

文章目录
- 搜索相关性定义
- 字面相关性
- 语义相关性
* - 1 传统语义相关性模型
- 2 深度语义相关性模型
– - 基于Bert的语义相关性建模
* - 1 基于表示的语义匹配——Feature-based
– - 2 基于交互的语义匹配——Finetune—basd
- 3 基于BERT优化美团搜索核心排序相关性的技术架构图
搜索相关性定义
在搜索场景中,相关性定义如下:
对于给定的query和候选Doc,判断二者之间的相关性。
相关性反映了排序的精度,通过对相关性信息进行建模,将其作为特征传入到排序模型,提升搜索模型的排序能力。
相关性计算方法主要分为两种计算方法。
字面相关性
早期的相关性匹配主要是根据Term的字面匹配度来计算相关性,如字面命中、覆盖程度、TFIDF、BM25等。字面匹配的相关性特征在美团搜索排序模型中起着重要作用,但字面匹配有它的局限,主要表现在:
- 词义局限:字面匹配无法处理同义词和多义词问题,如在美团业务场景下”宾馆”和”旅店”虽然字面上不匹配,但都是搜索”住宿服务”的同义词;而”COCO”是多义词,在不同业务场景下表示的语义不同,可能是奶茶店,也可能是理发店。
- 结构局限:”蛋糕奶油”和”奶油蛋糕”虽词汇完全重合,但表达的语义完全不同。 当用户搜”蛋糕奶油”时,其意图往往是找”奶油”,而搜”奶油蛋糕”的需求基本上都是”蛋糕”。
为了解决上述问题,开始了语义相关性的探索。
语义相关性
业界工作包括传统语义匹配模型和深度语义匹配模型。
1 传统语义相关性模型
- 隐式模型:将Query、Doc都映射到同一个隐式向量空间,通过 向量相似度来计算Query-Doc相关性,例如使用主题模型LDA将Query和Doc映射到同一向量空间。
- 翻译模型:通过翻译模型将Doc进行翻译改写在和Query进行匹配。
2 深度语义相关性模型
主要包括两种,分别是基于表示的匹配和基于交互的匹配。在NLP领域中属于 文本匹配任务建模。
基于表示的匹配sentence representation
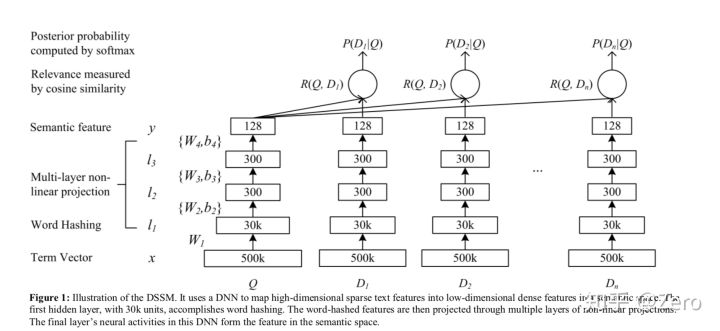
使用深度模型分别表征Query和Doc,通过计算向量相似度作为语义匹配分数。经典模型架构如微软提出的DSSM结构。
通过将Query和doc映射到同一个低维空间,计算两者相似度作为相关性。并最大化点击的条件概率。
采用softmax激活函数和logloss损失函数进行求解。

; 基于交互的匹配sentence interaction
这种和语义表示法区别在于不单独学习query和doc的表征,而是在网络层对query和doc进行交互,获取交互后的文本向量表示,最后通过MLP网络结构得到语义匹配分数。
两种方法的优缺点比较
基于表示的匹配方法:
1. 优势:Doc的语义向量可以离线预先计算,在线预测时只需要重新计算Query的语义向量
2. 缺点:模型学习时Query和Doc两者没有任何交互,不能充分利用Query和Doc的细粒度匹配信号。
基于交互的匹配方法:
- 优势在于Query和Doc在模型训练时能够进行充分的交互匹配,语义匹配效果好
- 缺点是部署上线成本较高。
基于Bert的语义相关性建模
