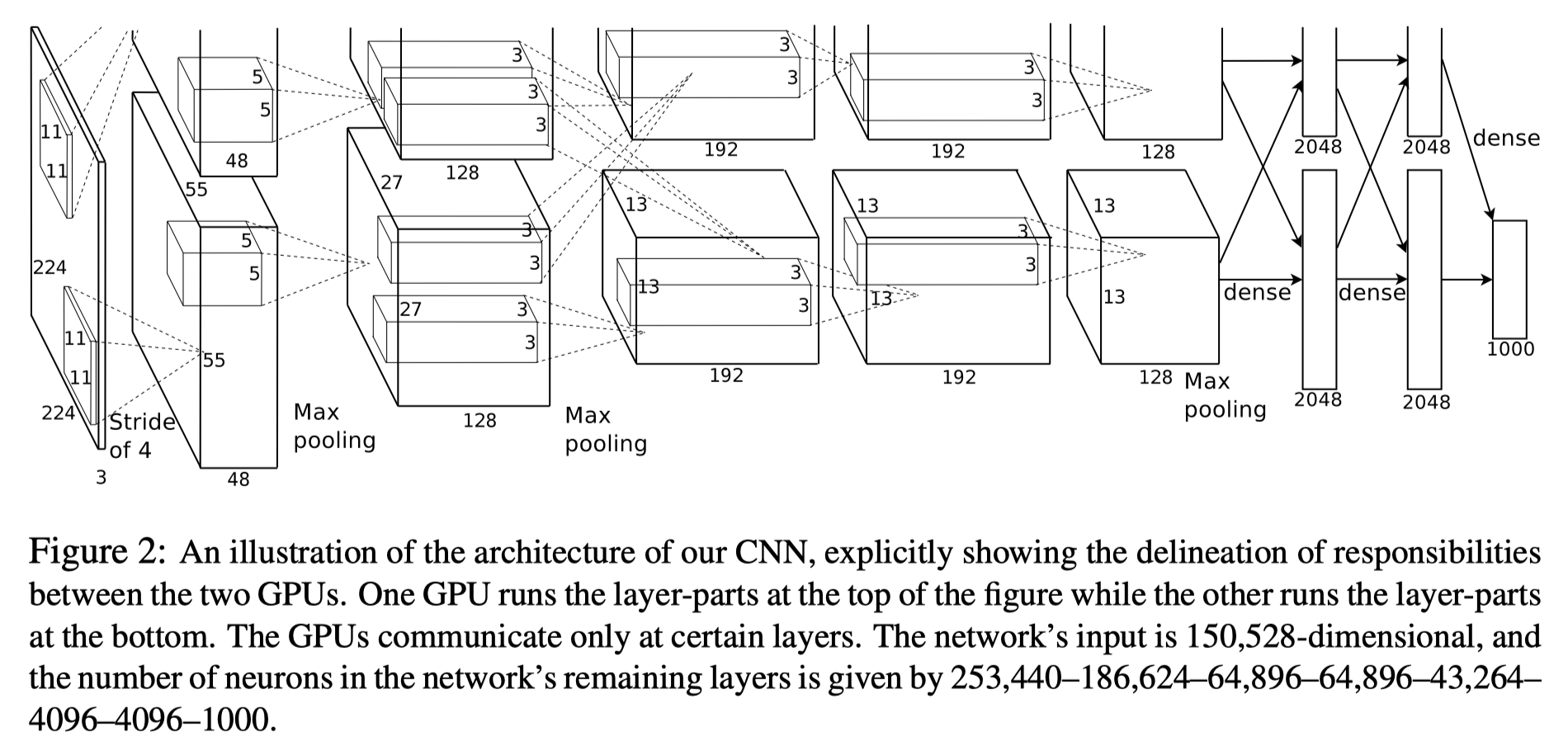

Layer NameKernel SizeKernel NumStridePaddingInput SizeOutput SizeConv1
11 × 11 11\times11 1 1 ×1 1 48 ( × 2 G P U ) 48(\times2_{GPU})4 8 (×2 G P U )4 4 4 [ 1 , 2 ] [1,2][1 ,2 ]224 × 224 × 3 224\times224\times3 2 2 4 ×2 2 4 ×3 55 × 55 × 96 55\times55\times96 5 5 ×5 5 ×9 6
Maxpool1
3 × 3 3\times3 3 ×3 / //2 2 2 0 0 0 55 × 55 × 96 55\times55\times96 5 5 ×5 5 ×9 6 27 × 27 × 96 27\times27\times96 2 7 ×2 7 ×9 6
Conv2
5 × 5 5\times5 5 ×5 128 ( × 2 G P U ) 128(\times2_{GPU})1 2 8 (×2 G P U )1 1 1 [ 2 , 2 ] [2,2][2 ,2 ]27 × 27 × 96 27\times27\times96 2 7 ×2 7 ×9 6 27 × 27 × 256 27\times27\times256 2 7 ×2 7 ×2 5 6
Maxpool2
3 × 3 3\times3 3 ×3 / //2 2 2 0 0 0 27 × 27 × 256 27\times27\times256 2 7 ×2 7 ×2 5 6 13 × 13 × 256 13\times13\times256 1 3 ×1 3 ×2 5 6
Conv3
3 × 3 3\times3 3 ×3 192 ( × 2 G P U ) 192(\times2_{GPU})1 9 2 (×2 G P U )1 1 1 [ 1 , 1 ] [1,1][1 ,1 ]13 × 13 × 256 13\times13\times256 1 3 ×1 3 ×2 5 6 13 × 13 × 384 13\times13\times384 1 3 ×1 3 ×3 8 4
Conv4
3 × 3 3\times3 3 ×3 192 ( × 2 G P U ) 192(\times2_{GPU})1 9 2 (×2 G P U )1 1 1 [ 1 , 1 ] [1,1][1 ,1 ]13 × 13 × 384 13\times13\times384 1 3 ×1 3 ×3 8 4 13 × 13 × 384 13\times13\times384 1 3 ×1 3 ×3 8 4
Conv5
3 × 3 3\times3 3 ×3 128 ( × 2 G P U ) 128(\times2_{GPU})1 2 8 (×2 G P U )1 1 1 [ 1 , 1 ] [1,1][1 ,1 ]13 × 13 × 384 13\times13\times384 1 3 ×1 3 ×3 8 4 13 × 13 × 256 13\times13\times256 1 3 ×1 3 ×2 5 6
Maxpool3
3 × 3 3\times3 3 ×3 / //2 2 2 0 0 0 13 × 13 × 256 13\times13\times256 1 3 ×1 3 ×2 5 6 6 × 6 × 256 6\times6\times256 6 ×6 ×2 5 6
FC1
2048 2048 2 0 4 8 / /// /// //6 × 6 × 256 6\times6\times256 6 ×6 ×2 5 6
4096FC2
2048 2048 2 0 4 8 / /// /// //
40964096FC3
1000 1000 1 0 0 0 / /// /// //
40961000
为了简化网络结构,将作者原论文中的在两个GPU上的并行结构合并,接下来我们对AlexNet的每一层作详细的分析。
1、Conv1: kernels:48×2=96;kernel_size:11;padding:[1, 2] ;stride:4
卷积层1输入的尺寸为224×224,卷积核的数量为96,论文中两片GPU分别计算48个核; 卷积核的大小为 11 × 11 × 3 ;卷积核步距stride = 4;padding=[1, 2]表示在原输入图像上左侧补一列0,右侧2列0,上侧一行0,下侧2行0。
输出feature map的尺寸为:N = (W − F + 2P ) / S + 1 = [ 224 – 11 + (1 + 2)] / 4 + 1 = 55
2、Maxpool1: kernel_size:3;pading:0;stride:2
