

通过DF,Spark可以跟大量各型的数据源(文件/数据库/大数据)进行交互。前面我们已经看到DF可以生成视图,这就是一个非常使用的功能。
简单的读写流程如下:


通过read方法拿到DataFrameReader对象,与之类似的就有DataFrameWriter对象,通过DF的write方法拿到,通过其save方法将数据保存到文件或数据库。
Spark官方列出的支持的数据格式有:
- parquet,这是Apache的一种序列化格式,我没有用过
- json
- text
- csv,逗号或其他分隔符分割的text
- orc,也是apache的一种数据格式,没有用过
- avro,也是apache的一种数据格式,没有用过
- JDBC,spark也是Java的,支持jdbc数据源天经地义
- Hive,它本来就干这个的
我们来尝试几个例子。
JSON
我们的json文件还是之前那种不规范格式,我期望读到DF后能变成规范的格式:
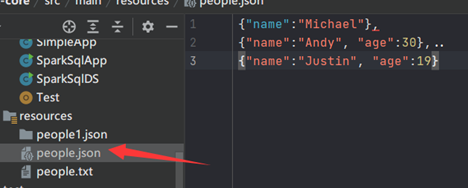
- Dataset
- json.show();
- json.write().save(“spark-core/src/main/resources/people.json”);
此执行将报告一个错误,指出该文件已存在。
[En]
This execution will report an error saying that the file already exists.

于是换一个文件people1.json,这样会生成一个文件夹people1.json,而任务报错:

到https://github.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin 下载hadoop.dll到hadoop的bin目录,执行了一下倒是没报错(看来只是win系统的原因,linux应该不报错吧),产生了一个文件夹:
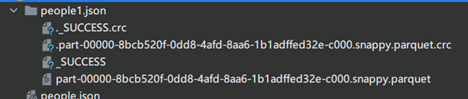
真奇怪,为什么spark非要使用parquet呢?可这样保存了该咋用呢?
parquet
根据 Parquet Files – Spark 3.2.0 Documentation (apache.org) 的说明,Parquet是apache的一款列式存储数据文件。spark会自动解析它的格式(有哪些字段),并把每一列都作为可空的。主要还是在hadoop相关的环境下使用。
上面生成的parquet文件时可以直接读取的。和读取json文件一样,spark提供了parquet()方法:
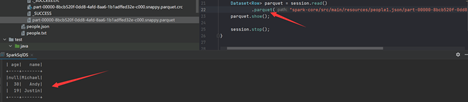
除了save方法,spark也支持通过parquet方法直接保存:

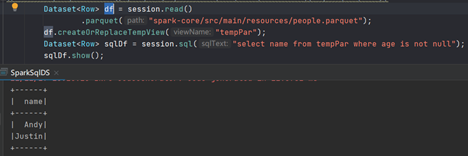
JDBC
对于我们来说,这种方法可能是最常用的。从数据库中读取数据,对其进行处理,然后写回数据库。
[En]
This approach is probably the most frequently used for us. The data is read from the database, processed and then written back to the database.
使用JDBC连接有两种方法,第一种方法是通过option传入连接参数:
- DataFrameReader jdbc = session.read().format(“jdbc”);
- jdbc.option(“url”, “jdbc:mysql://localhost:3306/enn”);
- jdbc.option(“dbtable”, “config_info”);
- jdbc.option(“user”, “root”);
- jdbc.option(“password”, “123456”);
- Dataset
- jdbcDf.show();
直接执行将报告错误,因为找不到数据库驱动程序
[En]
Direct execution will report an error because the database driver cannot be found

通过maven引入驱动(实际开发中如果不是使用maven项目,需要把驱动jar包放到服务器上指定classpath)即可成功
除了option参数,spark还提供了通过Jdbc方法来生成DF,这样没有load的显式过程:
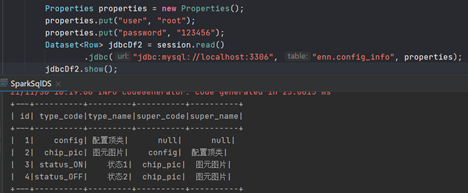
您可以看到,代码更短,更面向对象,因此推荐使用第二个。
[En]
You can see that the code is shorter and more object-oriented, so the second one is recommended.
另外库名可以放到url中也可以放到表名前面。下面这样也可以,这是驱动提供的能力,和编码无关

现在要把一个DF保存到数据库,使用write即可:
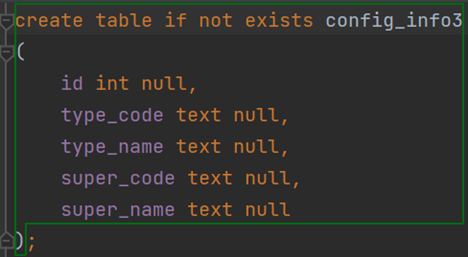
注意要保存的表不能提前存在,不然会说表已经有了。那spark自己怎么创建表呢?它会根据推断的类型创建一个字段都可空的表:
如果想追加数据呢?总不能每次都创建新表吧。可以使用mode方法指定,可以看到插入了两遍:
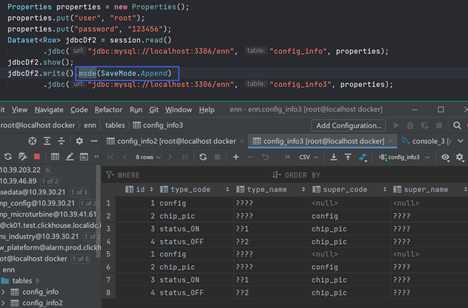
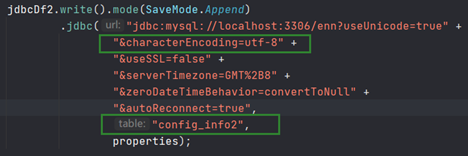
另一个问题是汉字的编码,我们需要具体说明:
[En]
Another problem is the coding of Chinese characters, which we need to specify:
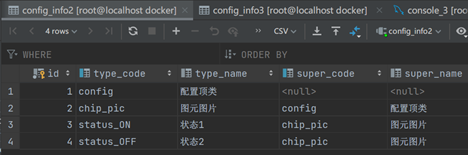
此处使用的是现有表,表定义是复制的原始表:
[En]
An existing table is used here, and the table definition is the original table that is copied:
Original: https://www.cnblogs.com/somefuture/p/15682410.html
Author: 老魏去东
Title: Spark3 学习【基于Java】4. Spark-Sql数据源
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/522645/
转载文章受原作者版权保护。转载请注明原作者出处!