

豆瓣Top250网址 将之前爬取到的豆瓣电影进行简单的可视化: 数据列表保存为CSV格式,如图
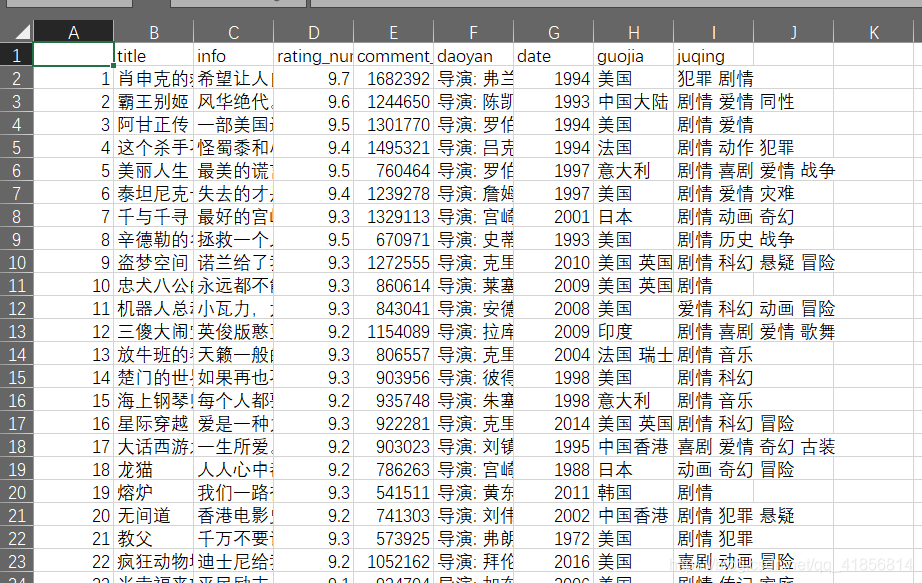

导入数据 做好准备
import pandas as pdimport numpy as npimport matplotlib.pylab as pltimport refrom numpy import rankfrom builtins import mapfrom datashape.coretypes import MapMovie=pd.read_csv('./doubanmovietop.csv')
检查数据头
Movie.head()
Unnamed: 0
title
info
rating_num
comment_num
daoyan
date
guojia
juqing
0
1
肖申克的救赎
希望让人自由。
9.7
1682392
导演: 弗兰克·德拉邦特 Frank Darabont主演: 蒂姆·罗宾斯 Tim Robb…
1994
美国
犯罪 剧情
1
2
霸王别姬
风华绝代。
9.6
1244650
导演: 陈凯歌 Kaige Chen主演: 张国荣 Leslie Cheung / 张丰毅 …
1993
中国大陆 中国香港
剧情 爱情 同性
2
3
阿甘正传
一部美国近现代史。
9.5
1301770
导演: 罗伯特·泽米吉斯 Robert Zemeckis主演: 汤姆·汉克斯 Tom Han…
1994
美国
剧情 爱情
3
4
这个杀手不太冷
怪蜀黍和小萝莉不得不说的故事。
9.4
1495321
导演: 吕克·贝松 Luc Besson主演: 让·雷诺 Jean Reno / 娜塔莉·波…
1994
法国
剧情 动作 犯罪
4
5
美丽人生
最美的谎言。
9.5
760464
导演: 罗伯托·贝尼尼 Roberto Benigni主演: 罗伯托·贝尼尼 Roberto…
1997
意大利
剧情 喜剧 爱情 战争
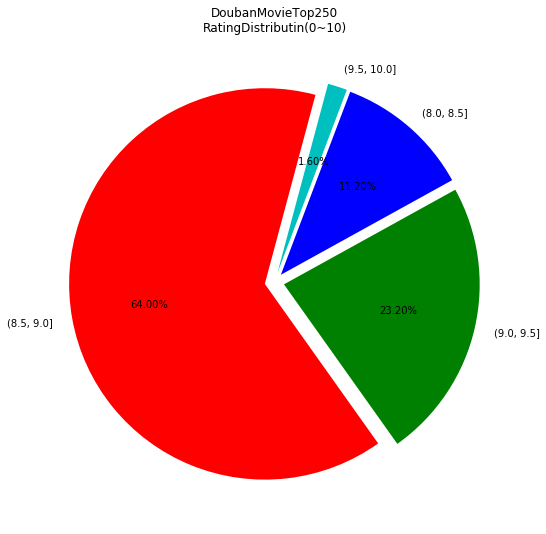
Rating=Movie['rating_num']bins=[8,8.5,9,9.5,10] rat_cut=pd.cut(Rating,bins=bins)rat_class=rat_cut.value_counts() rat_pct=rat_class/rat_class.sum()*100 rat_arr_pct=np.array(rat_pct)f1=plt.figure(figsize=(9,9))plt.title('DoubanMovieTop250\nRatingDistributin(0~10)')plt.pie(rat_arr_pct,labels=rat_pct.index,colors=['r','g','b','c'],autopct='%.2f%%',startangle=75,explode=[0.05]*4) plt.savefig('MovieTop250.RatingDistributin(0~10).png')f1.show()
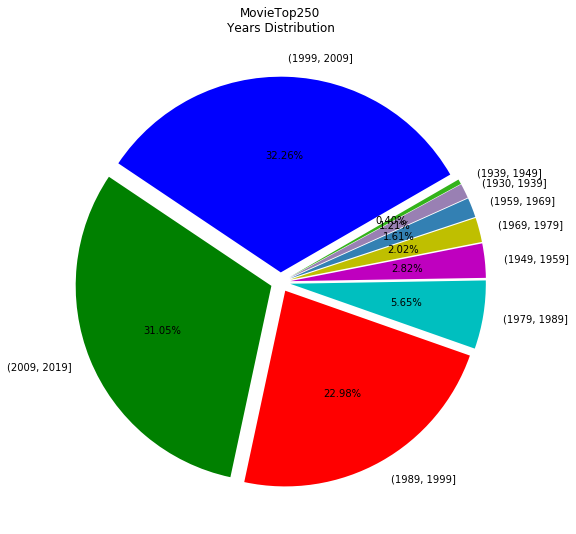
