

词向量:引言、 SVD 和 Word2Vec
关键词:NLP(自然语言处理)、词向量、SVD(奇异值分解)、Skip-gram、CBOW(连续词袋)、负采样、层级Softmax、Word2Vec
本文上一部分请见:CS224n: Natural Language Processing with Deep Learning 笔记、文献及知识点整理 (二)词向量(二)_放肆荒原的博客-CSDN博客
4. 基于迭代的方法 Word2vec ( Iteration Based Methods – Word2vec )
4.3 Skip-Gram 模型
另一种方法是创建一个模型,在给定中心词”jumped”的情况下,该模型能够预测或生成周围的词”The”、”cat”、”over”、”the”、”puddle”,这里我们称”jumped”这个词为上下文。 这种类型的模型就是 Skip-Gram 模型。
【注:】 Skip-Gram 模型: 给定中心词预测周围的上下文词
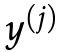

【注:】 Skip-Gram 模型的符号:
•
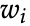 :来自词汇表 的单词 i
:来自词汇表 的单词 i•
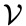 :输入词矩阵
:输入词矩阵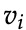
•
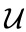 :输出词矩阵
:输出词矩阵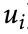
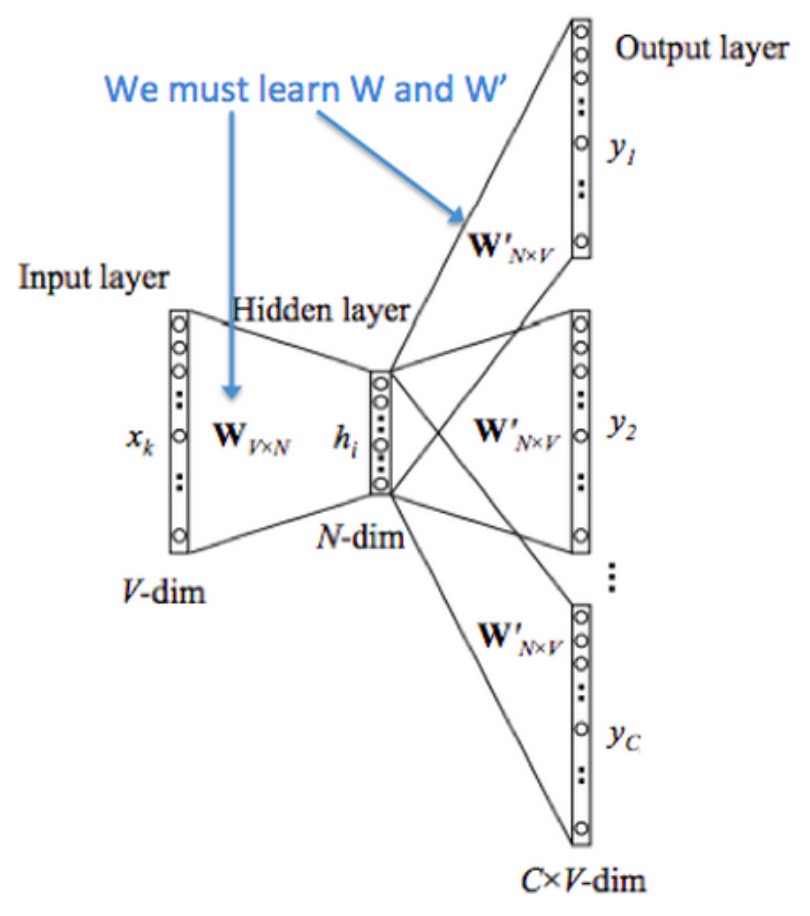
图 2: Skip-Gram 工作原理,及如何学习转换矩阵
我们把模型的工作方式分解为以下 6 个步骤:
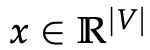
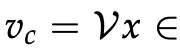
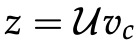
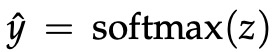
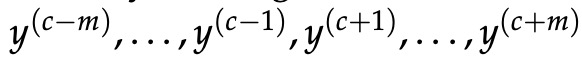
