

半监督学习前提假设
1.连续性假设(Continuity Assumption)
分类问题- input是比较接近的时候,ouput的后验概率矩阵也应该距离比较小


2.聚类假设(Cluster Assumption)
类类内聚,类间分开
3.流形假设(Manifold Assumption)
- 所有数据点可以被多个低维流形表达。简单理解就是,将高维冗余特征降维到低维空间
- 相同流形上的数据点,标签一样。换句话说,降维之后同样标签的数据要接近或一致
半监督学习数学定义
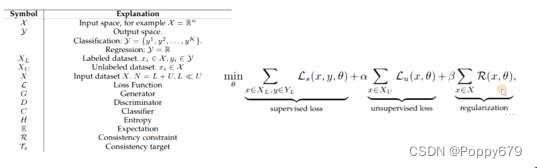
半监督学习本质上就是设计了一个损失函数,三个部分组成:有监督loss,无监督loss以及正则项
半监督学习的实施方法
生成式模型:Semi-supervised GANs ; Semi-supervised VAEs
Re-using Discriminator

Discriminator 鉴别器其实就充当的是二分类器,对输入或生成的图片判定真假;在半监督中重用这个鉴别器,是将这个鉴别器做成k分类分类器,构建方法是输入数据不仅是有标签的数据对,还有生成的数据,以及没有标签的数据。用这三块构建损失。
Generated Samples to regularize a classifier
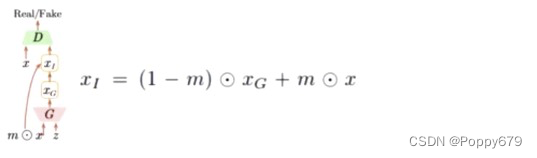
图片表征学习。Discriminator还是一个二分类器,设计了输入。XG是生成样本,m:binary mask(矩阵,只有0和1)相当于 特征抽取器
inference model
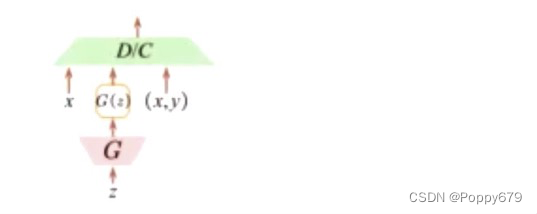
在Discriminator部分增加了C-类别。这里的是k+1类分类器,多的一类别是生成器产生,多出来的这个类别要跟真实的某一个类别接近。当模型训练完备以后,可以认为这个Discriminator具有分类能力。
Generate Data
增广数据,产生更多数据
一致性损失(Consistency Regularization一致性正则)
设计思路:

II Model
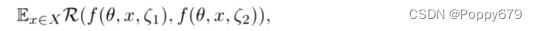
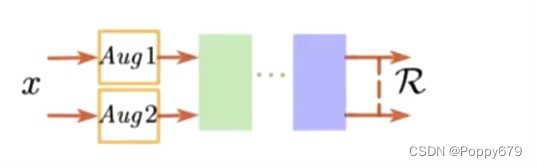
x是unlabeled数据,Aug是增广策略(随机翻转,增加噪声等等),送入模型进行识别,输出两个接近的后验概率或特征。每个训练的epoch,X会被前向推理两次,这两次的输入虽然经过不同的随机增广,但输出应该是具有一致性的。
图神经网络:AutoEncoder-based models ; GNN-based models
伪标签: Disagreement-based models ; Self-training models
Pseudo-label伪标签,标签是预测出来的。loss设计:第一项是有标记的损失,第二项是预测的伪标签进入模型的loss
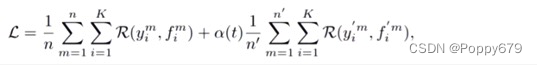
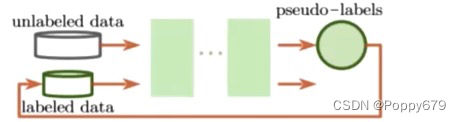
伪标签方法设计:结构上,训练流程,伪标签预测方法上做设计。但是伪标签存在弊端,即1.标签选择不易,因为模型在训练初期并不是完备的模型,预测一个伪标签若是错的,那么在迭代过程中会使模型误差变大。2.alpha值(权重系数)很难确定。(也有基于这两个弊端进行改进的方法)
混合方法
结合上述方法的优点以提升训练结果。
Original: https://blog.csdn.net/qq_34539676/article/details/125142908
Author: Poppy679
Title: 几种典型的半监督学习方法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/613529/
转载文章受原作者版权保护。转载请注明原作者出处!