

(作为一名研一学生,刚接触视觉处理4个月,如果说的或者代码有什么错误,还请谅解,帮我指正,多谢!)
胶囊网络是由Hiton在2017年提出,原文名为Dynamic Routing Between Capsules。该论文具体的内容和理解就不多说了,我最初也是从两个链接学习后,再看论文了解细节。不知道是不是我太菜了,Hiton的论文读起来比较费劲。
链接1:胶囊网络:更强的可解释性 – 知乎 (zhihu.com)![]()
 https://zhuanlan.zhihu.com/p/264910554 ;
https://zhuanlan.zhihu.com/p/264910554 ;
链接2:看完这篇,别说你还不懂Hinton大神的胶囊网络 (sohu.com)![]() https://www.sohu.com/a/226611009_633698 ;
https://www.sohu.com/a/226611009_633698 ;
原本想找现成的代码学习一下,但是由于我用的是tensorflow2.5.0版本,目前所有的代码我暂时没有找到tf2版本,所以只能参考tf1版本的代码自己复现一遍。我的代码没有把解码器和图片遮挡功能写进去,应该不难。
一、张量计算
我觉得胶囊网络最麻烦的地方还是在于张量的计算,它需要计算的张量维度都比较高,在学习的时候比较难理解,在这我配合图片和代码讲解一下。
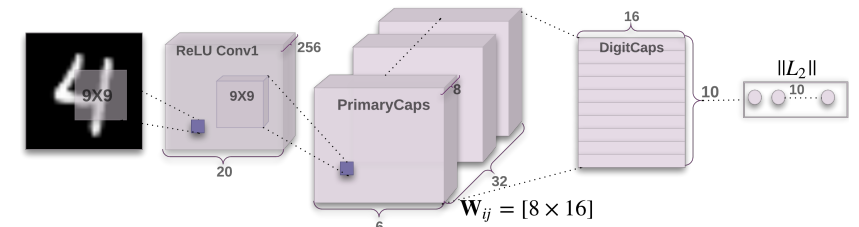
第一层是卷积层应该不难理解,卷积的作用主要是提取特征,输出特征图形状[-1,20,20,256]。(说明一下,我用-1来表示输入的batchsize)
class CapsuleNetwork(Model):
def __init__(self):
super(CapsuleNetwork, self).__init__()
self.conv1 = layers.Conv2D(filters=256, kernel_size=[9, 9], strides=1, padding='valid', activation=tf.nn.relu)
self.prim_cap = PrimCap()
self.digit_cap = DigitCap()
def call(self, inputs):
# 第1次卷积,256个卷积核,输出256个特征图[-1, 20, 20, 256]
out = self.conv1(inputs)
# 初级胶囊层
# out = self.conv2(out)
out = self.prim_cap(out)
# 数字胶囊层
out = self.digit_cap(out)
out = tf.nn.softmax(out, axis=1)
return out
第二层是初级胶囊层,内部含有一次卷积和reshape操作。卷积提出形状为[-1,6,6,256]的特征图。重点来了,初级胶囊被分为32个类(而不是32个胶囊,我一开始一直没有理解),每1个类都有8张6×6的特征图。每1个胶囊则是8个特征图在同一个位置的元素组成的[8,1]的向量,这个向量可以理解为位置向量,因此胶囊数为6x6x32=1152个。由于minst数据总共有10类,因此将胶囊复制10次(config.class_num),最后初级胶囊层的输出形状为[-1,1152,10,8,1]。
class PrimCap(Layer):
def __init__(self):
super(PrimCap, self).__init__()
self.conv2 = layers.Conv2D(filters=256, kernel_size=[9, 9], strides=2)
def call(self, inputs):
# 初级胶囊层
capsules = self.conv2(inputs)
capsules = tf.reshape(capsules, [-1, 6, 6, 8, 32])
capsules = tf.transpose(capsules, [0, 4, 3, 1, 2])
capsules = tf.reshape(capsules, [-1, 1152, 1, 8, 1])
capsules = tf.tile(capsules, [1, 1, config.class_num, 1, 1])
return capsules
第三层是数字胶囊层(动态路由),输入[-1,1152,10,8,1]形状的胶囊,每个胶囊都要经过[-1,1152,10,16,8]的姿态矩阵wij变换为预测胶囊的位置向量uhat(预测胶囊的位置向量形状为[16,1]),uhat形状为[-1,1152,16,10]。其中,wij的形状为[1,1152,10,16,8],由于batch中每一个wij都是一样的,所以在初始化wij时wij.shape[0]=1,在call里复制成[-1,1152,10,16,8]。bij是低级胶囊i对高级胶囊j的支持程度,bij.shape=[-1,1152,16,10],初始值均为0。cij=softmax(bij),将支持程度转变为概率。根据下列公式获得s(将1152这维全部相加)后,通过squash函数算得vij(vij.shape=[-1,10,16])。
此后,将vij复制1152次,得到vIJ,并根据bij= bij + vIJ * uhat来更新bij,并输出vij。将以上路由操作循环三次后,计算vij每一类的模[-1,10],将其通过softmax计算得出每一类的概率。
class DigitCap(Layer):
def __init__(self):
super(DigitCap, self).__init__()
def build(self, input_shape):
# 初始化姿态矩阵[1, 1152, 10, 16, 8]
self.shape = input_shape
self.wij = self.add_weight(name='wij', dtype=tf.float32, shape=[1, 1152, config.class_num, 16, 8], initializer=tf.random_normal_initializer())
def call(self, inputs):
# 数字胶囊层
bij = tf.zeros([self.shape[0], 1152, 16, config.class_num])
wij = self.wij
wij = tf.tile(wij, [self.shape[0], 1, 1, 1, 1])
for i in range(3):
bij, capsules = capsule(inputs, bij, wij, self.shape[0])
return capsules
def capsule(inputs, bij, wij, batch):
# ui.shape = [1, 1152, 10, 8, 1]
ui = inputs
