

性能调优的多样性
1 SQL优化
union all可以改成两次连续的insert插入可以提高mapreduce性能,
但是在之后的版本hive自身做了优化,该方法则并不能再提高性能
2 数据块大小
减少map数量,提高网络传输压力有时候可以提高性能
3 不同的数据格式
SequenceFile
Parquet
ORC


4 表设计
如分区,分桶,同时分区分桶

优化案例
干预SQl运行方式
1 引擎执行过程的干预
--union优化:用grouping sets代替union的SQL优化
SELECT a, b, SUM( c ) FROM table GROUP BY a, b GROUPING SETS ( (a,b), a) 等同于
SELECT a, b, SUM( c ) FROM table GROUP BY a, b
UNION SELECT a, null, SUM( c ) FROM table GROUP BY a
优点:
GROUPING SETS在遇到多个条件时,聚合是一次性从数据库中取出所有需要操作的数据,
在内存中对数据库进行聚合操作并生成结果,而不会像GROUP BY多次扫描表后进行UNION操作。
这也就是为什么GROUPING SETS和UNION操作所返回的数据顺序是不同的
缺点:
使用union操作会增加IO开销,会减少cpu和内存的开销,使用grouping sets会减少IO开销,会增加cpu和内存的消耗
--count distinct 数据倾斜:
原因:所有key会分发到同一个reduce进行去重统计个数,数据量较大时导致运行时间过长。
解决办法:将 count distinct 改写为 group by 的写法。目的是增加一个MR的操作
案例:select s_age,count(distinct s_score) num
from student_tb_orc
group by s_age
--改写后的代码段
select s_age,count(1) num
from(
select s_age,s_score,count(1) num
group by s_age,s_score
) a
注意:distinct字段如果数据量不大不推荐使用该方法,因为该方式是通过1个MR任务变成2个MR任务来避免数据倾斜
另外 hive.optimize.countdistinct:默认值为true,Hive 3.0新增的配置项,hive自动分2个MR任务处理
2 通过SQL-Hint语法实现对计算引擎执行过程的干预
--MAPJOIN()括号中指定的是数据量较小的表,表示在Map阶段完成a,b表的连接
将原来在Reduce中进行连接的操作,前推到Map阶段
--STREAMTABLE(),括号中指定的数据量大的表
默认情况下在reduce阶段进行连接,hive把左表中的数据放在缓存中,右表中的数据作为流数据表
如果想改变上面的那种方式,就用/*+streamtable(表名)*/来指定你想要作为流数据的表
3 通过数据库开放的一些配置开关,来实现对计算引擎的干预
如短暂提高写入效率时,可以提高并行度,暂时关闭wal日志等
避免过度优化
代码优化原则
·理透需求原则,这是优化的根本;
distinct字段如果数据量不大不推荐使用额外group by,因为该方式是通过1个MR任务变成2个MR任务来避免数据倾斜
如果去重数值本身不大,可自定义实现MR
map阶段局部去重后全部写入null为key进一个reduce,唯一一个reduce做全局去重,可实现O(1)去重复杂度
·把握数据全链路原则,这是优化的脉络;
1 desc formatted。通过desc formatted tablename来查看hive表信息
可以获取到注释、字段的含义(comment)、创建者用户、数据存储地址、数据占用空间和数据量等信息
2 查询元数据
Hive的元数据主要分为5个大部分:数据库相关的元数据、表相关的元数据、分区相关的元数据、文件存储相关的元数据及其他
3 通过组件反馈信息。常见的资源管理组件有YARN和Mesos,常见的任务管理调度工具有oozie、azkaban和airflow等
·坚持代码的简洁原则,这让优化更加简单;
·没有瓶颈时谈论优化,是自寻烦恼。
Hive程序相关规范
见书2.2.3
Mapreduce计算引擎
这里基本略过
Mapreduce原理和参数配置
mapper参数配置见5.3.2
reducer参数配置见5.4.2
Map端的聚合与Hive配置

