

Tensorflow提供了一个Tensorflow Object Detection API可以很方便的使用这个API进行目标识别和检测,效果还不错。但是目前网上很多资料都是基于TF1的版本,很少基于tf2的版本,而且官方文档也有很多错误。正好这一阶段有个相关方面的任务,就研究了一下,并编译了一个自己的模型,可以对目标进行检查。特此记录下来,供自己和大家参考
编译环境大家最好使用docker,docker的版本也是要求的。由于TF2.0的object_dection的API对一些依赖库是有要求的,这个文件在/models/research/object_detection/packages/tf2/setup.py文件。
'avro-python3',
'apache-beam',
'pillow',
'lxml',
'matplotlib',
'Cython',
'contextlib2',
'tf-slim',
'six',
'pycocotools',
'lvis',
'scipy',
'pandas',
'tf-models-official>=2.5.1',
'tensorflow_io',
'keras'
其中要求tf-models-official>=2.5.1。这个对应的tf的版本至少是2.5以上。如果想用gpu进行训练,则就要求cuda的版本是11.2。如果自己安装cuda版本很麻烦,所以最好使用安装好cuda的docker镜像。2.6.0-gpu和2.7.0-gpu版本都可以。
docker pull tensorflow/tensorflow:2.7.0-gpu
如果要使用gpu进行训练,那么运行这个docker的容器有两个要求
- 要使用nvidia-docker启动容器。原因请自行百度
- 本机安装的驱动程序对应的cuda版本要和容器一样,否则启动的时候回报错
使用nvidia-smi运行GPU监控程序
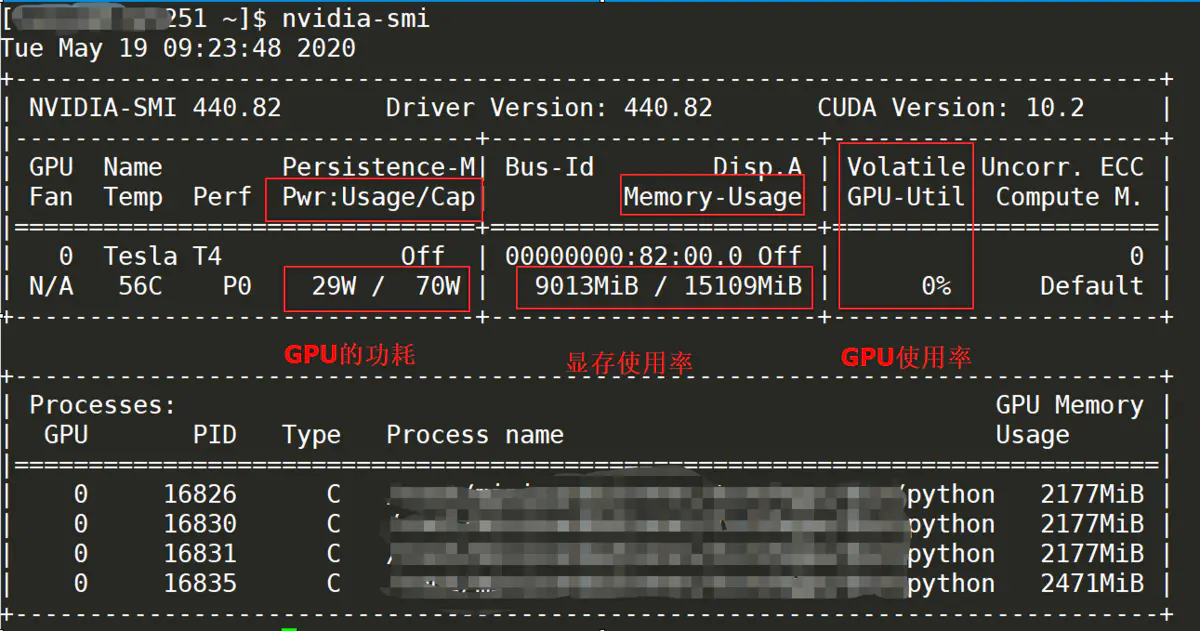

