

数据分析
数据清洗:缺失值处理、1删除记录 2数据插补 3不处理



常见插补方法

插值法-拉格朗日插值法
根据数学知识可知,对于平面上已知的n个点(无两点在一条直线上可以找到n-1次多项式

,使次多项式曲线过这n个点。
1)求已知过n个点的n-1次多项式:
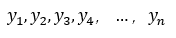

将缺失的函数值对应的点x带入多项式得到趋势值得近似值L(x)
#拉格朗日插值代码
import pandas as pd #导入数据分析库Pandas
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import lagrange #导入拉格朗日插值函数
inputfile = '../data/catering_sale.xls' #销量数据路径
outputfile = '../tmp/sales.xls' #输出数据路径
data = pd.read_excel(inputfile) #读入数据
temp = data[u'销量'][(data[u'销量'] < 400) | (data[u'销量'] > 5000)] #找到不符合要求得值 data[列][行]
for i in range(temp.shape[0]):
data.loc[temp.index[i],u'销量'] = np.nan #把不符合要求得值变为空值
#自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
y = s.iloc[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数 就是传入得data
y = y[y.notnull()] #剔除空值
f = lagrange(y.index, list(y))
return f(n) #插值并返回插值结果
#逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值。
data.loc[j,i] = ployinterp_column(data[i], j)
data.to_excel(outputfile) #输出结果,写入文件
print("success")
运行结果:

这个代码是可以运行的
问题
没有报 SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame

我不知道如何消除这个警告,但我只是在我不注意的时候寻找并运行它!似乎不能一次赋一个以上的值,而是单独赋值。
[En]
I don’t know how to eliminate this warning, but I just look for it and run it when I’m not paying attention! It seems that you can’t assign more than one value at a time, but assign values separately.
最后
但如果仔细观察,就会发现插入值有问题:如果我们输出插入值,就会发现存在异常值。
[En]
But if we take a closer look, we can find that there is something wrong with the inserted value: if we output the inserted value, we can see that there is an abnormal value.
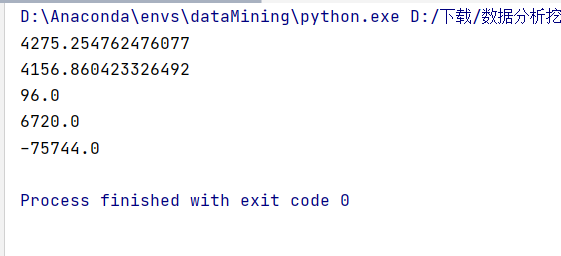
我们在处理数据时把小于400,大于5000的值都变成空值,然后通过拉格朗日插值法插入值,想要把数据没有那么大的差值,但是给我们插入一个负数,并且很离谱。我检查了一下并没有发现哪里有错误;然后我把用到的数据和拟合出来的拉格朗日函数输出得到:
f=-0.008874 x + 11.53 x – 6657 x + 2.242e+06 x – 4.854e+08 x + 7.005e+10 x – 6.74e+12 x + 4.168e+14 x – 1.504e+16 x + 2.411e+17
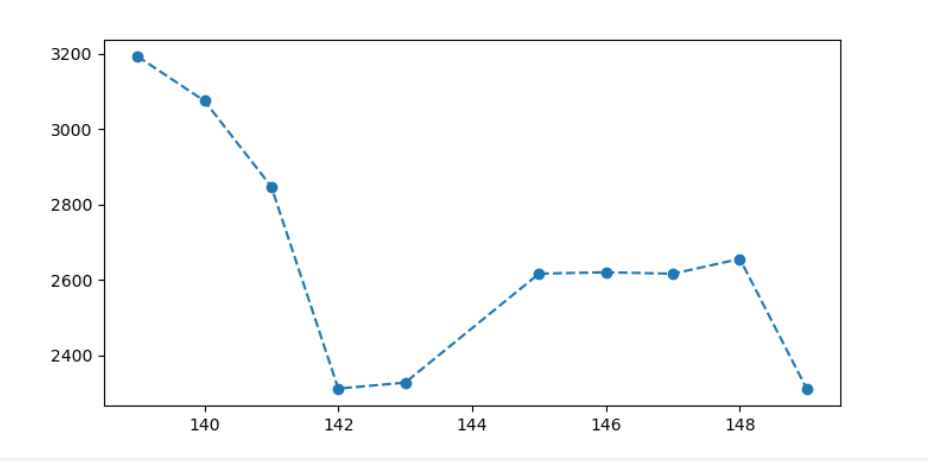
我没有发现问题,所以我想知道拟合函数步骤是否足够准确。我加了分,但没有好的结果,但更离谱。这种情况是过度拟合的,也就是说,这个模型可以很好地适应你的训练模型,但测试模型不是。
[En]
I didn’t find a problem, so I wondered if the fitting function steps were accurate enough. I added the points, but there were no good results, but it was even more outrageous. This situation is over-fitting, that is, this model can fit your training model very well, but the test model is not.
举个例子:下面一组数据可以看到用x4函数拟合的并没有太多的点在模型上,x4函数拟合的相对较多一点,但是如果进行测试,14次方的模型可能会预测的很离谱:
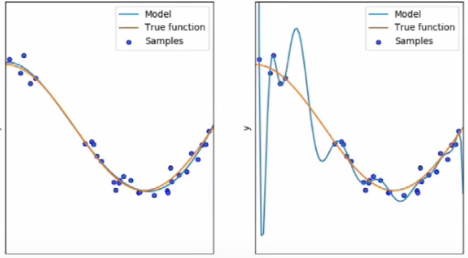
最后,我降低了值点,发现我上下取4个点会有一个好的结果,当我上下取3个点、2和1(直线,不推荐)时可以接受。所以,我们拟合的五个上下点没有错,但在那个点上的拟合函数是离谱的。
[En]
Finally, I reduced the value point and found that there would be a good result when I took 4 points up and down, and it was acceptable when I went up and down to 3 points, 2, and 1 (straight line, not recommended). So there is nothing wrong with the five upper and lower points fitted by us, but the fitting function is outrageous at that point.
Original: https://www.cnblogs.com/hjk-airl/p/15766870.html
Author: hjk-airl
Title: 拉格朗日插值法–Python
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/522549/
转载文章受原作者版权保护。转载请注明原作者出处!