与 CBOW 一样,我们需要生成一个目标函数来评估模型。 这里的一个关键区别是我们调用朴素贝叶斯假设来分解概率。 简单地说,这是一个强(朴素)的条件独立假设。 换句话说,给定中心词,所有输出词都是完全独立的。
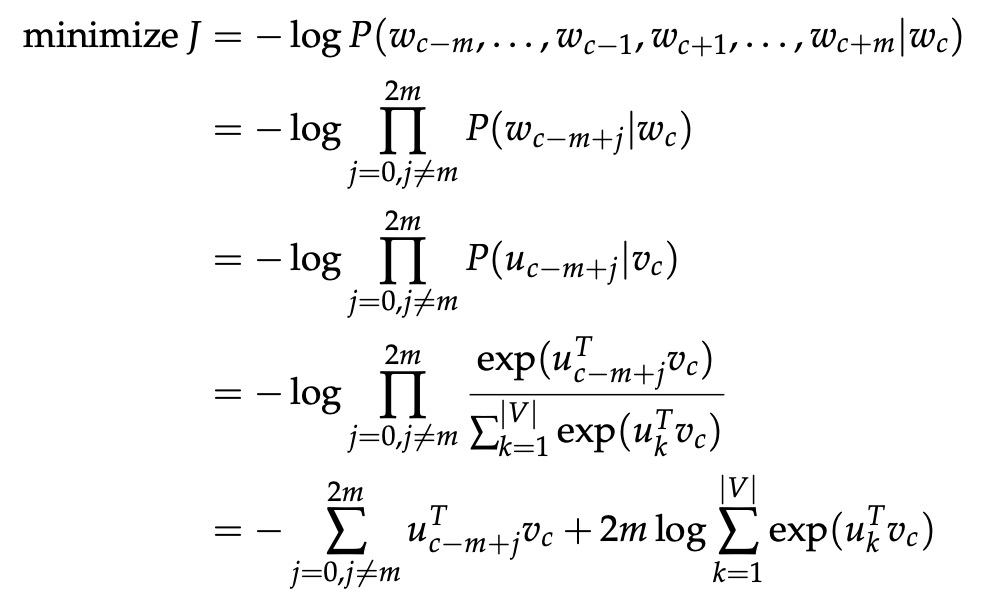
有了这个目标函数,我们可以计算关于未知参数的梯度,并在每次迭代时通过随机梯度下降更新它们。
注意下面的公式:
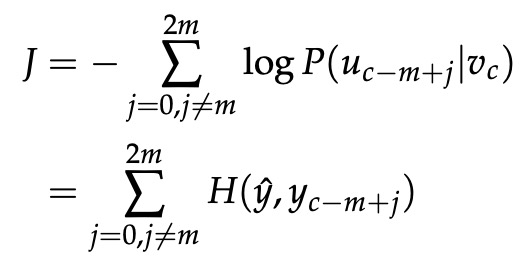
【注:】
4.4 负采样 Negative Sampling
让我们花点时间看看目标函数。 请注意,对 |V| 的求和计算量很大! 我们所做的任何更新或对目标函数的评估都需要 O(|V|) 时间,达到了数百万。 简单的做法是我们可以近似地实现它。
【注:】
由于 softmax 归一化,因为要对所有 |V| 分数求和,CBOW 和 Skip-Gram 的损失函数 J 计算成本很高!
对于每个训练步骤,我们可以只采样几个反例,而不是遍历整个词汇表! 我们从噪声分布 (Pn(w)) 中”采样”,其概率与词汇频率的排序相匹配。 为了增加我们对问题的表述以包含负采样,我们需要做的就是更新:
• 目标函数
• 梯度
• 更新规则
Mikolov等人提出了单词和短语的分布式表示及其组合中的 负采样。 虽然负采样基于 Skip-Gram 模型,但它实际上优化了不同的目标。 考虑一对单词和上下文 (w, c)。 我们用 P(D = 1|w, c) 表示 (w, c) 来自语料库数据的概率。用P(D = 0|w, c) 表示 (w, c)不是来自语料库数据的概率。 然后用 sigmoid 函数对 P(D = 1|w, c) 建模:
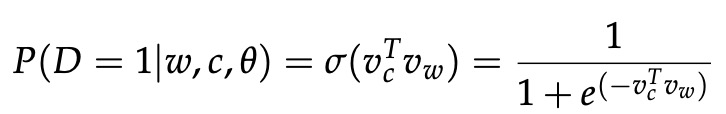

图 3:Sigmoid 函数
现在,我们构建了一个新的目标函数,试图最大化一个词和上下文在语料库数据中的概率,如果确实存在的话。如果确实不在语料库数据中,则最大化单词和上下文不在语料库数据中的概率。我们对这两个概率采用简单的最大似然方法。 (这里我们取 θ 作为模型的参数,在我们的例子中是
和 。)
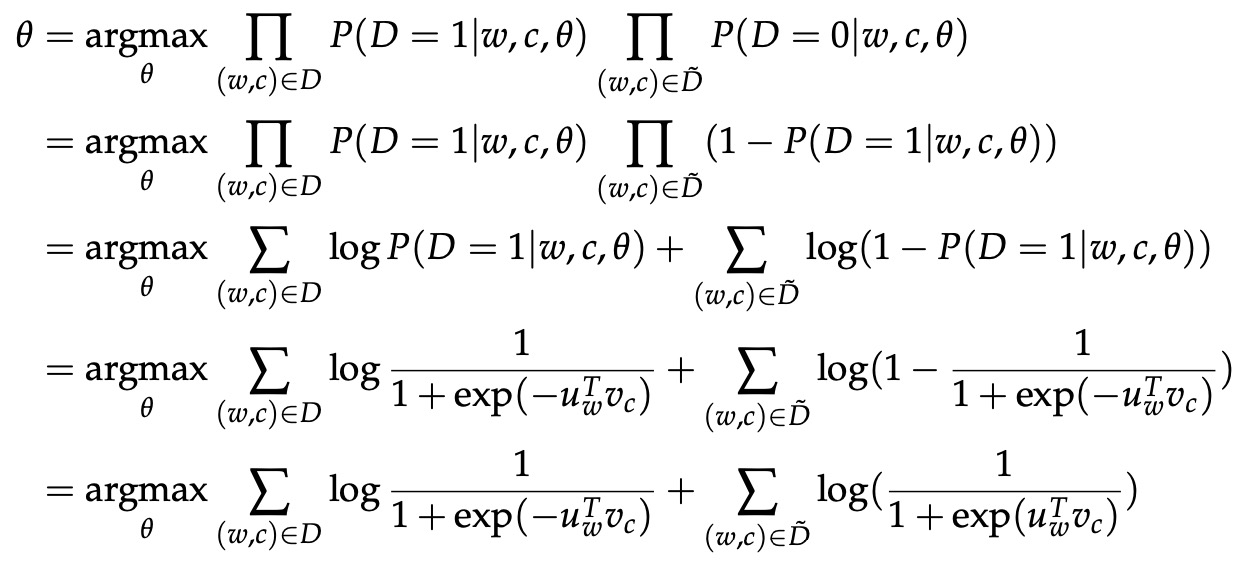
请注意,最大化似然与最小化负对数似然相同:
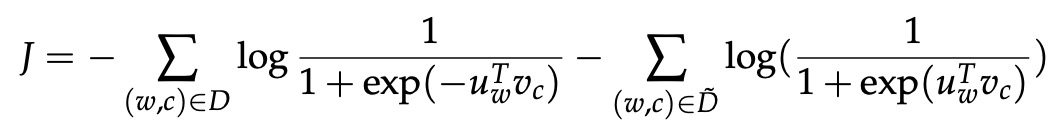
