

一、背景
文本处理是许多ML应用程序中最常见的任务之一。以下是此类应用的一些示例
- 语言翻译:将句子从一种语言翻译成另一种语言
- 情绪分析:从文本语料库中确定对任何主题或产品等的情绪是积极的、消极的还是中性的
- 垃圾邮件过滤:检测未经请求和不需要的电子邮件/消息。
这些应用程序处理大量文本以执行分类或翻译,并且涉及大量后端工作。将文本转换为算法可以消化的内容是一个复杂的过程。在本文中,我们将讨论文本处理中涉及的步骤。
二、数据预处理
- 分词——将句子转化为词语
- 去除多余的标点符号
- 去除停用词——高频出现的”的、了”之类的词,他们对语义分析没帮助
- 词干提取——通过删除不必要的字符(通常是后缀),将单词缩减为词根。
- 词形还原——通过确定词性并利用语言的详细数据库来消除屈折变化的另一种方法。
我们可以使用python进行许多文本预处理操作。
NLTK(Natural Language Toolkit),自然语言处理工具包,在NLP(自然语言处理)领域中,最常使用的一个Python库。自带语料库,词性分类库。自带分类,分词功能。
分词(Tokenize):word_tokenize生成一个词的列表
import nltk
sentence="I Love China !"
tokens=nltk.word_tokenize(sentence)
tokens
[‘I’, ‘Love’, ‘China’, ‘!’]
中文分词–jieba
>>> import jieba
>>> seg_list=jieba.cut("我正在学习机器学习",cut_all=True)
>>> print("全模式:","/".join(seg_list))
全模式: 我/正在/学习/学习机/机器/学习
>>> seg_list=jieba.cut("我正在学习机器学习",cut_all=False)
>>> print("精确模式:","/".join(seg_list))
精确模式: 我/正在/学习/机器/学习
三、特征提取
在文本处理中,文本中的单词表示离散的、分类的特征。我们如何以算法可以使用的方式对这些数据进行编码?从文本数据到实值向量的映射称为特征提取。用数字表示文本的最简单的技术之一是 Bag of Words。
Bag of Words
我们在文本语料库中列出一些独特的单词,称为词汇表。然后我们可以将每个句子或文档表示为一个向量,每个单词表示为1表示现在,0表示不在词汇表中。另一种表示法是计算每个单词在文档中出现的次数。最流行的方法是使用术语频率逆文档频率( TF-IDF)技术。
- Term Frequency (TF)=(术语t出现在•文档中的次数)/(文档中的术语数量)
- Inverse Document Frequency (IDF)=log(N/n),其中,N是文档数量,n是术语t出现在文档中的数量。稀有词的IDF较高,而频繁词的IDF可能较低。因此具有突出显示不同单词的效果。
- 我们计算一个项的 TF-IDF值为=TF*IDF


TF('beautiful',Document1) = 2/10, IDF('beautiful')=log(2/2) = 0
TF(‘day’,Document1) = 5/10, IDF(‘day’)=log(2/1) = 0.30
TF-IDF(‘beautiful’, Document1) = (2/10)*0 = 0
TF-IDF(‘day’, Document1) = (5/10)*0.30 = 0.15
正如您在Document1中看到的,TF-IDF方法严重惩罚了”beautiful”一词,但对”day”赋予了更大的权重。这是由于IDF部分,它为不同的单词赋予了更多的权重。换句话说,从整个语料库的上下文来看,”day”是Document1的一个重要词。Python scikit学习库为文本数据挖掘提供了有效的工具,并提供了计算给定文本语料库的文本词汇表TF-IDF的函数。
使用BOW的一个主要缺点是它放弃了词序,从而忽略了上下文,进而忽略了文档中单词的含义。对于自然语言处理(NLP),保持单词的上下文是至关重要的。为了解决这个问题,我们使用另一种称为单词嵌入的方法。
Word Embedding
它是文本的一种表示形式,其中具有相同含义的单词具有相似的表示形式。换句话说,它表示坐标系中的单词,在坐标系中,基于关系语料库的相关单词被放在更近的位置。
Word2Vec
Word2vec将大量文本作为输入,并生成一个向量空间,每个唯一的单词在该空间中分配一个对应的向量。词向量定位在向量空间中,使得在语料库中共享公共上下文的词在该空间中彼此非常接近。Word2Vec非常擅长捕捉意义,并在诸如计算a到b的类比问题以及c到?的类比问题等任务中演示它?。例如,男人对女人就像叔叔对女人一样?(a)使用基于余弦距离的简单矢量偏移方法。例如,这里有三个单词对的向量偏移量来说明性别关系:

这种向量组合也让我们回答”国王-男人+女人=?”提问并得出结果”女王”!当你认为所有这些知识仅仅来自于在上下文中查看大量单词,而没有提供关于它们的语义的其他信息时,所有这些都是非常值得注意的。