# c.shape =[1, 1152, 16, 10]
c = tf.nn.softmax(bij, 3)
# wij.shape = [-1, 1152, 10, 16, 8] ui.shape = [1, 1152, 8, 1]
# uhat.shape = [-1, 1152, 16, 10]
# print(wij.shape, ui.shape)
uhat = tf.matmul(wij, ui)
uhat = tf.squeeze(uhat, 4)
uhat = tf.transpose(uhat, [0, 1, 3, 2])
# s.shape = [-1, 1152, 16, 10]
s = tf.reduce_sum(c * uhat, 1)
# print('s', s.shape)
# vij.shape = [-1, 16, 10]
vij = squash(s)
# 为计算方便,将v扩充成vIJ vIJ.shape = [-1, 1152, 16, 10]
vIJ = tf.reshape(vij, [-1, 1, 16, config.class_num])
vIJ = tf.tile(vIJ, [1, 1152, 1, 1])
bij += vIJ * uhat
vij = tf.squeeze(tf.norm(vij, axis=1, keepdims=2), 1)
# print('vij', vij.shape)
return bij, vij
二、tf2隐藏坑
最初想直接利用model.compile来导入自定义损失函数,但是无论是用def定义的还是class定义的损失函数,最后训练结果都不太正常,精度只有10%左右(不知道有没有大神知道具体原因在哪)。但是有两个解决方案:
1、在model内覆写train_step,不使用self.compiled_loss,直接将定义的损失函数代进去算loss。
class CapsuleNetwork(Model):
def __init__(self):
super(CapsuleNetwork, self).__init__()
self.conv1 = layers.Conv2D(filters=256, kernel_size=[9, 9], strides=1, padding='valid', activation=tf.nn.relu)
self.prim_cap = PrimCap()
self.digit_cap = DigitCap()
def train_step(self, data):
# 解包数据,由fit()传入
x, y = data
with tf.GradientTape() as tape:
y_pred = self(x, training=True) # 前向传播
# 计算损失
# (损失函数由compile()导入)
# loss_b = self.compiled_loss(y, y_pred, regularization_losses=self.losses)
loss_value = loss()(y, y_pred)
# 计算梯度
trainable_vars = self.trainable_variables
gradients = tape.gradient(loss_value, trainable_vars)
# 更新权重
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
# 更新精度
self.compiled_metrics.update_state(y, y_pred)
# 返回现值
return {m.name: m.result() for m in self.metrics}
def call(self, inputs):
# 第1次卷积,256个卷积核,输出256个特征图[1, 20, 20, 256]
out = self.conv1(inputs)
# 初级胶囊层
# out = self.conv2(out)
out = self.prim_cap(out)
# 数字胶囊层
out = self.digit_cap(out)
out = tf.nn.softmax(out, axis=1)
return out
2、不在model内,从模型外部进行自定义一个训练函数
def training(model, data_train, data_test, epochs, optimizer):
for epoch in range(epochs):
for step, (x, y) in enumerate(data_train):
with tf.GradientTape() as tape:
logits = model(x)
y_onehot = tf.one_hot(y, depth=config.class_num)
loss = margin_loss(y_onehot, logits)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if data_test is not None:
# test
total_correct = 0
total_num = 0
for x, y in data_test:
logits = model(x)
# prob = tf.nn.softmax(logits, axis=1)
pred = tf.argmax(logits, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.equal(pred, y)
correct = tf.reduce_sum(tf.cast(correct, dtype=tf.int32))
total_correct += int(correct)
total_num += x.shape[0]
acc = total_correct / total_num
print('Epoch:', epoch, 'Test_Acc:', acc, 'Loss:', float(loss))
print(total_correct, total_num)
[填坑]:由于MNIST数据集的标签是0-9的数字,需要先将标签改成one-hot形式再输入到model.fit中,原先定义的loss中需要把one-hot删掉,这样train-step就不用覆写了。
此外还发现一个问题,tf.maximum()内如果要用整数一定要在最后加小数点,(比如:0.)。
三、代码使用
我将代码分成三个py程序,第一个是模型,第二个是层,第三个是配置。在使用的时候,把三个程序放在同一个project里,运行capnet即可。
程序一:capnet.py
import tensorflow as tf
from tensorflow.keras import layers, Model, metrics
from tensorflow.keras.losses import Loss