year=Movie['date']for i in year.index: if len(year[i])>4: year.drop(i,inplace=True) year=year.astype(int)bins=np.linspace(min(year)-1,max(year)+1,10).astype(int) year_cut=pd.cut(year,bins=bins)year_class=year_cut.value_counts()year_pct=year_class/year_class.sum()*100year_arr_pct=np.array(year_pct)color=['b', 'g', 'r', 'c', 'm', 'y', (0.2,0.5,0.7), (0.6,0.5,0.7),(0.2,0.7,0.1)] f2=plt.figure(figsize=(9,9))patches,out_text,in_text=plt.pie(year_arr_pct,labels=year_pct.index,colors=color,autopct='%.2f%%',explode=[0.05]*9,startangle=30)plt.title('MovieTop250\nYears Distribution')f2.show()
豆瓣电影Top250,电影排名&评价人数&电影评分的散点图:
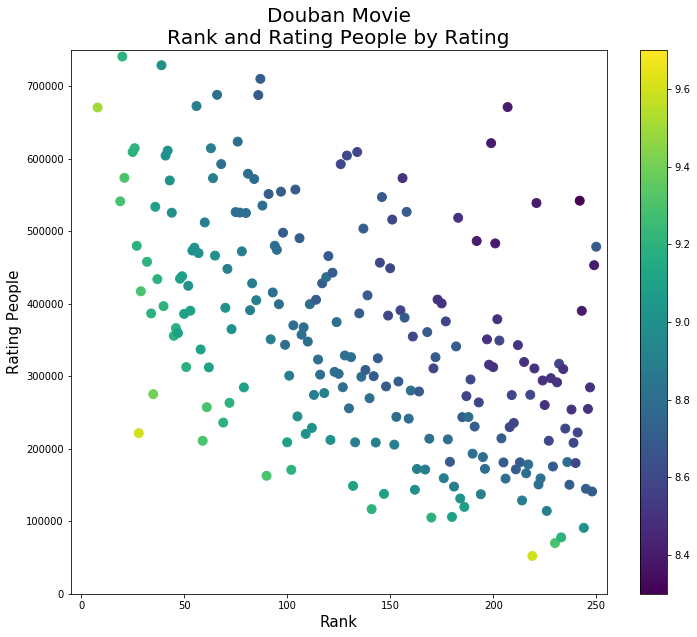
rank=np.array(Movie.index,dtype=int)+1 Movie['0']=rankf3=plt.figure(3,figsize=(12,10))plt.scatter(x=Movie['0'],y=Movie['comment_num'],c=Movie['rating_num'],s=80)plt.title('Douban Movie\nRank and Rating People by Rating',fontsize=20)plt.xlabel('Rank',fontsize=15)plt.ylabel('Rating People',fontsize=15)plt.axis([-5,255,0,750000]) plt.colorbar() plt.savefig('DoubanMovie_Rank_and_RatingPeople_by_Rating.png')plt.show()
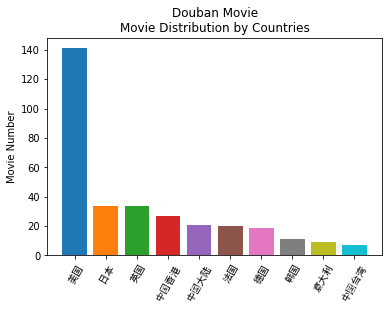
import pandas as pdimport numpy as npimport matplotlib.pylab as pltfrom matplotlib.font_manager import FontProperties Movie=pd.read_csv('./doubanmovietop.csv',encoding='utf-8')country_iter=(set(x.split(' ')) for x in Movie['guojia']) countries=sorted(set.union(*country_iter)) df=pd.DataFrame(np.zeros((len(Movie),len(countries))),columns=countries)for i,gen in