右上角就是CUDA的版本。
docker容器准备好,就可以在docker容器中安装tf2.0 object_detection的API了
下载model
https://github.com/tensorflow/models.git
安装依赖库
下载完成以后,开始安装所需的依赖库
在安装之前最好把python的源安装修改为清华源
pip install pip -U
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
apt-get install protobuf-compiler python-pil python-lxml python-tk
#cd models/research
#cp object_detection/packages/tf2/setup.py .
#python -m pip install .
cd models/official
pip install -r requirements.txt
这样编译所需要的依赖库就安装好了。
安装COCO API
git clone https://github.com/cocodataset/cocoapi.git
cd cocoapi/PythonAPI
make
cp -r pycocotools models/research/
进行Protobuf 编译
Tensorflow Object Detection API 使用protobufs来配置模型和训练参数
Protobuf是Google提出的一种新的数据交换格式,有取代json和xml的趋势,有兴趣的同学可以了解一下。
From tensorflow/models/research/
protoc object_detection/protos
把依赖库添加到PYTHONPATH路径
修改.bashrc文件,在末尾添加
export PYTHONPATH=$PYTHONPATH:/models/research:models/research/slim
测试
做完这些工作,就安装好e Tensorflow Object Detection,可以进行测试
python object_detection/builders/model_builder_tf2_test.py
如果结果显示如下
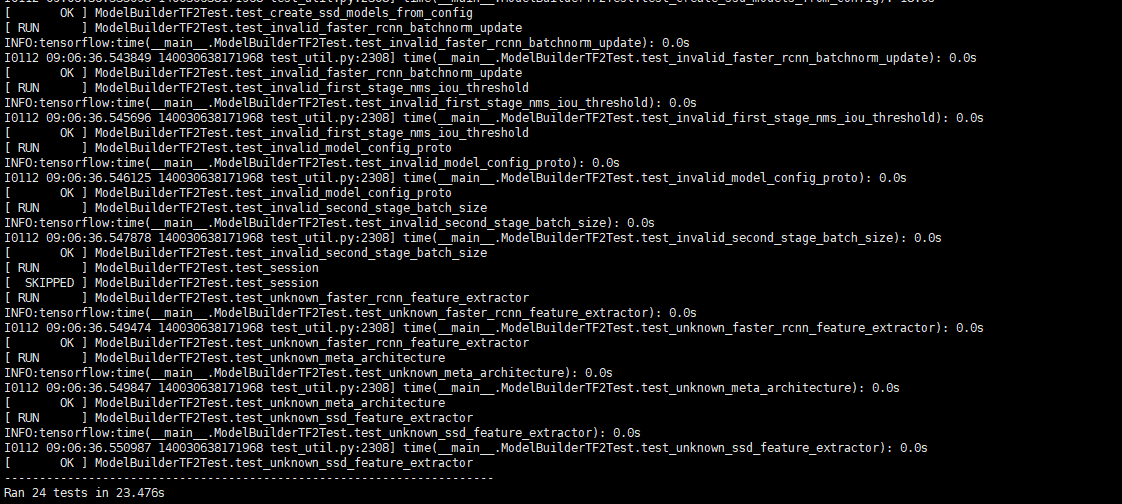
说明安装成功
获取数据
由于Tensorflow Object Detection API数据要有标注信息,例如是什么,物体的位置信息等等。所以需要自己动手对数据进行处理。步骤如下
- 使用软件LabelImg对图片进行画框,标注出感兴趣的物体。

- 对数据进行转换
对于标注过的图像数据,最终需要转换为 TFRecord格式,并且要分为训练集和验证集。网上有很多脚本可以完成这个工作。 - 创建label map文件。
label map文件用来对物体的名字和id进行映射,这样在识别的图像中,可以显示物体的名称。
item {
id: 1
name: 'dog'
}
item {
id: 2
name: 'cat'
}
准备数据集
由于上述过程比较麻烦,这里使用网上已经标注好和生成的tfrecord文件。
https://public.roboflow.com/object-detection/oxford-pets/2