请注意,D̃是”假”或”负”语料库。 我们会有像”stock boil fish is toy”这样的出现概率很低的不自然句子。 可以通过从词库中随机采样这个负样本来动态生成 D̃。
对于skip-gram,给定中心单词c,我们观察上下文单词 c − m + j 的新目标函数为:
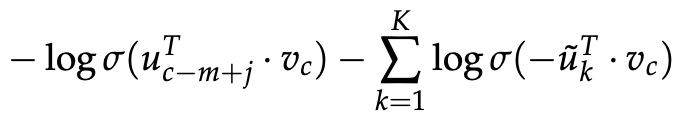
【注:】 比较skip-gram的常规softmax损失:
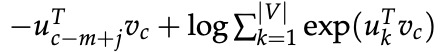

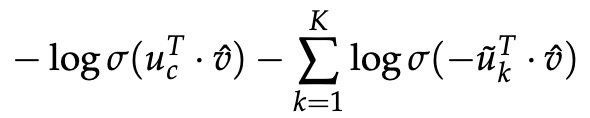
【注:】 比较 CBOW 的常规 softmax 损失:
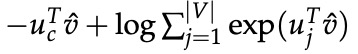
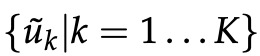
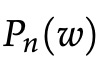
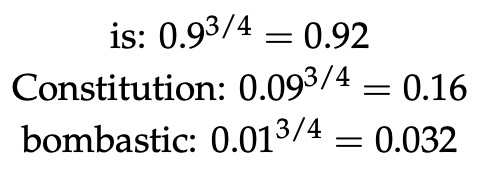
“Bombastic”被采样的可能性增加了 3 倍,而”is”仅略微上升。
4.5 层级Softmax (Hierarchical Softmax)
Mikolov 等人还提出了层级 softmax 作为普通 softmax 的更有效替代方案。 在实践中,分层 softmax 往往对不常用的词更好,而负采样对常用词和低维向量效果更好。
【注:】
层级 Softmax 使用二叉树,其中叶子是单词。 一个词作为输出词的概率被定义为从词根随机游走到该词叶的概率。 计算成本变为 O(log(|V|)) 而不是 O(|V|)。
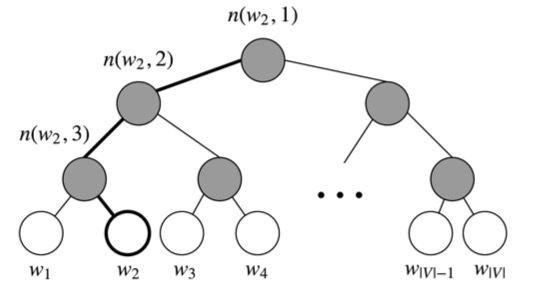
图 4:层级 softmax 二叉树
层级 softmax 从根到叶子都有一条独特的路径。 在这个模型中,没有词的输出表示。 相反,图中的每个节点(根和叶除外)都与模型将要学习的向量相关联。
在这个模型中,给定向量
的单词 w 的概率 等于从根开始到 w 对应的叶节点结束的随机游走的概率。 以这种方式计算概率的主要优点是成本仅为 O(log(|V|)),对应于路径的长度。
先给出一些符号,令 L(w) 为从根节点到叶节点 w 的路径的节点数。 例如,图 4 中的 L(w2) 为 3。 n(w, i) 为这条路径上的第 i 个节点,并带有关联向量
