

1.概述
随着微服务和分布式计算的出现,Kafka已经成为各种主流平台系统架构中不可缺少的组成部分了。在本篇文章中,笔者将尝试为大家来解密Kafka的内部存储机制是如何运作的。
2.内容
在分布式系统中构建操作简单性,尤其是对于细微的行为,通常需要经过生产实践后才能总结出经验。而Kafka的流行很大程度上归功于其设计和操作的简单性。Kafka中更细微的特性之一是它的复制协议,对于单个集群上不同规模的工作负载,将Kafka复制调整为自动工作,这个是有挑战的。从用户使用的角度来看,如果生产者发送一批很大的消息,那么很可能导致Kafka Broker出现告警,这意味着数据没有被复制到足够的Broker中,因此这些副本失败或者宕机,数据丢失的可能性就会增加。
学习Kafka系统的存储机制,需要先了解与Kafka系统存储有关的几个概念。
- 代理节点(Broker):Kafka集群组建的最小单位,消息中间件的代理节点。
- 主题(Topic):用来区分不同的业务消息,类似于数据库中的表。
- 分区(Partition):是主题物理意义上的分组。一个主题可以分为多个分区,每个分区是一个有序的队列。
- 片段(Segment):每个分区又可以分为多个片段文件。
- 偏移量(Offset):每个分区都由一系列有序的、不可修改的消息组成,这些消息被持续追加到分区中,分区中的每条消息记录都有一个连续的序号,即Offset值,Offset值用来标识这条消息的唯一性。
- 消息(Message):Kafka系统中,文件的最小存储单位。
在Kafka系统中,消息是以主题作为基本单位。不同的主题之间是相互独立、互不干扰的。每个主题又可以分为若干个分区,每个分区用来存储一部分的消息。
2.1 复制
Kafka的Topic中的每个分区都有一个预写日志,其中存储了消息,并且每条消息都有一个唯一的偏移量,用于标识它在分区日志中的位置。
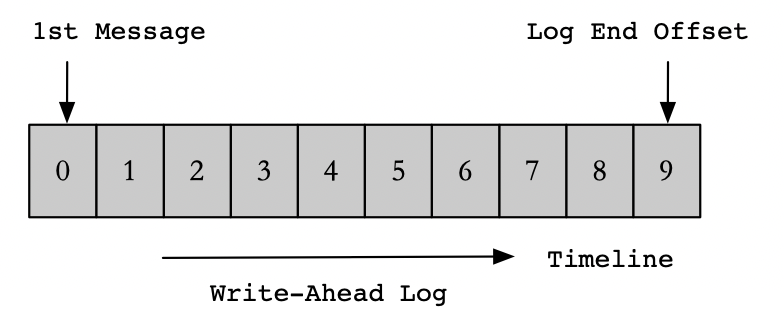

Kafka中的每个Topic分区都被复制N次,其中N是Topic的复制因子(生产环境通常设置为3副本)。这允许Kafka在集群中的服务器发生故障时自动转移到这些副本,以便在出现故障的时候,存储在Kafka中的数据仍然可用。Kafka中的复制发生在分区粒度,其中分区的预写日志被复制到N个节点。在N个副本中,一个副本被选举为Leader,而其他副本则成为Follower。Leader从生产者那里获取写入,而Follower则按照顺序复制Leader上的消息数据。
Kafka通过要求从与前一个Leader同步的副本子集中选举出Leader,赶上Leader的消息来提供各种保证。每个分区的Leader通过计算每个副本与自身的滞后来跟踪这个同步列表(ISR)。当生产者向Broker发送消息时,它由Leader写入并复制到所有分区的副本。一条消息只有在成功复制到所有同步副本后才会提交。由于消息复制延迟受到最慢的同步副本限制,快速检测慢副本并将它们从同步副本列表中删除非常重要。
2.2 文件分区存储
- 分区文件存储
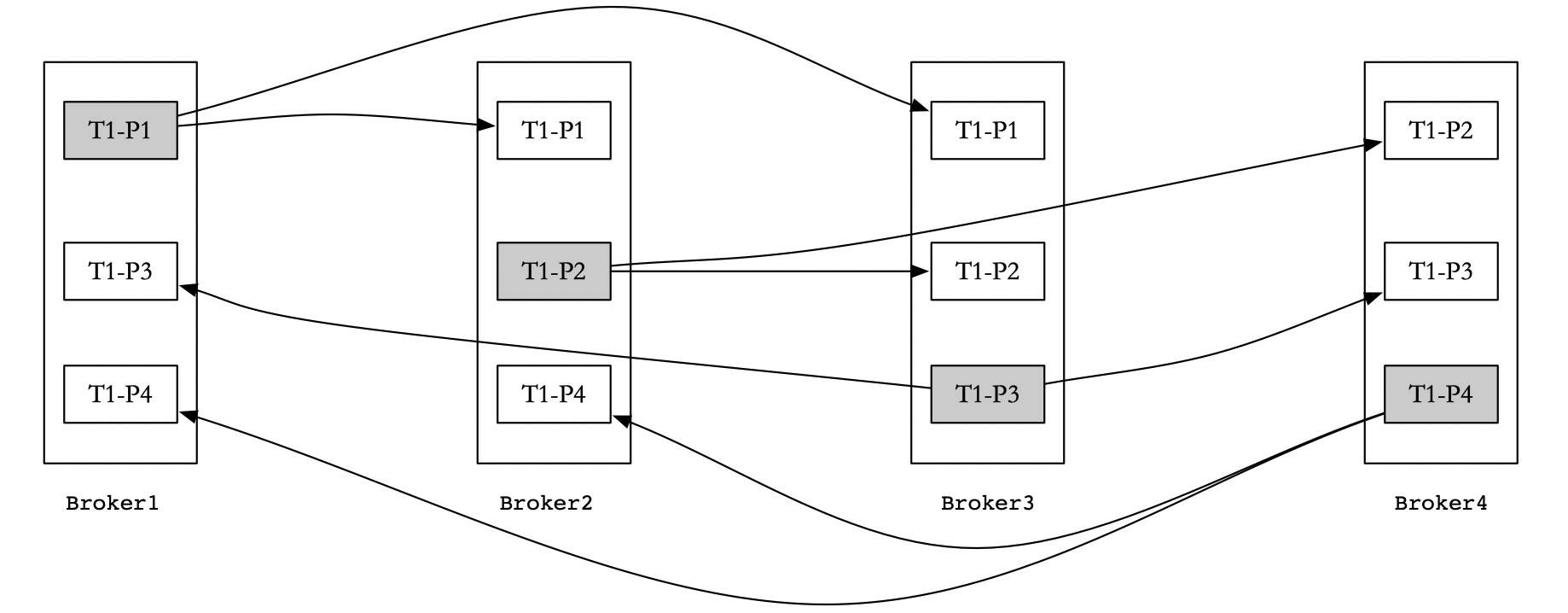
在Kafka系统中,一个主题(Topic)下包含多个不同的分区(Partition),每个分区为单独的一个目录。分区的命名规则为:主题名+有序序号。第一个分区的序号从0开始,序号最大值等于分区总数减1。
主题的存储路径由”log.dirs”属性决定。代理节点中主题分区的存储分布如图所示。
每个分区相当于一个超大的文件被均匀分割成的若干个大小相等的片段(Segment),但是每个片段的消息数据量不一定相等。正因为这种特性的存在,过期的片段数据才能被快速地删除。 片段文件的生命周期由代理节点server.properties文件中配置的参数决定,这样,快速删除无用的数据可以有效地提高磁盘利用率。
2.3 片段文件存储
片段文件由索引文件和数据文件组成:后缀为”.index”表示索引文件,后缀为”.log”的表示数据文件,后缀为”.timeindex”表示时间索引文件。 查看某一个分区的片段,输出结果如图所示。

