



扫码关注”自然语言处理与算法”公众号,定期更新NLP知识,还可以撩博主哦~
该文来自EMNLP2020。
论文简介:
事件抽取一般需要检测事件触发器(event trigger) 并抽取其对应的参数。现有的事件参数抽取方法严重依赖于实体识别的结果,由此引入错误传播问题。为了避免这个问题,文章引入了一种新的事件抽取范式,将事件抽取描述为一个问答(QA)任务,以端到端方式抽取事件参数。实验结果表明,该文章框架在很大程度上优于以往的方法;另外,该框架的一个额外能力是支持零样本学习(zero-shot learning),即使训练时没有看到角色也能够提取事件参数!
论文代码:https://github.com/xinyadu/eeqa
论文地址:https://arxiv.org/abs/2004.13625
; 1.方法
文章分析了以往事件抽取研究工作的缺陷:
(1) 过于依赖实体识别。以往的工作通常采用以下形式进行事件抽取:trigger detection → entity recognition → argument role assignment。这种处理方式会出现错误传播问题。
(2) 忽略了不同论元角色之间的语义相似性。例如,在ACE2005数据集中,CONFLICT->ATTACK事件和JUSTICE->EXECUTE事件中的论元角色均指human being (who) is affected by an action.(某人被袭击了)。论文指出,如果不考虑论元角色之间的相似性会给模型的识别效果造成影响,尤其是对少样本(few shot)数据而言。

该文提出了一个端到端模型,将事件抽取建模为问答/阅读理解任务。为触发词抽取和论元抽取均设置了问题模板(question templates),在具体处理时,将事件抽取作为一个两阶段的任务。第一阶段,利用预先设定的触发词问题模板,识别文本中的触发词;第二阶段,利用预先设定的论元抽取模板识别论元。触发词识别和事件论元抽取的输入均采用以下方式:
[CLS] question [SEP] sentence [SEP]
该文针对ACE2005数据集预先设定了4中触发词问题模板:
“what is the trigger”, “trigger”, “action”, “verb”
。在具体操作时,可能是随机选取的(文中未说明哪类触发词使用哪种模板,这里是博主猜测~)。
如果对于给定的样本选取”verb”作为触发词抽取的模板,则模型的输入会是下面这种形式(以此类推~):
[CLS] verb [SEP] sentence [SEP]
针对论元抽取的问题模板有3类,如下图所示:

第一类:仅用论元名称作为question。如”Artifact”、”Agent”等,这种很简单。
第二类:在第一类基础上进行了扩展,具体扩展策略采用以下模式:
[wh_word] is the [argument] ?
比如这里的wh_word,who for person、where for place、what for other。
argument与Template1相同。
除此之外,作者在第三类问题模板的基础上增加了触发词,即下面这种形式:
[wh_word] is the [argument] in [trigger]?
这是将能用到的信息都加进来了呀~~,够猛
这3类问题模板层层递进,以question的形式给模型引入更多、更精确的先验(语义)信息,让模型更清楚自己需要找什么。而这也是QA/MRC模型的优势。
2.模型介绍
在Figure2所示的架构中,作者分别使用 BERT_QA_Trigger模型和 BERT_QA_Arg进行触发词识别和论元识别。
在触发词识别模型中,采用BERT+softmax结构 以序列标注形式识别触发词。
在论元识别模型中,采用BERT+softmax结构 以阅读理解形式识别论元,模型会预测出论元在原始文本序列中的起始位置(start-end position),通过这个起始位置能够提取出相应的论元字段。
从模型结构来讲,该文的确很简单,博主认为该文的价值体现在 端到端的思路以及 针对触发词抽取和论元抽取设定的问题模板。不过该文说这是头一次将QA/MRC思路应用于事件抽取,博主不敢苟同,因为CCKS2019的事件抽取评测比赛上top选手的已经采用了QA/MRC方式,只不过这些国外的盆友看不到我国打工人的智慧罢了【手动滑稽】~~
有想要CCKS2019、2020评测论文的同学可以留言,我上传网盘分享一下~
言归正传,既然是端到端模型,那么在训练的时候肯定是sum loss,也就是将两部分(触发词识别和论元识别)的损失求和,然后将其最小化。
3.实验

单从实验结果来看,的确SOTA了,优秀~,不过触发词识别F1也只是达到了72.39,论元抽取目前的最高也只有53.31,各位打工人继续努力,继续刷榜。
前不久CCL2020的会议上出现一篇以阅读理解方式做事件论元抽取的论文,那篇文章是针对中文数据集来做的,同样具有不错的借鉴意义,有兴趣的同学去找下看看咯~
上面介绍了那么多问题模板,那么哪种模板对模型识别效果最有效呢~?
作者对此进行了实验分析,如下图:
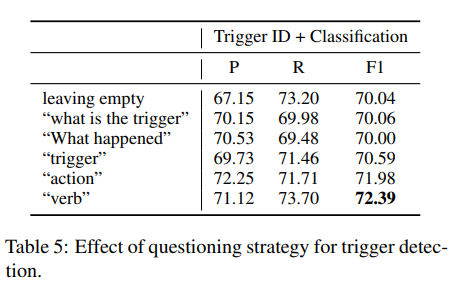
实验结果表明,在触发词识别模型中,使用”verb”这个词作为question是最有效的,博主以为会是第2、3种,可能是因为触发词大多是动词(verb)。

在论元识别中那个模板最有效呢?由上图可以看出, Template3 question + in [Trigger] 形式是效果最好的,因为Template3对argument role name的描述更详细、更精确,也就是为模型提供了更准确的 先验信息。
作者在论文中进行了Error Analysis,有兴趣的同学去看下咯~
文章的最后给出了论元抽取的问题模板,这里给各位看官展示一下,大家可以根据自己特定的任务设定相似的问题模板~



Original: https://blog.csdn.net/broccoli2/article/details/109964284
Author: 西兰先森
Title: 论文浅尝-Event Extraction by Answering (Almost) Natural Questions
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/557954/
转载文章受原作者版权保护。转载请注明原作者出处!