; Glove
单词表示的全局向量(GloVe)算法是word2vec方法的扩展,用于有效学习单词向量。glove使用整个文本语料库中的统计信息构建一个显式的单词上下文或单词共现矩阵。结果是一个学习模型,可能会导致更好的单词嵌入。
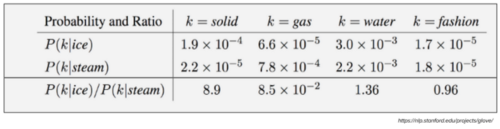
Target words: ice, steam
Probe words: solid, gas, water, fashion
让P(k | w)是单词k出现在单词W的上下文中的概率W.考虑一个与ice有密切关系的词,而不是与steam有关的词,例如solid。P(solid | ice)相对较高,P(solid | steam)相对较低。因此,P(solid | ice)/ P(solid | steam)的比率将很大。如果我们用一个词,比如气体,它与steam有关,但与ice无关,那么P(gas | ice) / P(gas | steam) 的比值就会变小。对于一个既与ice有关又与water有关的词,例如water,我们预计其比率接近1。
单词嵌入将每个单词编码成一个向量,该向量捕获文本语料库中单词之间的某种关系和相似性。这意味着即使是大小写、拼写、标点符号等单词的变体也会自动学习。反过来,这意味着可能不再需要上述一些文本清理步骤。
四、电影评论情感分析实例
根据问题空间和可用数据的不同,有多种方法为各种基于文本的应用程序构建ML模型。
用于垃圾邮件过滤的经典ML方法,如”朴素贝叶斯”或”支持向量机”,已被广泛使用。深度学习技术对于自然语言处理问题(如情感分析和语言翻译)有更好的效果。深度学习模型的训练速度非常慢,并且可以看出,对于简单的文本分类问题,经典的ML方法也能以更快的训练时间给出类似的结果。
让我们使用目前讨论的技术在Kaggle提供的烂番茄电影评论数据集上构建一个情感分析器。
电影评论情感分析

对于电影评论情绪分析,我们将使用Kaggle提供的烂番茄电影评论数据集。在这里,我们根据电影评论的情绪,以五个值为尺度给短语贴上标签:消极的,有些消极的,中性的,有些积极的,积极的。数据集由选项卡分隔的文件组成,其中包含来自数据集的短语ID。每个短语都有一个短语。每个句子都有一个句子ID。重复的短语(如短/常用词)仅在数据中包含一次。情绪标签包括:
- 0 – negative
- 1 – somewhat negative
- 2 – neutral
- 3 – somewhat positive
- 4 – positive
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
1. 初始化数据
df_train = pd.read_csv("/Users/gawaintan/workSpace/movie-review-sentiment-analysis-kernels-only/train.tsv", sep='\t')
df_train.head()
PhraseIdSentenceIdPhraseSentiment011A series of escapades demonstrating the adage …1121A series of escapades demonstrating the adage …2231A series2341A2451series2
df_test = pd.read_csv("/Users/gawaintan/workSpace/movie-review-sentiment-analysis-kernels-only/test.tsv", sep='\t')
df_test.head()
PhraseIdSentenceIdPhrase01560618545An intermittently pleasing but mostly routine …11560628545An intermittently pleasing but mostly routine …21560638545An31560648545intermittently pleasing but mostly routine effort41560658545intermittently pleasing but mostly routine
1.1 每个情绪类别中的评论分布
在这里,训练数据集包含了电影评论中占主导地位的中性短语,然后是有些积极的,然后是有些消极的。
df_train.Sentiment.value_counts()
2 79582
3 32927
1 27273
4 9206
0 7072
Name: Sentiment, dtype: int64
df_train.info()
<class 'pandas.core.frame.dataframe'>
RangeIndex: 156060 entries, 0 to 156059
Data columns (total 4 columns):