Kafka系统中,索引文件并没有给数据文件中的每条消息记录都建立索引,而是采用了稀疏存储的方式——每隔一定字节的数据建立一条索引。稀疏存储索引避免了索引文件占用过多的磁盘空间。 将索引文件存储在内存中,虽然没有建立索引的Message,不能一次就定位到所在的数据文件上的位置,但是稀疏索引的存在会极大地减少顺序扫描的范围。
2.4 Record Batch
Kafka系统提供了一个查看Log文件的命令,执行如下命令查看消息结构,具体操作如下:
./kafka-run-class.sh kafka.tools.DumpLogSegments --files /kafkadata/test3-0/00000000000000000000.log --print-data-log
在Magic为V2的版本中,消息集称为Record Batch,而在V0、V1时称为Message Set,比较于V0和V1,V2将多个消息打包存储到单个Record Batch中,V2版本的单个Record Batch相较于V0和V1多了LOG_OVERHEAD便于节省空间,同时引入变长整型和新的编码,能够灵活节省空间,Record Batch格式如下:
baseOffset: int64
batchLength: int32
partitionLeaderEpoch: int32
magic: int8 (current magic value is 2)
crc: int32
attributes: int16
bit 0~2:
0: no compression
1: gzip
2: snappy
3: lz4
4: zstd
bit 3: timestampType
bit 4: isTransactional (0 means not transactional)
bit 5: isControlBatch (0 means not a control batch)
bit 6~15: unused
lastOffsetDelta: int32
firstTimestamp: int64
maxTimestamp: int64
producerId: int64
producerEpoch: int16
baseSequence: int32
records: [Record]
3.存储过期处理
Kafka系统提供了两种清除过期消息数据的策略:
- 基于时间和大小的删除策略;
- 压缩(Compact)清理策略。
这两种策略通过属性”log.cleanup.policy”来控制,可选值包含”delete”和”compact”,默认值为”delete”。
3.1 基于时间
按照时间来配置删除策略,配置内容见代码:
系统默认保存7天
log.retention.hours=168
3.2 基于大小
按照保留大小来删除过期数据,配置内容见代码:
系统默认没有设置大小
log.retention.bytes=-1
另外,也可以同时配置时间和大小来设置混合规则。一旦日志大小超过阀值,则清除分区中老的片段数据。若分区中某个片段的的数据超过保留时间也会被清除。
4.总结
如果使用压缩策略清除过期日志,则需设置属性”log.cleanup.policy”的值为”compact”。压缩清除只能针对特定的主题应用,即,写的消息数据都包含Key。它会合并相同Key的消息数据,只留下最新的消息数据。
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。
TRANSLATE with x ; ; TRANSLATE with EMBED THE SNIPPET BELOW IN YOUR SITE Enable collaborative features and customize widget: Bing Webmaster Portal
Original: https://www.cnblogs.com/smartloli/p/15085655.html
Author: 哥不是小萝莉
Title: Kafka存储内幕详解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/533909/
转载文章受原作者版权保护。转载请注明原作者出处!