

Spark3.0 Sql 使用HiveTableScanExec 读取Hive orc表源码分析及参数调优
1 环境准备
1.1 示例代码
import org.apache.spark.sql.SparkSession
object SparkSqlHive {
def main(args: Array[String]): Unit = {
val ss = SparkSession.builder().master("local[2]").appName("the test of SparkSession")
.config("spark.sql.hive.convertMetastoreOrc", "false")
.config("spark.hadoop.mapreduce.input.fileinputformat.split.maxsize","67108864")
.enableHiveSupport()
.getOrCreate()
ss.sql("DROP TABLE IF EXISTS temp.temp_ods_start_log");
val df = ss.sql("CREATE TABLE IF NOT EXISTS temp.temp_ods_start_log as select substr(str,1,10) as str10 from biods.ods_start_log where dt='20210721'")
df.count()
Thread.sleep(1000000)
ss.stop()
}
}
1.2 hive orc表准备
由于orc表无法加载txt数据,故先把数据加载txt表,再写入orc表。
create database biods;
create external table biods.ods_start_log
(
str string
)
comment '用户启动日志信息'
partitioned by (dt string)
stored as orc
location '/bi/ods/ods_start_log';
create external table biods.txt_ods_start_log
(
str string
)
comment '用户启动日志信息'
partitioned by (dt string)
stored as textfile
location '/bi/ods/txt_ods_start_log';
alter table biods.ods_start_log add partition(dt='20210721');
alter table biods.txt_ods_start_log add partition(dt='20210721');
load data local inpath '/home/cwc/data/start0721.log' overwrite into table biods.txt_ods_start_log partition(dt='20210721');
insert overwrite table biods.ods_start_log
partition(dt='20210721')
select str
from biods.txt_ods_start_log
where dt='20210721';
alter table biods.ods_start_log partition(dt='20210721') concatenate;
最终构造分区文件如下:
[root@hadoop3 ~]
drwxr-xr-x - root supergroup 0 2022-10-22 12:29 hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721/.hive-staging_hive_2022-10-22_12-29-16_934_837446341335257460-1
drwxr-xr-x - root supergroup 0 2022-10-22 12:29 hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721/.hive-staging_hive_2022-10-22_12-29-16_934_837446341335257460-1/-ext-10001
drwxr-xr-x - root supergroup 0 2022-10-22 12:29 hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721/.hive-staging_hive_2022-10-22_12-29-16_934_837446341335257460-1/_tmp.-ext-10002
-rwxr-xr-x 3 root supergroup 246.0 M 2022-10-25 12:18 hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721/000000_1
-rwxr-xr-x 3 root supergroup 94.1 M 2022-10-25 12:18 hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721/000001_0
文件的块大小如下,为256M
[root@hadoop3 ~]
268435456 3
[root@hadoop3 ~]
268435456 3
orc文件的stripe个数如下:
94m的文件有2个stripe, 246m的文件有11个stripe
[root@hadoop3 ~]
Processing data file hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721/000001_0 [length: 98673168]
Structure for hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721/000001_0
File Version: 0.12 with ORC_135
Rows: 3043150
Compression: ZLIB
Compression size: 262144
Type: struct<str:string>
Stripe Statistics:
Stripe 1:
Column 0: count: 2020000 hasNull: false
Column 1: count: 2020000 hasNull: false min: 2021-09-16 16:26:46.194 [main] INFO com.lagou.ecommerce.AppStart - {"app_active":{"name":"app_active","json":{"entry":"1","action":"0","error_code":"0"},"time":1595347200000},"attr":{"area":"三亚","uid":"2F10092A1723314","app_v":"1.1.2","event_type":"common","device_id":"1FB872-9A1001723314","os_type":"0.8.8","channel":"WS","language":"chinese","brand":"iphone-1"}} max: 2021-09-16 16:28:48.696 [main] INFO com.lagou.ecommerce.AppStart - {"app_active":{"name":"app_active","json":{"entry":"2","action":"1","error_code":"0"},"time":1596124800000},"attr":{"area":"铜川","uid":"2F10092A10999969","app_v":"1.1.7","event_type":"common","device_id":"1FB872-9A10010999969","os_type":"2.0","channel":"BL","language":"chinese","brand":"iphone-5"}} sum: 748218740
Stripe 2:
Column 0: count: 1023150 hasNull: false
Column 1: count: 1023150 hasNull: false min: 2021-09-16 16:26:32.958 [main] INFO com.lagou.ecommerce.AppStart - {"app_active":{"name":"app_active","json":{"entry":"1","action":"0","error_code":"0"},"time":1595260800000},"attr":{"area":"乳山","uid":"2F10092A727865","app_v":"1.1.19","event_type":"common","device_id":"1FB872-9A100727865","os_type":"9.7.7","channel":"HA","language":"chinese","brand":"Huawei-3"}} max: 2021-09-16 16:28:35.297 [main] INFO com.lagou.ecommerce.AppStart - {"app_active":{"name":"app_active","json":{"entry":"2","action":"1","error_code":"0"},"time":1596038400000},"attr":{"area":"深圳","uid":"2F10092A9999986","app_v":"1.1.2","event_type":"common","device_id":"1FB872-9A1009999986","os_type":"0.4.6","channel":"LD","language":"chinese","brand":"Huawei-6"}} sum: 378150821