Hive配置与作业输出
MapReduce作业与Hive配置
HiveSQL执行计划
执行计划还是需要在工作中对照着书仔细查看
可以结合书本和改文章一起结合理解执行计划
MR join和group by代码实现
查看执行计划的基本信息,即explain;
查看执行计划的扩展信息,即explain extended;
查看SQL数据输入依赖的信息,即explain dependency;
explain dependency识别SQL读取数据范围的差别
如果要使用外连接并需要对左、右两个表进行条件过滤,最好的方式就是将过滤条件放到表的就近处
查看SQL操作相关权限的信息,即explain authorization;
查看SQL的向量化描述信息,即explain vectorization
向量化模式是Hive的一个特性,在没有引入向量化的执行模式之前,一般的查询操作一次只处理一行,
在向量化查询执行时通过一次处理1024行的块来简化系统底层操作,提高了数据的处理性能
set hive.vectorized.execution.enabled = true; 前提是磁盘列式存储格式为:ORC、Parquet
SQL执行计划解读
见6.2/6.3
普通函数和操作符
见6.3.2
带聚合函数的SQL执行计划解读 6.4
·在Reduce阶段聚合的SQL执行计划;
·在Map和Reduce都有聚合的SQL执行计划;
·高级分组聚合的执行计划
高级分组聚合
使用高级分组聚合需要确保map聚合是否开启 set hive.map.aggr=true
GROUPING SETS,cube,rollup 用法如下图
通常使用简单的GROUP BY语句,一份数据只有一种聚合情况,一个分组聚合通常只有一个记录;
使用高级分组聚合,例如cube,在一个作业中一份数据会有多种聚合情况,最终输出时,每种聚合情况各自对应一条数据。
如果使用该高级分组聚合的语句处理的基表,在数据量很大的情况下容易导致Map或者Reduce任务因硬件资源不足而崩溃。
Hive中使用hive.new.job.grouping.set.cardinality配置项来应对上面可能出现的问题,
如果SQL语句中处理的分组聚合情况超过该配置项指定的值,默认值(30),则会创建一个新的作业来处理该配置项的情况。

带窗口/分析函数的SQL执行计划 6.5
表连接的SQL执行计划 6.6
内接连和外连接 6.6.2
Hive数据处理模式
过滤模式
·where子句过滤;
·having子句过滤;
·distinct命令过滤(去重原理);
关闭Map端聚合下,的distinct去重会在Reduce阶段使用Group By Operator操作将其转化成分组聚合的方式
explain select distinct s_age from student_tb_seq == explain select s_age from student_tb_seq group by s_age
扩展:使用分组聚合的方式不是Hive去重的唯一方式,有时Hive还会用Hash表进行去重
·表过滤;
表过滤是指过滤掉同一个SQL语句需要多次访问相同表的数据,将重复的访问操作过滤掉并压缩成只读取一次
如union改multi-group-by-insert方法
同时两个group by的insert,hive会合并一个mr处理
·分区过滤;
普通where子句的过滤是在Map阶段,而分区列筛选其实是在Map的上一个阶段,即在输入阶段进行路径的过滤
·分桶过滤;
说分区是对目录的过滤,分桶是对文件的过滤。如下图