- BERT预训练使用了大量语料, 通用语义表征能力更好。
- BERT的Transformer结构特征提取能力更强。中文BERT基于字粒度预训练,可以减少未登录词(OOV)的影响,搜索场景下存在大量长尾Query(如大量数字和英文复合Query),字粒度模型效果优于词粒度模型。
- BERT中使用位置向量建模 文本位置信息,可以解决语义匹配的 结构局限。
综上所述,我们认为BERT应用在语义匹配任务上会有更好的效果。
基于BERT的语义匹配有两种应用方式:
1 基于表示的语义匹配——Feature-based
思想
类似于DSSM双塔结构,通过BERT将Query和Doc编码为向量,Doc向量离线计算完成进入索引,Query向量线上实时计算,通过近似最近邻(ANN)等方法实现相关Doc召回。
缺点:
Feature-based方式是经过BERT得到Query和Doc的表示向量,然后计算余弦相似度,所有业务场景下Query-Doc相似度都是固定的,不利于适配不同业务场景(没法微调)。
此外,在实际场景下为海量Doc向量建立索引存储成本过高
2 基于交互的语义匹配——Finetune—basd
属于基于交互的语义匹配方法,将Query和Doc对输入BERT进行 句间关系Fine-tuning,最后通过MLP网络得到相关性分数。
通过搜索场景中用户点击数据构造训练数据,然后通过Fine-tuning方式优化Query-Doc语义匹配任务。
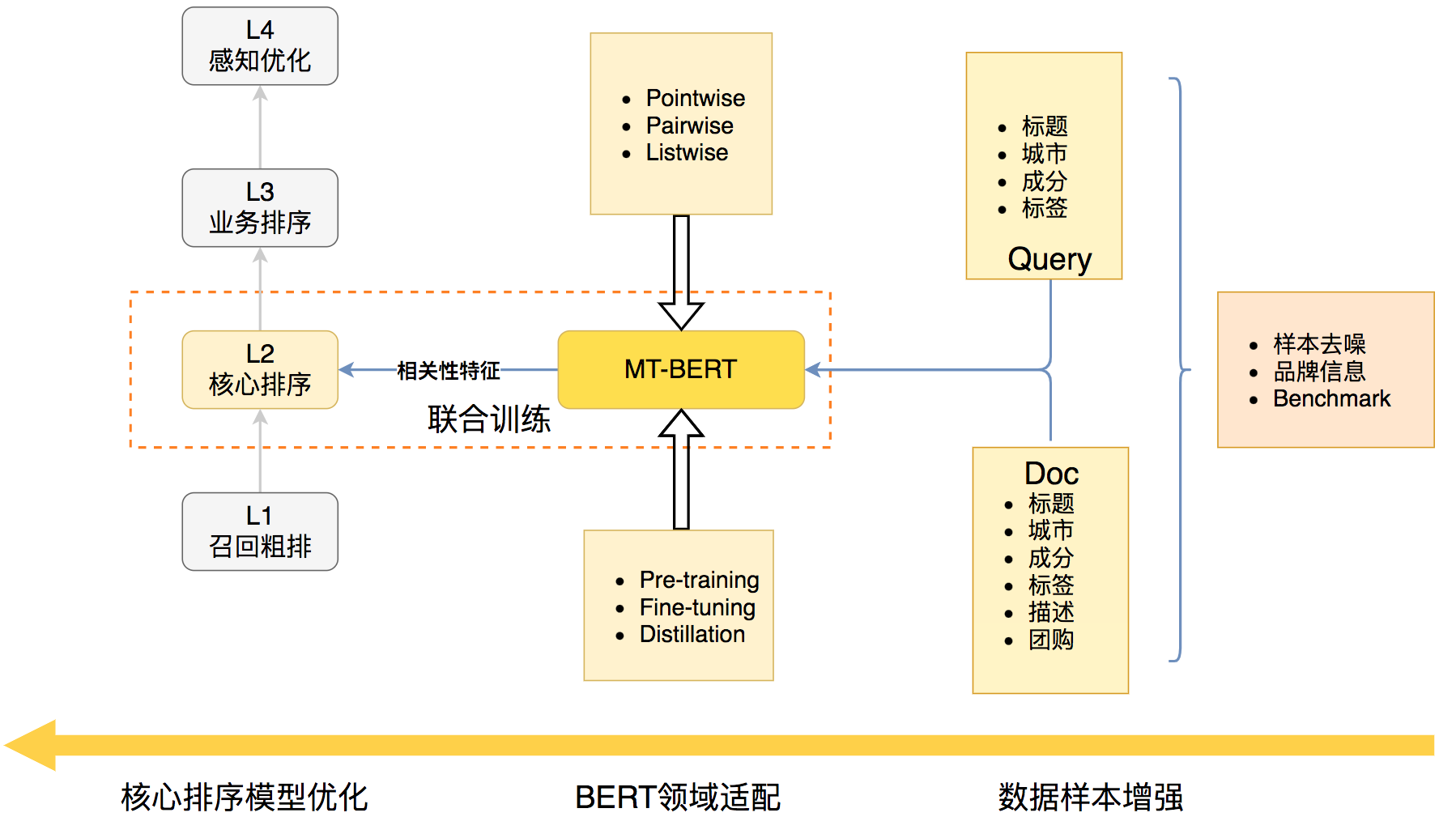
3 基于BERT优化美团搜索核心排序相关性的技术架构图
- 数据样本增强:由于相关性模型的训练基于搜索用户行为标注的弱监督数据,我们结合业务经验对数据做了去噪和数据映射。为了更好地评价相关性模型的离线效果,我们构建了一套人工标注的Benchmark数据集,指导模型迭代方向。
- BERT领域适配:美团业务场景中,Query和Doc以商户、商品、团购等短文本为主,除标题文本以外,还存在商户/商品描述、品类、地址、图谱标签等结构化信息。我们首先 改进了MT-BERT预训练方法,将品类、标签等文本信息也加入MT-BERT预训练过程中。在相关性 Fine-tuning阶段,我们对训练目标进行了优化,使得相关性任务和排序任务目标更加匹配,并进一步将两个任务结合进行联合训练。此外,由于BERT模型前向推理比较耗时,难以满足上线要求,我们通过 知识蒸馏将12层BERT模型压缩为符合上线要求的2层小模型,且无显著的效果损失。
- 排序模型优化:核心排序模型(本文记为L2模型)包括LambdaDNN[31]、TransformerDNN[3]、MultiTaskDNN等深度学习模型。给定,我们将基于BERT预测的 Query-Doc相关性分数作为特征用于L2模型的训练中。
Original: https://blog.csdn.net/weixin_42327752/article/details/123528885
Author: Weiyaner
Title: 基于Bert的语义相关性建模
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531265/
转载文章受原作者版权保护。转载请注明原作者出处!