File Statistics:
Column 0: count: 3043150 hasNull: false
Column 1: count: 3043150 hasNull: false min: 2021-09-16 16:26:32.958 [main] INFO com.lagou.ecommerce.AppStart - {"app_active":{"name":"app_active","json":{"entry":"1","action":"0","error_code":"0"},"time":1595260800000},"attr":{"area":"乳山","uid":"2F10092A727865","app_v":"1.1.19","event_type":"common","device_id":"1FB872-9A100727865","os_type":"9.7.7","channel":"HA","language":"chinese","brand":"Huawei-3"}} max: 2021-09-16 16:28:48.696 [main] INFO com.lagou.ecommerce.AppStart - {"app_active":{"name":"app_active","json":{"entry":"2","action":"1","error_code":"0"},"time":1596124800000},"attr":{"area":"铜川","uid":"2F10092A10999969","app_v":"1.1.7","event_type":"common","device_id":"1FB872-9A10010999969","os_type":"2.0","channel":"BL","language":"chinese","brand":"iphone-5"}} sum: 1126369561
Stripes:
Stripe: offset: 3 data: 65480370 rows: 2020000 tail: 46 index: 21746
Stream: column 0 section ROW_INDEX start: 3 length 34
Stream: column 1 section ROW_INDEX start: 37 length 21712
Stream: column 1 section DATA start: 21749 length 64216148
Stream: column 1 section LENGTH start: 64237897 length 1264222
Encoding column 0: DIRECT
Encoding column 1: DIRECT_V2
Stripe: offset: 65502165 data: 33158620 rows: 1023150 tail: 46 index: 11309
Stream: column 0 section ROW_INDEX start: 65502165 length 29
Stream: column 1 section ROW_INDEX start: 65502194 length 11280
Stream: column 1 section DATA start: 65513474 length 32518042
Stream: column 1 section LENGTH start: 98031516 length 640578
Encoding column 0: DIRECT
Encoding column 1: DIRECT_V2
File length: 98673168 bytes
Padding length: 0 bytes
Padding ratio: 0%


2 HiveTableScanExec读取orc表分析
根据driver端日志分析,最早是在 OrcInputFormat中生成split, 最终调度task读取orc表 生成 HadoopRDD.cala
22/10/27 23:46:59 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on LAPTOP-NDJFRBI4:57758 (size: 24.3 KiB, free: 4.0 GiB)
22/10/27 23:46:59 INFO SparkContext: Created broadcast 0 from
22/10/27 23:47:00 INFO HadoopRDD: Input split: OrcSplit [hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721/000000_1, start=130975043, length=126979143, isOriginal=true, fileLength=257955207, hasFooter=false, hasBase=true, deltas=[]]
22/10/27 23:47:00 INFO HadoopRDD: Input split: OrcSplit [hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721/000000_1, start=3, length=130975040, isOriginal=true, fileLength=257955207, hasFooter=false, hasBase=true, deltas=[]]
22/10/27 23:47:00 INFO OrcInputFormat: Using column configuration variables columns [str] / columns.types [string] (isAcidRead false)
2.1 于是来到 OrcInputFormat#generateSplitsInfo
org.apache.hadoop.hive.ql.io.orc.OrcInputFormat#generateSplitsInfo
static List generateSplitsInfo(Configuration conf, Context context)
throws IOException {
// 对应打印日志的地方
if (LOG.isInfoEnabled()) {
LOG.info("ORC pushdown predicate: " + context.sarg);
}
....
for (SplitStrategy splitStrategy : splitStrategies) {
if (isDebugEnabled) {
LOG.debug("Split strategy: {}", splitStrategy);
}
// Hack note - different split strategies return differently typed lists, yay Java.
// This works purely by magic, because we know which strategy produces which type.
if (splitStrategy instanceof ETLSplitStrategy) {
//--------------------- 生成splitFutures,用于异步生成split--------------------------
scheduleSplits((ETLSplitStrategy)splitStrategy,
context, splitFutures, strategyFutures, splits);
} else {
@SuppressWarnings("unchecked")
List readySplits = (List)splitStrategy.getSplits();
splits.addAll(readySplits);
}
}
}
// Run the last combined strategy, if any.
if (combinedCtx != null && combinedCtx.combined != null) {
scheduleSplits(combinedCtx.combined, context, splitFutures, strategyFutures, splits);
combinedCtx.combined = null;
}
// complete split futures
for (Future ssFuture : strategyFutures) {
ssFuture.get(); // Make sure we get exceptions strategies might have thrown.