·索引过滤;
Hive的索引在Hive 3.0版本中被废弃,可以使用两种方式进行替换:
方式一,物化视图(Materialized views)。这个概念对于使用Oracle的开发者并不陌生,
通过使用物化视图,可以达到类似hive索引的效果,该特性在Hive 2.3.0版本中引入。
方式二,使用ORC/Parquet的文件存储格式,也能够实现类似索引选择性扫描,
快速过滤不需要遍历的block,这是比分桶更为细粒度的过滤
·列过滤
在进行列筛选时,通常需要先取整行的数据,再通过列的偏移量取得对应的列值
但如果是列式存储,则可以直接读取
聚合模式
常见的聚合
·distinct模式;
·count计数的聚合模式;
·count(列):如果列中有null值,那么这一列不会被记入统计的行数。
另外,Hive读取数据进行计算时,需要将字节流转化为对象的序列化和反序列化的操作。
·count(*):不会出现count(列)在行是null值的情况下,不计入行数的问题。
另外,count(*)在进行数据统计时不会读取表中的数据,只会使用到HDFS文件中每一行的行偏移量。
该偏移量是数据写入HDFS文件时,HDFS添加的。
·count(1):
count(*)也包含NULL,如果表没有主键,那么count(1)比count(*)快。
表有主键,count(*)会自动优化到主键列上。如果表只有一个字段,count(*)最快。
count(1)跟count(主键)一样,只扫描主键。count(*)跟count(非主键)一样,扫描整个表。明显前者更快一些。
count(1)和count(*)基本没有差别,但在优化的时候尽量使用count(1)
·数值相关的聚合模式;
·行转列的聚合模式。
可计算中间结果的聚合模式
不可计算中间结果的聚合模式
Hive中collect相关的函数有 collect_list 和 collect_set。
它们都是将分组中的某列转为一个数组返回,不同的是 collect_list 不去重而 collect_set 去重
连接模式
分区连接,在map阶段之前
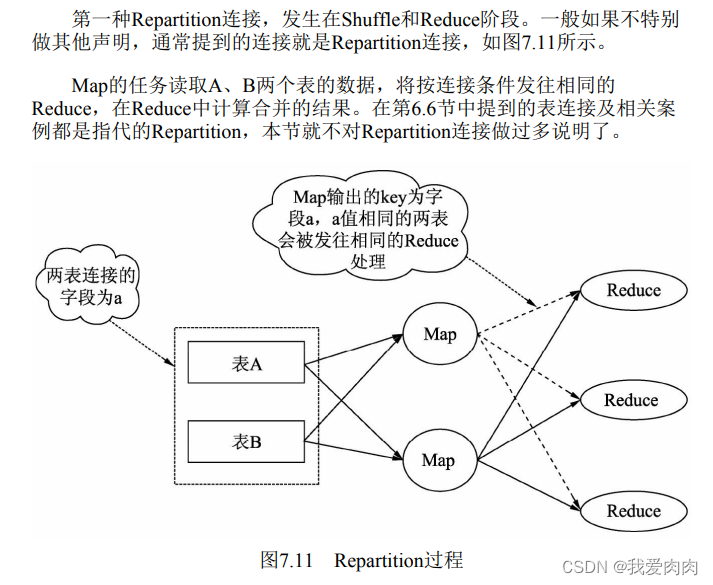
Replication连接,发生在Map阶段,又被称之为Map连接
·普通的MapJoin:对使用的表类型无特殊限制,只需要配置相应的Hive配置。
MapJoin是先启动一个作业,读取小表的数据,在内存中构建哈希表,将哈希表写入本地磁盘,
然后将哈希表上传到HDFS并添加到分布式缓存中。再启动一个任务读取B表的数据,
在进行连接时Map会获取缓存中的数据并存入到哈希表中,B表会与哈希表的数据进行匹配,
时间复杂度是O(1),匹配完后会将结果进行输出
·Bucket MapJoin:要求使用的表为桶表。
·Skewed MapJoin:要求使用的表为倾斜表。
·Sorted Merge Bucket MapJoin:要求使用的表为桶排序表。
使用方式
方式一是使用MapJoin的hint语法,但不推荐,不灵活
方式二是使用Hive配置自动判断启用MapJoin
桶连接
分桶的Hive表会将桶列的值计算Hash值取桶数的模,余数相同的会发往相同的桶,每个桶对应一个文件
倾斜连接

表连接与基于成本的优化器
自动分析优化表现主要在如下三个方面
1 表连接的顺序优化,在多表连接查询时,不需要特别指定大小表的顺序,
CBO会根据收集到的统计信息,自动算出最优的表连接顺序。
2 CBO可以基于收集到的统计信息,估算出每个表连接的组合,生成一个成本代价最低的表连接方案,
预先两两结合生成中间结果集,再针对这些中间结果集进行操作。
3 简化表的连接,在多表连接的情况下,CBO在解析SQL子句时,会识别并抽取相同的连接谓词,
并根据情况适当构造一个隐式的连接谓词作为替换,以避免高昂的表连接操作
YARN日志
ResourceManager Web UI 工作中经常会用到
数据存储
文本格式(TextFile)、二进制序列化文件(SequenceFile)、
行列式文件(RCFile)、Apache Parquet和优化的行列式文件(ORCFile)
列式存储
优点:列查询块,节省磁盘空间
缺点:需要对所有的字段进行校验过滤,在这种场景下列式存储需要花费比行式存储更多的资源,
因为行式存储读取一条数只需要一次I/O操作,而列式存储则需要花费多次,列数越多消耗的I/O资源越多
ORC
ORC列式存储的优势
ORC的行列式存储结构结合了行式和列式存储的优点,在有大数据量扫描读取时,可以按行组进行数据读取。
如果要读取某个列的数据,则可以在读取行组的基础上,读取指定的列,
而不需要读取行组内所有行的数据及一行内所有字段的数据