这就是Oxford Pets Dataset,这个数据集只包括了两个动物,狗和猫

这样数据集就准备好了
创建训练配置文件
需要创建一个训练配置文件。作为基础模型,将使用 EfficientDet——。Tensorflow OD API 提供了许多不同的模型。有关更多信息,请查看Tensorflow 2 Detection Model Zoo
训练配置文件的模板在
models/research/object_detection/configs/tf2
在这里使用
ssd_efficientdet_d0_512x512_coco17_tpu-8.config
需要修改的几个字段
- 第 13 行:将num_classes更改为要检测的对象数(目前的训练集为情况下为 2)
- 第 141 行:将fine_tune_checkpoint 更改为model.ckpt 文件的路径: fine_tune_checkpoint: ” /efficientdet_d0_coco17_tpu-32/checkpoint/ckpt-0″
- 第 143 行:更改fine_tune_checkpoint_type为detection
- 第 182 行:将 input_path 更改为 train.records 文件的路径:input_path: ” /train.record”
- 第 197 行:将 input_path 更改为 test.records 文件的路径:input_path: ” /test.record”
- 第 180 和 193 行:将 label_map_path 更改为标签映射的路径:label_map_path: ” /labelmap.pbtxt”
- 第 144 和 189 行:将 batch_size 更改为适合您的硬件的数字,例如 4、8 或 16。
- 第149行可以修改训练的轮数,默认为30W。
别的学习率,权重都可以修改
训练模型
设置好以后就可以训练模型了
python /models/research/object_detection/model_main_tf2.py \
--pipeline_config_path=oxfordpet/ssd_efficientdet_d0_512x512_coco17_tpu-8.config \
--model_dir==oxfordpet/training \
--alsologtostderr
如果提示错误
ImportError: libGL.so.1: cannot open shared object file: No such file or directory
需要安装
apt install libgl1-mesa-glx
如果一切设置正确,训练应该很快就会开始,您应该会看到如下内容:
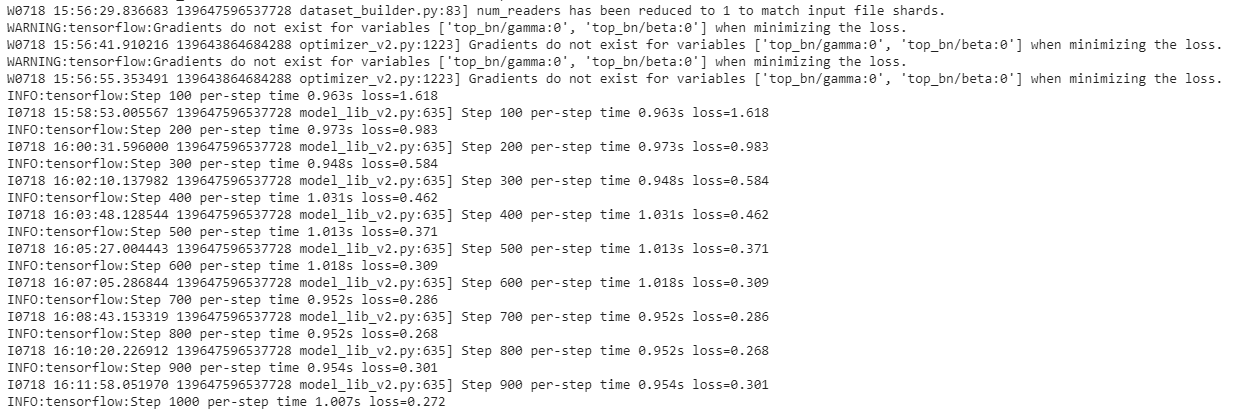
每隔几分钟,当前的损失就会记录到 Tensorboard。通过打开第二个命令行打开 Tensorboard,导航到 object_detection 文件夹并键入:
tensorboard --bind_all --logdir=training/train
这将在 localhost:6006 打开一个网页

训练脚本大约每五分钟保存一次检查点。训练模型直到达到令人满意的损失,然后您可以通过按 Ctrl+C 来终止训练过程。
导出模型
现在我们有了一个经过训练的模型,我们需要生成一个可用于运行模型的推理图。
python models/research/object_detection/exporter_main_v2.py \
--trained_checkpoint_dir training \
--output_directory inference_graph \
--pipeline_config_path training/ssd_efficientdet_d0_512x512_coco17_tpu-8.config
这样就会生成模型
使用模型进行推理
当模型导出以后,就可以使用模型进行推理了。具体的demo见资源文件。这个demo是使用摄像头进行实时目标侦测
下载地址
https://download.csdn.net/download/dfman1978/75544177
Original: https://blog.csdn.net/dfman1978/article/details/122453656
Author: 想游泳的鱼
Title: 使用Tensorflow Object Detection API训练自己的数据,并使用编译成功的模型进行识别
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/521134/
转载文章受原作者版权保护。转载请注明原作者出处!