

NotFoundError: No algorithm worked! when using Conv2D
文章目录
*
–
+ NotFoundError: No algorithm worked! when using Conv2D
+
* 报错信息
* 系统及环境信息
* 代码
* 解决方案
* 分析原因
* 参考及引用
报错信息
2021-07-27 15:40:41.637309: W tensorflow/core/framework/op_kernel.cc:1763] OP_REQUIRES failed at conv_ops.cc:1106 : Not found: No algorithm worked!
Traceback (most recent call last):
File “E:/app/PyCharm/bigwhite/class11/LeNet-5.py”, line 36, in
model.fit(X_train, y_train, epochs=5000, batch_size=4096)
File “D:\ProgramData\Anaconda3\envs\py38\lib\site-packages\tensorflow\python\keras\engine\training.py”, line 1100, in fit
tmp_logs = self.train_function(iterator)
File “D:\ProgramData\Anaconda3\envs\py38\lib\site-packages\tensorflow\python\eager\def_function.py”, line 828, in call
result = self._call(args, kwds)
File “D:\ProgramData\Anaconda3\envs\py38\lib\site-packages\tensorflow\python\eager\def_function.py”, line 888, in _call
return self._stateless_fn(args, kwds)
File “D:\ProgramData\Anaconda3\envs\py38\lib\site-packages\tensorflow\python\eager\function.py”, line 2942, in call**
return graph_function._call_flat(
File “D:\ProgramData\Anaconda3\envs\py38\lib\site-packages\tensorflow\python\eager\function.py”, line 1918, in _call_flat
return self._build_call_outputs(self._inference_function.call(
File “D:\ProgramData\Anaconda3\envs\py38\lib\site-packages\tensorflow\python\eager\function.py”, line 555, in call
outputs = execute.execute(
File “D:\ProgramData\Anaconda3\envs\py38\lib\site-packages\tensorflow\python\eager\execute.py”, line 59, in quick_execute
tensors = pywrap_tfe.TFE_Py_Execute(ctx._handle, device_name, op_name,
tensorflow.python.framework.errors_impl.NotFoundError: No algorithm worked!
[[node sequential/conv2d/Conv2D (defined at E:/app/PyCharm/bigwhite/class11/LeNet-5.py:36) ]] [Op:__inference_train_function_666]
Function call stack:
train_function
系统及环境信息
OS: Windows 10
TensorFlow version: 2.4.1(gpu)
Python version: 3.8
CUDA/cuDNN version: Cuda is 11.1, cuDNN is 8.0.4
GPU model and memory: GeForce GTX 3060
代码
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import Flatten
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(60000, 28, 28, 1)/255.0