from caplayers import PrimCap
from caplayers import DigitCap
import config
归一化
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32)/255
y = tf.cast(y, dtype=tf.int32)
return x, y
class CapsuleNetwork(Model):
def __init__(self):
super(CapsuleNetwork, self).__init__()
self.conv1 = layers.Conv2D(filters=256, kernel_size=[9, 9], strides=1, padding='valid', activation=tf.nn.relu)
self.prim_cap = PrimCap()
self.digit_cap = DigitCap()
def train_step(self, data):
# 解包数据,由fit()传入
x, y = data
with tf.GradientTape() as tape:
y_pred = self(x, training=True) # 前向传播
# 计算损失
# (损失函数由compile()导入)
# loss_b = self.compiled_loss(y, y_pred, regularization_losses=self.losses)
loss_value = loss()(y, y_pred)
# 计算梯度
trainable_vars = self.trainable_variables
gradients = tape.gradient(loss_value, trainable_vars)
# 更新权重
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
# 更新精度
self.compiled_metrics.update_state(y, y_pred)
# 返回现值
return {m.name: m.result() for m in self.metrics}
def call(self, inputs):
# 第1次卷积,256个卷积核,输出256个特征图[1, 20, 20, 256]
out = self.conv1(inputs)
# 初级胶囊层
# out = self.conv2(out)
out = self.prim_cap(out)
# 数字胶囊层
out = self.digit_cap(out)
out = tf.nn.softmax(out, axis=1)
return out
margin损失
class loss(Loss):
def call(self, y_true, y_pred):
y_true = tf.one_hot(y_true, config.class_num)
y_pred = tf.cast(y_pred, dtype=tf.float32)
m_max = tf.constant(0.9, tf.float32)
m_min = tf.constant(0.1, tf.float32)
L = y_true * tf.square(tf.maximum(0., m_max - y_pred)) + 0.5 * (1 - y_true) * tf.square(tf.maximum(0., y_pred - m_min))
L = tf.reduce_mean(tf.reduce_sum(L, 1))
return L
def margin_loss(y_true, y_pred):
y_true = tf.cast(y_true, dtype=tf.float32)
y_pred = tf.cast(y_pred, dtype=tf.float32)
m_max = tf.constant(0.9, tf.float32)
m_min = tf.constant(0.1, tf.float32)
L = y_true * tf.square(tf.maximum(0., m_max - y_pred)) + 0.5 * (1 - y_true) * tf.square(tf.maximum(0., y_pred - m_min))
L = tf.reduce_mean(tf.reduce_sum(L, 1))
return L
训练函数,目前使用model.fit
def training(model, data_train, data_test, epochs, optimizer):
for epoch in range(epochs):
for step, (x, y) in enumerate(data_train):
with tf.GradientTape() as tape:
logits = model(x)
y_onehot = tf.one_hot(y, depth=config.class_num)
loss = margin_loss(y_onehot, logits)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if data_test is not None:
# test
total_correct = 0
total_num = 0
for x, y in data_test:
logits = model(x)
# prob = tf.nn.softmax(logits, axis=1)
pred = tf.argmax(logits, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.equal(pred, y)
correct = tf.reduce_sum(tf.cast(correct, dtype=tf.int32))
total_correct += int(correct)
total_num += x.shape[0]
acc = total_correct / total_num
print('Epoch:', epoch, 'Test_Acc:', acc, 'Loss:', float(loss))
print(total_correct, total_num)
def main():
# 载入mnist
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = tf.reshape(x_train, [-1, 28, 28, 1])
x_train, y_train = preprocess(x_train, y_train)
x_test = tf.reshape(x_test, [-1, 28, 28, 1])
x_test, y_test = preprocess(x_test, y_test)