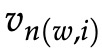 。 所以 n(w, 1) 是根,而 n(w, L(w)) 是 w 的父节点。 对于每个内部节点 n,我们任意选择它的一个子节点并将其称为 ch(n)(例如,始终是左节点)。 然后,我们可以计算概率为:
。 所以 n(w, 1) 是根,而 n(w, L(w)) 是 w 的父节点。 对于每个内部节点 n,我们任意选择它的一个子节点并将其称为 ch(n)(例如,始终是左节点)。 然后,我们可以计算概率为:
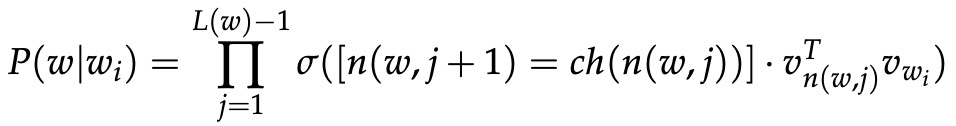
当
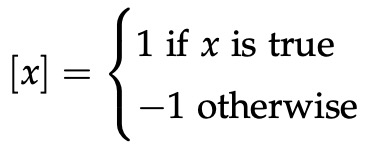
σ(·)是sigmoid函数。
公式有点儿复杂,我们仔细地检查一下。
首先,我们根据从根 (n(w, 1)) 到叶子 (w) 的路径形状计算各项的乘积。 如果我们假设 ch(n) 总是 n 的左节点,那么当路径向左时,[n(w, j + 1) = ch(n(w, j))] 返回 1,如果向右则返回 -1 。
用[n(w, j + 1) = ch(n(w, j))] 归一化。 在节点 n 处,如果我们将前往左节点和右节点的概率相加,您可以查
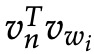 的任何值:
的任何值:
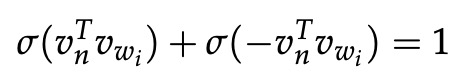
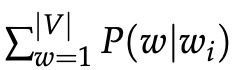
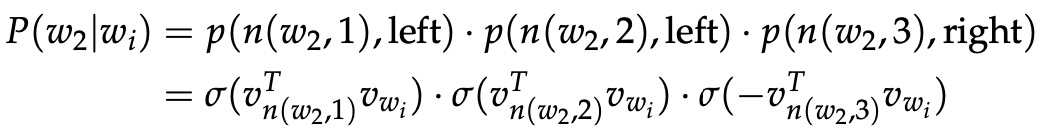

这种方法的速度取决于二叉树的构造方式和词分配给叶节点的方式。 Mikolov等人使用二叉 Huffman 树,它的特点是为频繁词在树中分配更短的路径。
Original: https://blog.csdn.net/weixin_53111034/article/details/121631422
Author: 放肆荒原
Title: CS224n: Natural Language Processing with Deep Learning 笔记、文献及知识点整理 (三)词向量(三)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531608/
转载文章受原作者版权保护。转载请注明原作者出处!