

Transformer中的encoder和decoder在训练和推理过程中究竟是如何工作的
苦苦冲浪,找不到答案
之前学习transformer的时候就不是很理解encoder和decoder在训练和推理过程中是如何工作的,四处查询也没有讲的很详细,很多文章和视频都是encoder讲很多,到了decoder就一带而过了,后来在b站看了大佬讲解的transformer源码,终于明白了encoder和decoder是怎么工作的了,怕自己再忘记,现记录一下。
Transformer结构(随便冲浪均可查到)
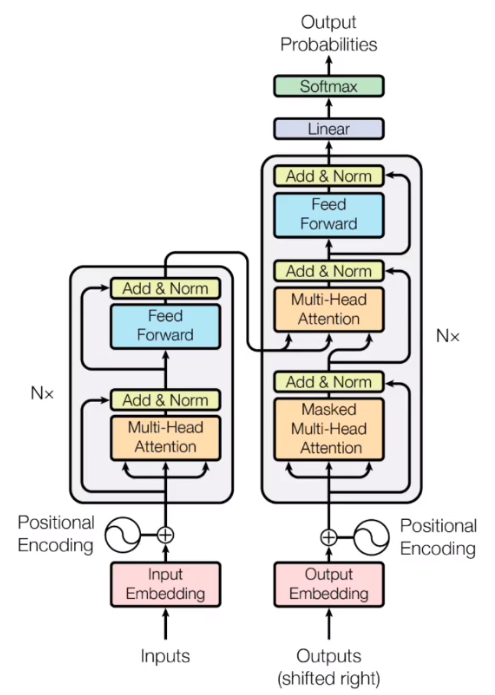

Input Embedding和Positional Encoding之类大家都在讲的部分就不多做介绍了,这里着重讲一下transformer在机器翻译的推理和训练时是如何工作的。
; Transformer推理过程
以”我爱你”到”I love you”为例,对于transformer来讲,在翻译”我爱你”这句话时,先将其进行embedding和encoding送入encoder(包含n层encoder layers),encoder layer之间完全是串联关系,最终在第n层encoder layer得到k,v。
对于decoder来讲,t0时刻先输入起始符(S),通过n层decoder layer(均计算masked自注意力与交互注意力(由decoder得到的q与encoder输出的k,v计算)),最终在第n层decoder layer得到当前的预测结果projection(可以理解成”I love you”中的”I”);在t1时刻,将t0时刻得到的输出”I”输入至decoder,重复t0的过程(计算masked自注意力与交互注意力),最终在第n层decoder layer得到输出”love”。最后经过多次计算,得到完整输出结果”I love you E”(E为终止符,由”you”输入decoder得到)
Transformer训练过程
仍以”我爱你”到”I love you”为例,在训练过程中,encoder输入的是待翻译句子”我爱你”,得到k,v;decoder输入的是”S I love you”(S位起始符);最终计算loss的label是”I love you E”。
这里就有一个很多人都不仔细讲的事情了,那就是decoder中计算自注意力的mask究竟是怎么工作的,都说mask是为了在输入当前字时,模型看不到后面的字(比如输入”I”时,看不到”love you”),但很少讲在训练中究竟是怎么实现的。所谓的mask其实就是一个上斜为1的矩阵,如下图所示
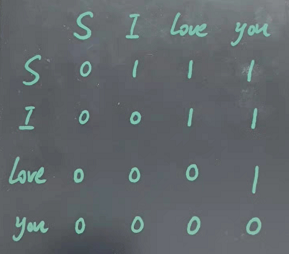
对于mask,0为可以看到的字,1为看不到的字。在此具体问题中,当计算自注意力的字是S时,就看不到后面的”I”,”love”,”you”;计算z自注意力的字时”I”时,就看不到后面的”love”,”you”,以此类推。
那么这个mask究竟是怎么用的呢?这就又涉及到一个transformer的基础知识:由q、k、v计算注意力attention,计算公式很经典了,如下所示
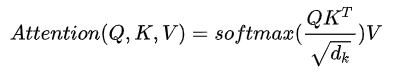
softmax公式
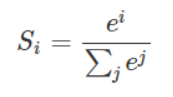
对于decoder中的交互注意力来讲,q,k,v均来自decoder输入的一整段话。我们可以看到,在由q,k相乘结果再与v相乘前,先对qkT进行了softmax计算,那么在进行softmax前,mask就发挥作用了,decoder会根据mask将对应位置的值设置为无穷小,这样在计算softmax时,会使其失去作用(趋近于0),进而在与v相乘时,也就忽略了v中对应的”love”和”you”的部分。
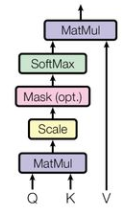
以”S I love you”为例,如果我们想对”I”求交互注意力,那么我们应该让此时的注意力机制看不到后面的”love”和”you”,此时对应了上文中mask矩阵的第二行,即让”love”和”you”在qkt中对应的值置为无穷小,这样在做softmax的时候,就可以忽略”love”和”you”的作用,也就是在一定程度上实现了”看不到”后面的”love”和”you”的作用
以上就是decoder在训练过程中,mask所起到的作用,最后decoder得到预测输出,与label的”I love you E”计算loss,使得其输出逼近label,最终得到训练好的模型。
Original: https://blog.csdn.net/qq_42599237/article/details/123383691
Author: Taskey
Title: Transformer中的encoder和decoder在训练和推理过程中究竟是如何工作的
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/527441/
转载文章受原作者版权保护。转载请注明原作者出处!