

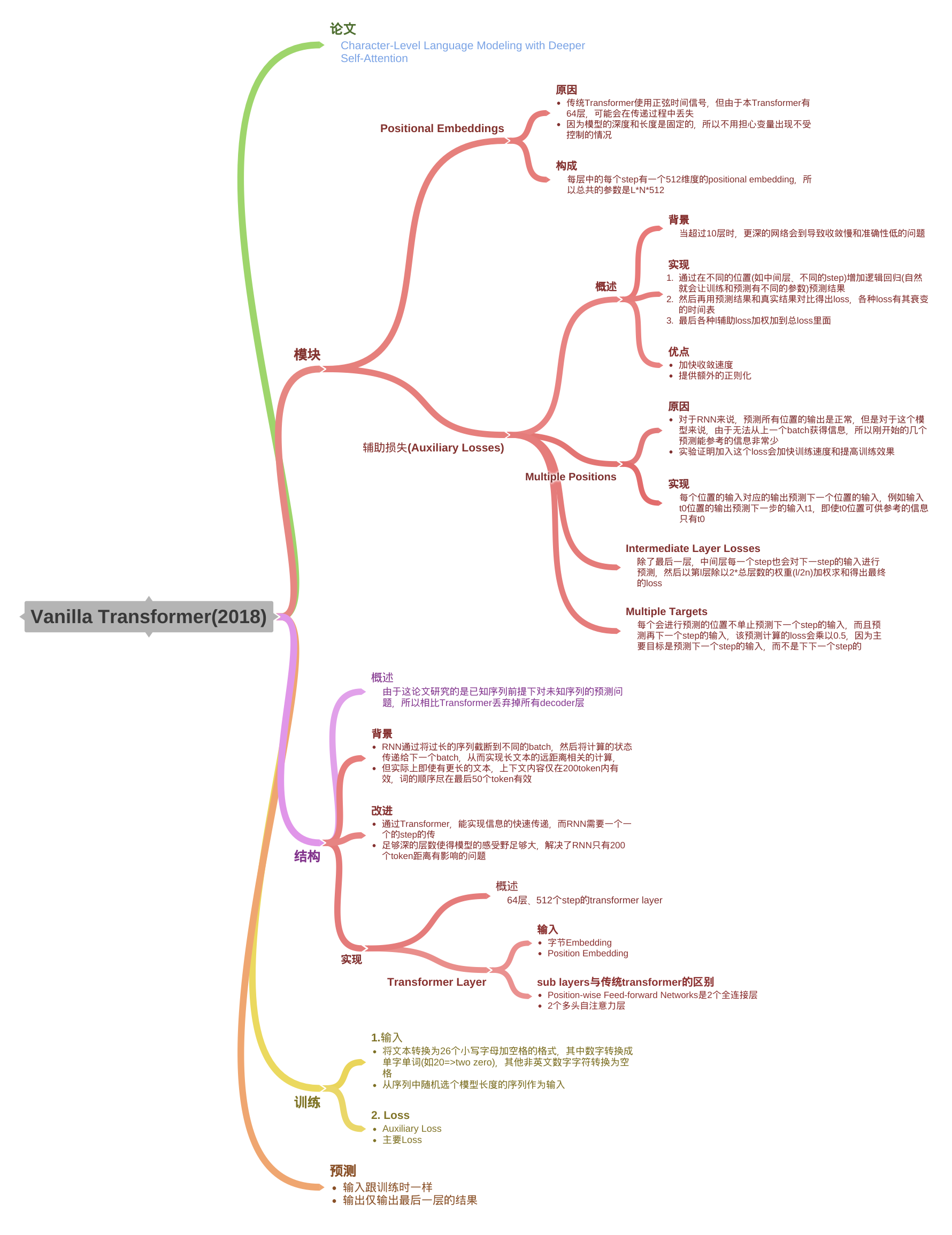

; 一、Vanilla Transformer的结构
首先,作者要解决的问题是字级别的LM,相比词级别的LM,字级别LM明显需要依赖的距离特别长,比如说一句话某个位置是应该使用she还是he,是依赖于前面的主语情况,这个主语可能距离此单词位置的有十几个单词,每个单词7-8字母长度,那么这就将近100+个字符长度了,作者使用transformer的结构主要原因是他认为该结构很容易做到在任意距离上的信息传递。相对而言,RNN(LSTM)这种结构,就需要按照时间一步一步的传递信息,不能做到跨越距离。
这篇文章虽然用到了transformer结构,但与Attention is all you need这篇文章(简称原Transformer)是有差异的。原Transformer整体是一个seq2seq结构,具体的细节见此处。而Vanilla Transformer只利用了原Transformer的decode的部分结构,也就是一个带有mask的attention层+一个ff层。
如果将 “一个带有mask的attention层+一个ff层” 称为一个layer,那么Vanilla Transformer一共有64个这
Original: https://blog.csdn.net/u013250861/article/details/119336101
Author: u013250861
Title: NLP-生成模型-2018:Vanilla Transformer【将长文本序列划截断为多个固定长度的段;段与段之间没有上下文依赖性;无法建模字符之间超过固定长度的依赖,关系导致上下文碎片化】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/532189/
转载文章受原作者版权保护。转载请注明原作者出处!