X_test = X_test.reshape(10000, 28, 28, 1)/255.0
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
model = Sequential()
model.add(Conv2D(filters=6, kernel_size=(5, 5), strides=(1, 1), input_shape=(28, 28, 1), padding='valid', activation='relu'))
model.add(AveragePooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=16, kernel_size=(5, 5), strides=(1, 1), padding='valid', activation='relu'))
model.add(AveragePooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(units=120, activation='relu'))
model.add(Dense(units=84, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.05), metrics=['accuracy'])
model.fit(X_train, y_train, epochs=5000, batch_size=4096)
loss, acc = model.evaluate(X_test, y_test, )
print(f"loos:{loss}, acc:{acc}")
解决方案
加入以下代码可解决我的问题:
import tensorflow as tf
physical_devices = tf.config.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
也有一个高赞解决方案,这应该是使用迁移工具升级的代码,实质上也是使用了 tensorflow. compat.v1兼容包来提供在 TensorFlow 2.x环境中执行1.x的代码,我的TensorFlow2.4.1似乎没有compat:
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
分析原因
根据其他人的回答
[1] yasirroni : In my case, this error appears because the memory is full. Try to check
nvidia-smivia terminal. In my case, I use cloud server usingjupyter. Shutdown all kernels (not only close the file, but shutdown), and restarting solve the issue.[2] otaviomguerra : A code from other issue helped me to find a way to limit tensorflow GPU memory usage and solved the issue, please see:
the code is:
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
tf.config.experimental.set_virtual_device_configuration(
gpus[0],
[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=4096)])
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
print(e)
用中文解释一下:就是在原有的程序,会在调用tensorflow的时候,立刻使得内存爆满,所以给GPU内存加上一些限制就可以
下图是我原程序运行时,GPU的使用信息,可以看到cuda和GPU内存利用率在一瞬间都接近100%了
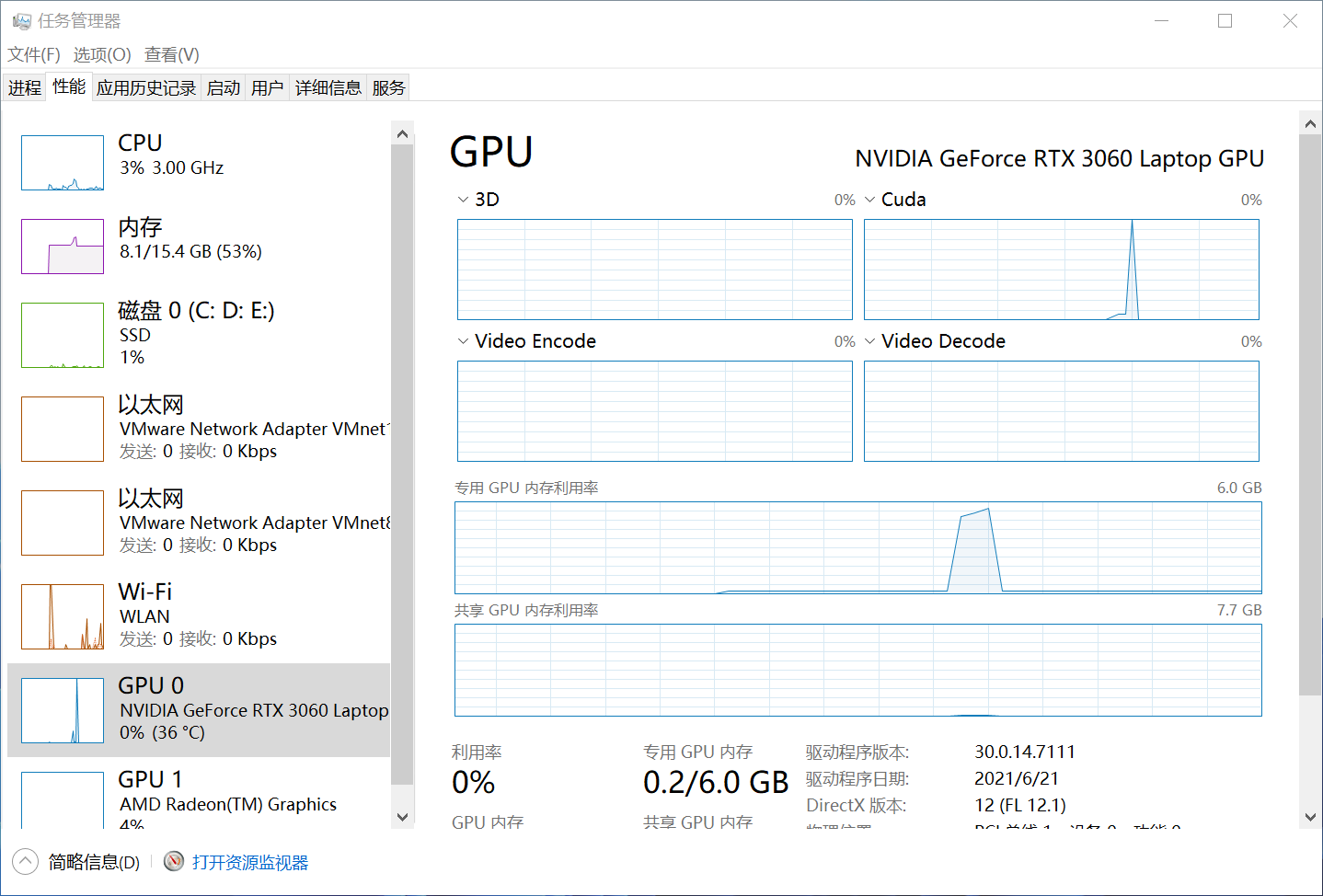

参考及引用
stackoverflow : how to solve no algorithm worked keras error
https://github.com/tensorflow/tensorflow/issues/43174Original: https://blog.csdn.net/qq_25837497/article/details/119145467
Author: 陪你到天明
Title: NotFoundError: No algorithm worked! when using Conv2D
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/521585/
转载文章受原作者版权保护。转载请注明原作者出处!