# Column Non-Null Count Dtype
Accuracy: 0.6369
Precision: 0.6177
Recall: 0.6369
F1 Score: 0.6132
Model Classification report:
Predicted:
0 1 2 3 4
Actual: 0 393 626 349 53 5
1 251 1967 2936 255 19
2 57 862 13982 1031 63
3 15 236 3023 2941 388
4 1 23 253 888 595
2.3.2 基于 TF-IDF 特征的逻辑回归模型
lr_tfidf_predictions = train_predict_model(classifier=lr,
train_features=tv_train_features, train_labels=sentiments_train,
test_features=tv_test_features, test_labels=sentiments_test)
display_model_performance_metrics(true_labels=sentiments_test, predicted_labels=lr_tfidf_predictions,
classes=[0,1,2,3,4])
Model Performance metrics:
precision recall f1-score support
0 0.60 0.22 0.32 1426
1 0.56 0.38 0.45 5428
2 0.67 0.89 0.77 15995
3 0.60 0.47 0.53 6603
4 0.60 0.29 0.39 1760
accuracy 0.65 31212
macro avg 0.61 0.45 0.49 31212
weighted avg 0.63 0.65 0.62 31212
Prediction Confusion Matrix:
Accuracy: 0.5988
Precision: 0.5776
Recall: 0.5988
F1 Score: 0.5455
Model Classification report:
Predicted:
0 1 2 3 4
Actual: 0 332 392 646 49 7
1 234 1025 3909 230 30
2 56 371 14874 637 57
3 18 106 4156 1956 367
4 4 15 502 735 504
2.3.4 基于TF-IDF的SGD模型
sgd_tfidf_predictions = train_predict_model(classifier=sgd,
train_features=tv_train_features, train_labels=sentiments_train,
test_features=tv_test_features, test_labels=sentiments_test)
display_model_performance_metrics(true_labels=sentiments_test, predicted_labels=sgd_tfidf_predictions,
classes=[0,1,2,3,4])
Model Performance metrics:
precision recall f1-score support
0 0.60 0.11 0.18 1426
1 0.52 0.09 0.16 5428
2 0.56 0.97 0.71 15995
3 0.55 0.16 0.25 6603
4 0.59 0.15 0.24 1760
accuracy 0.56 31212
macro avg 0.56 0.30 0.31 31212
weighted avg 0.55 0.56 0.47 31212
Prediction Confusion Matrix:
Accuracy: 0.6423
Precision: 0.6267
Recall: 0.6423
F1 Score: 0.6274
Model Classification report:
Predicted:
0 1 2 3 4
Actual: 0 520 605 283 17 1
1 465 2281 2539 133 10
2 101 1094 13479 1258 63
3 8 115 2793 3057 630
4 2 6 217 825 710
基于TF-IDF的逻辑回归模型优于其他机器学习算法.
Original: https://blog.csdn.net/GawainTky/article/details/121693126
Author: GawainTky
Title: 机器学习-文本处理之电影评论多分类情感分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528212/
转载文章受原作者版权保护。转载请注明原作者出处!