enumerate(Movie['guojia']): df.ix[i,gen.split(' ')]=1 num_of_country=df.sum() num_of_country[4]=num_of_country[1]+num_of_country[2]+num_of_country[4] num_of_country.sort_values(inplace=True,ascending=False)f1=plt.figure()for i,gen in enumerate(num_of_country[:10]): plt.bar(i,gen) names=list(num_of_country.index)plt.xticks(np.arange(10),names,fontproperties='SimHei',rotation =60) plt.ylabel('Movie Number')plt.title('Douban Movie\nMovie Distribution by Countries')f1.show()
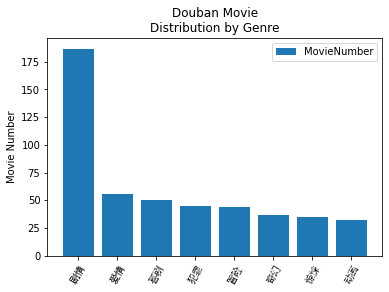
genre_iter=(set(x.split(' ')) for x in Movie['juqing'])genre=sorted(set.union(*genre_iter))frame=pd.DataFrame(np.zeros((len(Movie),len(genre))),columns=genre)for i,gen in enumerate(Movie['juqing']): frame.ix[i,gen.split(' ')]=1genre_sum=frame.sum()genre_sum.sort_values(inplace=True,ascending=False)f2=plt.figure(2)'''for i,gen in enumerate(genre_sum[:8]): plt.bar(i,gen)names=list(genre_sum.index)plt.xticks(np.arange(8)+0.4,names,fontproperties='SimHei')plt.show()'''p2=plt.bar(np.arange(8),genre_sum.values[:8],align='center') names=list(genre_sum.index)plt.xticks(np.arange(8),names,fontproperties='SimHei')plt.legend((p2[0],),('MovieNumber',)) plt.ylabel('Movie Number')plt.title('Douban Movie\nDistribution by Genre')plt.show()

如需数据 请关注公众号 后台回复 :豆瓣电影
即可获取~
Original: https://blog.51cto.com/u_15707053/5441341
Author: 刘旺學長
Title: 【数据分析】豆瓣电影Top250爬取的数据的可视化分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516764/
转载文章受原作者版权保护。转载请注明原作者出处!