在Hive 0.14版本后,ORC文件能够确保Hive在工作时的原子性、一致性、
隔离性和持久性的ACID事务能够被正确地得到使用 9.1.3章节
扩展:在Hive中使用bloom过滤器,可以用较少的文件空间快速判定数据是否存在于表中,
但是也存在将不属于这个表的数据判定为属于这个这表的情况,这个情况称之为假正概率
·orc.bloom.filter.columns:需要创建布隆过滤的组。
·orc.bloom.filter.fpp:使用布隆过滤器的假正(False Positive)概率,默认值是0.05
Parquet

程序可以借助Parquet的这些元数据,在读取数据时过滤掉不需要读取的大部分文件数据,加快程序的运行速度。
同ORC的元数据一样,Parquet的这些元数据信息能够帮助提升程序的运行速度,
但是ORC在读取数据时又做了一定优化,增强了数据的读取效率
数据归档
对于HDFS中有大量小文件的表,可以通过Hadoop归档(Hadoop archive)的方式将文件归并成几个较大的文件。
归并后的分区会先创建一个data.har目录,里面包含两部分内容:索引(_index和_masterindex)和
数据(part-*)其中,索引记录归并前的文件在归并后的所在位置
--启用数据归档
set hive.archive.enabled=true;
set hive.archive.har.parentdir.settable=true;
--归档后的最大文件大小
set har.partfile.size=1099511627776;
--对分区执行归档的命令
alter table tablename archive partition(partition_col=partition_val)
--将归档的分区还原成原来的普通分区
alter table tablename unarchive partition(partition_col=partition_val)
发现并优化Hive中的性能问题
10.1 监控Hive数据库的状态
收集表的元数据,字段的元数据,所有分区的元数据
如果表太大,收集所有分区的元数据可能会导致收集超时,可以指定特定分区进行收集元数据
收集所有分区的列的元数据
(1)监控普通表存储的文件的平均大小。对于大的文件块可能导致数据在读取时产生数据倾斜,影响集群任务的运行效率
(2)监控分区存储的文件平均大小,大于两倍HDFS文件块大小的分区
(3)监控大表不分区的表。对于大数据量的表,如果不进行分区,意味着程序在读取相同的数据时需要遍历更多的文件块
(4)监控分区数据不均匀的表。分区不均匀的数据,可能意味着自己的分区列设计存在问题,或者某个分区的数据写入业务有调整,
导致数据急速上升或者下跌(如大于平均5倍)
(5)监控采用ORC或者Parquet以外格式的表。ORC和Parquet都是行列式的数据存储文件,在兼顾读写效率的同时,
也能保证数据的存储占用空间比其他文件格式更少
(6)查询有使用索引的表
(7)查询表字段的空值率,以及字段重复的占比。如果某个字段的空值率或者重复占比很高,会影响Hive的查询效率,
特别是含有表连接的查询
(8)监控分区的字段空值率,以及字段重复值的占比
(9)监控Hive表的分区数
10.2 监控当前集群状态
10.3 定位性能瓶颈
使用HS2 WebUI排除非大数据组件的问题
排查长时等待调度
Map任务读取小文件和大文件
读取可分割的大文件:如果一个文件大小远大于HDFS的文件,可能会被多个Map任务同时读取,
这时会丧失任务执行的本地化,即需要跨服务读取存储在不同服务器的文件

