

数据清洗的目的是修正异常值,以更好地进行运算和观察结果。通过 Pandas对序列或数据帧的清洗分为两个步骤:异常检测和数据修正。
1.异常检测
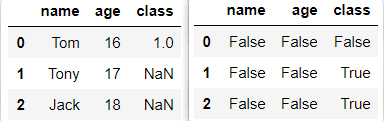
Pandas中的空值用’ NaN‘表示,可以通过调用 isnull和 notnull来检测序列对象和数据帧对象是否为异常值。
import pandas as pd
dic = {'name': ['Tom', 'Tony', 'Jack'], 'age': [16, 17, 18], 'class': [1, None, None]}
df = pd.DataFrame(dic)
df.isnull()

2.数据修正
数据检测完毕之后,需要对数据进行修正。
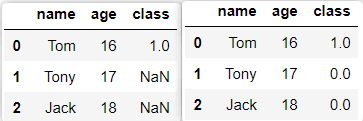
(1)填充值:将序列或者数据帧中的异常值” NaN“使用其他数据进行填充。
import pandas as pd
dic = {'name': ['Tom', 'Tony', 'Jack'], 'age': [16, 17, 18], 'class': [1, None, None]}
df = pd.DataFrame(dic)
df.fillna(0)
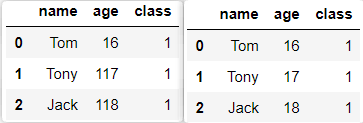
(2)替换值:对于一些明显出错的信息,如下列 age列中的’117’,’118’就可以使用 replace进行替换。
import pandas as pd
dic = {'name': ['Tom', 'Tony', 'Jack'], 'age': [16, 117, 118], 'class': [1, 1, 1]}
df = pd.DataFrame(dic)
df.replace({117:17, 118:18})
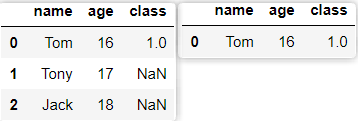
(3)删除值:删除异常值的同时会删除对应的数据行,可以使用dropna方法进行清除异常数据。
dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
参数
- axis:默认为0,删除包含缺失值的行。若设置为1,删除包含缺失值的列(不建议这样做,因为可能删除一个特征)。
- how:默认值any,如果存在NaN值,就删除该行或该列。若设置为all,当所有值都是NaN值,才删除该行或该列。
- thresh:表示有效数据量的最小要求,如thresh=1,该行或该列至少有一个不是NaN值时会将其保留。
- subset:在特定的字集中寻找NaN值。
- inplace:表示是否在原数据上操作,如果设为True,则表示直接修改原数据;如果设为False,则表示修改原数据的副本,返回新数据。
import pandas as pd
dic = {'name': ['Tom', 'Tony', 'Jack'], 'age': [16, 17, 18], 'class': [1, None, None]}
df = pd.DataFrame(dic)
df.dropna(axis=0, thresh=3)
Original: https://blog.csdn.net/qq_43965708/article/details/114452300
Author: Dream丶Killer
Title: 使用Pandas进行数据清洗
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/679757/
转载文章受原作者版权保护。转载请注明原作者出处!