卷积层Conv1之后接着进行了局部响应规范化操作( Local Response Normalized),将规范化的结果送入大小为3 × 3 3\times3 3 ×3,步距为2的池化核进行最大池化下采样。
输出的feature map尺寸为:N = (W − F + 2P ) / S + 1 = (55 – 3) / 2 + 1 = 27
3、Conv2: kernels:128×2=256; kernel_size:5; padding: [2, 2]; stride:1
卷积层2使用256个卷积核做常规的卷积操作
输出的feature map尺寸为:N = (W − F + 2P ) / S + 1 = (27 – 5 + 4) / 1 + 1 = 27
4、Maxpool2: kernel_size:3; pading:0; stride:2
与下采样层Conv2类似,在上述卷积层之后接着进行了局部响应规范化操作,然后将结果送入大小为3 × 3 3\times3 3 ×3,步距为2的池化核进行最大池化下采样。
输出的feature map尺寸为:N = (W − F + 2P ) / S + 1 = (27 – 3) / 2 + 1 = 13
5、Conv3: kernels:192×2=384; kernel_size:3; padding: [1, 1]; stride:1
与Conv1和Conv2不同,Conv3、Conv4、Conv5后均不接局部响应归一化LRN层
输出的feature map尺寸为:N = (W − F + 2P ) / S + 1 = (13 – 3 + 2) / 1 + 1 = 13
6、Conv4: kernels:192×2=384; kernel_size:3; padding: [1, 1]; stride:1
输出的feature map尺寸为:N = (W − F + 2P ) / S + 1 = (13 – 3 + 2) / 1 + 1 = 13
7、Conv5: kernels:128×2=256; kernel_size:3; padding: [1, 1]; stride:1
输出的feature map尺寸为:N = (W − F + 2P ) / S + 1 = (13 – 3 + 2) / 1 + 1 = 13
8、Maxpool3: kernel_size:3 padding: 0 stride:2
输出的feature map尺寸为:N = (W − F + 2P ) / S + 1 = (13 – 3) / 2 + 1 = 6
9、全连接层FC1、FC2、FC3
FC1和FC2分别有4096个神经元,FC3输出softmax为1000个(ImageNet数据集分类类别)。
; 3 模型创新
1、使用ReLU作为激活函数代替了传统的Sigmoid和Tanh
ReLU为非饱和函数,论文中验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。
2、在多个GPU上进行模型的训练,不但可以提高模型的训练速度,还能提升数据的使用规模
3、使用LRN对局部的特征进行归一化
结果作为ReLU激活函数的输入能有效降低错误率
4、使用随机丢弃技术(dropout)选择性地忽略训练中的单个神经元
在AlexNet的最后几个全连接层中使用了Dropout来避免模型的过拟合
5、重叠最大池化(overlapping max pooling)
即池化范围z与步长s存在关系z > s z>s z >s(如最大池化下采样中核大小为3 × 3 3\times3 3 ×3,步距为2),避免平均池化(average pooling)的平均效应
4 Pytorch模型搭建
注:由于LRN层对训练结果影响不大,故代码中去除了LRN层
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(256 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.2),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes)
)
def forward(self, inputs):
x = self.features(inputs)
x = torch.flatten(x, start_dim=1)
outputs = self.classifier(x)
return outputs
Original: https://blog.csdn.net/weixin_44772440/article/details/122766653
Author: 红鲤鱼与绿驴
Title: AlexNet网络详解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/690904/
转载文章受原作者版权保护。转载请注明原作者出处!