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_train = db_train.batch(config.batch_size)
db_test = db_test.batch(config.batch_size)
model = CapsuleNetwork()
model.build(input_shape=[1, 28, 28, 1])
model.summary()
optimizers = tf.optimizers.Adam(learning_rate=config.lr)
# training(model, db_train, db_test, config.epochs, optimizers)
model.compile(optimizer=optimizers, loss=loss(), metrics='Accuracy')
model.fit(x_train, y_train, config.batch_size, validation_data=(x_test, y_test), epochs=config.epochs)
if __name__ == '__main__':
main()
程序二:caplayers.py
import tensorflow as tf
from tensorflow.keras.layers import Layer
from tensorflow.keras import layers
import config
归一化
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32)/255
y = tf.cast(y, dtype=tf.int32)
return x, y
class PrimCap(Layer):
def __init__(self):
super(PrimCap, self).__init__()
self.conv2 = layers.Conv2D(filters=256, kernel_size=[9, 9], strides=2)
def call(self, inputs):
# 初级胶囊层
capsules = self.conv2(inputs)
capsules = tf.reshape(capsules, [-1, 6, 6, 8, 32])
capsules = tf.transpose(capsules, [0, 4, 3, 1, 2])
capsules = tf.reshape(capsules, [-1, 1152, 1, 8, 1])
capsules = tf.tile(capsules, [1, 1, config.class_num, 1, 1])
return capsules
class DigitCap(Layer):
def __init__(self):
super(DigitCap, self).__init__()
def build(self, input_shape):
# 初始化姿态矩阵[1, 1152, 16, 8]
self.shape = input_shape
self.wij = self.add_weight(name='wij', dtype=tf.float32, shape=[1, 1152, config.class_num, 16, 8], initializer=tf.random_normal_initializer())
def call(self, inputs):
# 数字胶囊层
bij = tf.zeros([self.shape[0], 1152, 16, config.class_num])
wij = self.wij
wij = tf.tile(wij, [self.shape[0], 1, 1, 1, 1])
for i in range(3):
bij, capsules = capsule(inputs, bij, wij, self.shape[0])
return capsules
def capsule(inputs, bij, wij, batch):
# ui.shape = [1, 1152, 10, 8, 1]
ui = inputs
# c.shape =[1, 1152, 16, 10]
c = tf.nn.softmax(bij, 3)
# uhatb.shape = [-1, 1152, 16, 10, 1] wij.shape = [-1, 1152, 10, 16, 8] ui.shape = [1, 1152, 8, 1]
# uhat.shape = [-1, 1152, 16, 10]
# print(wij.shape, ui.shape)
uhat = tf.matmul(wij, ui)
uhat = tf.squeeze(uhat, 4)
uhat = tf.transpose(uhat, [0, 1, 3, 2])
# s.shape = [-1, 1152, 16, 10]
s = tf.reduce_sum(c * uhat, 1)
# print('s', s.shape)
# vij.shape = [-1, 16, 10]
vij = squash(s)
# 为计算方便,将v扩充成vIJ vIJ.shape = [-1, 1152, 16, 10]
vIJ = tf.reshape(vij, [-1, 1, 16, config.class_num])
vIJ = tf.tile(vIJ, [1, 1152, 1, 1])
bij += vIJ * uhat
vij = tf.squeeze(tf.norm(vij, axis=1, keepdims=2), 1)
# print('vij', vij.shape)
return bij, vij
定义squash激活函数
def squash(s):
s = tf.reshape(s, [-1, 16, config.class_num])
l2 = tf.norm(s, axis=2, keepdims=3)
l2 = tf.tile(l2, [1, 1, 10])
v = (l2 * s) / (1 + l2**2)
return v
程序三:config.py
[database]
batch_size = 128
lr = 1e-3
m = 0.8
class_num = 10
epochs = 100
Original: https://blog.csdn.net/weixin_42906783/article/details/122203582
Author: Conitx
Title: 动态路由胶囊网络的tensorflow2实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/645319/
转载文章受原作者版权保护。转载请注明原作者出处!