Reduce的数据倾斜

缓慢的Shuffle
Shuffle过程涉及磁盘的读写和网络传输,容易产生性能瓶颈,可以通过图10.10的方式来查看作业Shuffle阶段的速度

10.3.6 集群资源的限制
10.4 数据倾斜
从本质来说,导致数据倾斜有两种原因,一是任务读取大文件,二是任务需要处理大量相同键的数据。
任务读取大文件,最常见的就是读取压缩的不可分割的大文件,任务需要处理大量相同键的数据,这种情况有以下4种表现形式:
·数据含有大量无意义的数据,例如空值(NULL)、空字符串等。
·含有倾斜数据在进行聚合计算时无法聚合中间结果,大量数据都需要经过Shuffle阶段的处理,引起数据倾斜。
·数据在计算时做多维数据集合,导致维度膨胀引起的数据倾斜。
·两表进行Join,都含有大量相同的倾斜数据键
10.4.1 不可拆分大文件引发的数据倾斜
当对文件使用GZIP压缩等不支持文件分割操作的压缩方式,在日后有作业涉及读取压缩后的文件时,
该压缩文件只会被一个任务所读取。如果该压缩文件很大,则处理该文件的Map需要花费的时间会远多于读取普通文件的Map时间
在数据压缩的时候可以采用bzip2和Zip等支持文件分割的压缩算法。
10.4.2 业务无关的数据引发的数据倾斜
这些与业务无关的数据引入导致在进行分组聚合或者在执行表连接时发生数据倾斜。对于这类问题引发的数据倾斜,
在计算过程中排除含有这类“异常”数据即可
10.4.3 多维聚合计算数据膨胀引起的数据倾斜
(hive.new.job.grouping.set.cardinality)配置的方式自动控制作业的拆解,该参数默认值是30。
该参数表示针对grouping sets/rollups/cubes这类多维聚合的操作,如果最后拆解的键组合(上面例子的组合是4)大于该值,
会启用新的任务去处理大于该值之外的组合。如果在处理数据时,某个分组聚合的列有较大的倾斜,可以适当调小该值
10.4.4 无法削减中间结果的数据量引发的数据倾斜
例如使用collect_list聚合函数
问题:hive.groupby.skewindata的核心作用在于生成的第一个作业能够有效减少数量。
但是对于collect_list这类要求全量操作所有数据的中间结果的函数来说,明显起不到作用,
反而因为引入新的作业增加了磁盘和网络I/O的负担,而导致性能变得更为低下
解决:调整Reduce所执行的内存大小
10.4.5 两个Hive数据表连接时引发的数据倾斜
两表进行普通的repartition join时,如果表连接的键存在倾斜,那么在Shuffle阶段必然会引起数据倾斜。
遇到这种情况,Hive的通常做法还是启用两个作业,第一个作业处理没有倾斜的数据,
第二个作业将倾斜的数据存到分布式缓存中,分发到各个Map任务所在节点。在Map阶段完成join操作,即MapJoin,
这避免了Shuffle,从而避免了数据倾斜
Hive知识体系总结

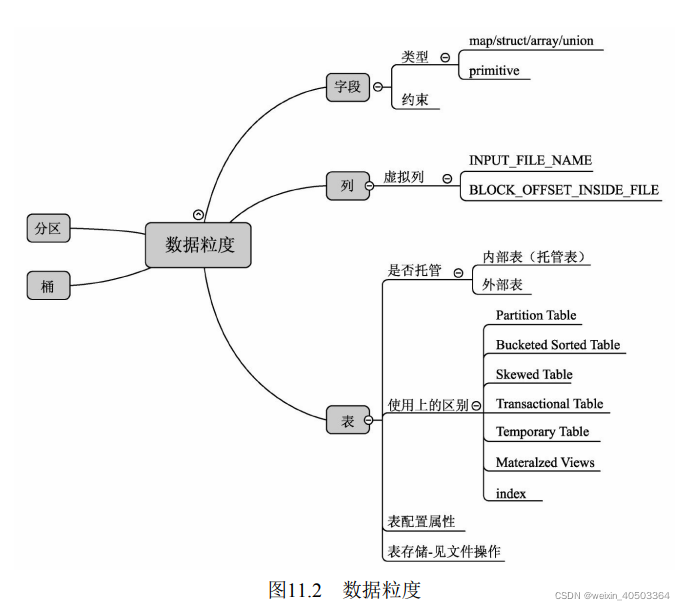
在Hive中,数据粒度可以分为表、分区、桶、列和字段


Original: https://blog.csdn.net/weixin_40503364/article/details/124546334
Author: 我爱肉肉
Title: 《Hive性能调优实战》摘录
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/818380/
转载文章受原作者版权保护。转载请注明原作者出处!