}
// All the split strategies are done, so it must be safe to access splitFutures.
for (Future> splitFuture : splitFutures) {
//--------------------- 等待splitFuture 执行完成,获得split,详见下面SplitGenerator的call方法--------------------------
splits.addAll(splitFuture.get());
}
} catch (Exception e) {
cancelFutures(pathFutures);
cancelFutures(strategyFutures);
cancelFutures(splitFutures);
throw new RuntimeException("ORC split generation failed with exception: " + e.getMessage(), e);
}
if (context.cacheStripeDetails) {
LOG.info("FooterCacheHitRatio: " + context.cacheHitCounter.get() + "/"
+ context.numFilesCounter.get());
}
if (isDebugEnabled) {
for (OrcSplit split : splits) {
LOG.debug(split + " projected_columns_uncompressed_size: "
+ split.getColumnarProjectionSize());
}
}
return splits;
}
2.2 于是重点进 OrcInputFormat#scheduleSplits 看,如何生成splitfuture
org.apache.hadoop.hive.ql.io.orc.OrcInputFormat#scheduleSplits
private static void scheduleSplits(ETLSplitStrategy splitStrategy, Context context,
List<Future<List<OrcSplit>>> splitFutures, List<Future<Void>> strategyFutures,
List<OrcSplit> splits) throws IOException {
Future<Void> ssFuture = splitStrategy.generateSplitWork(context, splitFutures, splits);
if (ssFuture == null) return;
strategyFutures.add(ssFuture);
}
org.apache.hadoop.hive.ql.io.orc.OrcInputFormat.ETLSplitStrategy#generateSplitWork
2.3 进入 OrcInputFormat.ETLSplitStrategy#runGetSplitsSync
org.apache.hadoop.hive.ql.io.orc.OrcInputFormat.ETLSplitStrategy#runGetSplitsSync
private void runGetSplitsSync(List<Future<List<OrcSplit>>> splitFutures,
List<OrcSplit> splits, UserGroupInformation ugi) throws IOException {
UserGroupInformation tpUgi = ugi == null ? UserGroupInformation.getCurrentUser() : ugi;
List<SplitInfo> splitInfos = getSplits();
List<Future<List<OrcSplit>>> localListF = null;
List<OrcSplit> localListS = null;
for (SplitInfo splitInfo : splitInfos) {
SplitGenerator sg = new SplitGenerator(splitInfo, tpUgi, allowSyntheticFileIds);
if (!sg.isBlocking()) {
if (localListS == null) {
localListS = new ArrayList<>(splits.size());
}
localListS.addAll(sg.call());
} else {
if (localListF == null) {
localListF = new ArrayList<>(splits.size());
}
localListF.add(Context.threadPool.submit(sg));
}
}
if (localListS != null) {
synchronized (splits) {
splits.addAll(localListS);
}
}
if (localListF != null) {
synchronized (splitFutures) {
splitFutures.addAll(localListF);
}
}
}
}
org.apache.hadoop.hive.ql.io.orc.OrcInputFormat.SplitGenerator
org.apache.hadoop.hive.ql.io.orc.OrcInputFormat.SplitGenerator#call
org.apache.hadoop.hive.ql.io.orc.OrcInputFormat.SplitGenerator#callInternal
2.4 (重点)进入 OrcInputFormat.SplitGenerator#generateSplitsFromStripes
org.apache.hadoop.hive.ql.io.orc.OrcInputFormat.SplitGenerator#generateSplitsFromStripes
通过orc文件的stripe 生成split,是以stripe 为基本单位,组装成spllt, 而不会继续分割stripe
private List<OrcSplit> generateSplitsFromStripes(boolean[] includeStripe) throws IOException {
List<OrcSplit> splits = new ArrayList<>(stripes.size());
if (stripes == null || stripes.isEmpty()) {
splits.add(createSplit(0, file.getLen(), orcTail));
} else {
if (includeStripe == null) {
includeStripe = new boolean[stripes.size()];
Arrays.fill(includeStripe, true);
}
OffsetAndLength current = new OffsetAndLength();
int idx = -1;
for (StripeInformation stripe : stripes) {
idx++;
if (!includeStripe[idx]) {
if (current.offset != -1) {
splits.add(createSplit(current.offset, current.length, orcTail));
current.offset = -1;
}
continue;
}
current = generateOrUpdateSplit(
splits, current, stripe.getOffset(), stripe.getLength(), orcTail);
}
generateLastSplit(splits, current, orcTail);
}
splits.addAll(deltaSplits);
return splits;
}
2.5 (重点)进入** OrcInputFormat.SplitGenerator#generateOrUpdateSplit
org.apache.hadoop.hive.ql.io.orc.OrcInputFormat.SplitGenerator#generateOrUpdateSplit
private OffsetAndLength generateOrUpdateSplit(
List<OrcSplit> splits, OffsetAndLength current, long offset,
long length, OrcTail orcTail) throws IOException {
if (current.offset != -1 && current.length > context.minSize &&
(current.offset / blockSize != offset / blockSize)) {
splits.add(createSplit(current.offset, current.length, orcTail));
current.offset = -1;
}
if (current.offset == -1) {
current.offset = offset;
current.length = length;
} else {
current.length = (offset + length) - current.offset;
}
if (current.length >= context.maxSize) {
splits.add(createSplit(current.offset, current.length, orcTail));
current.offset = -1;
}
return current;
}
2.6 总结一下,调用关系如下:
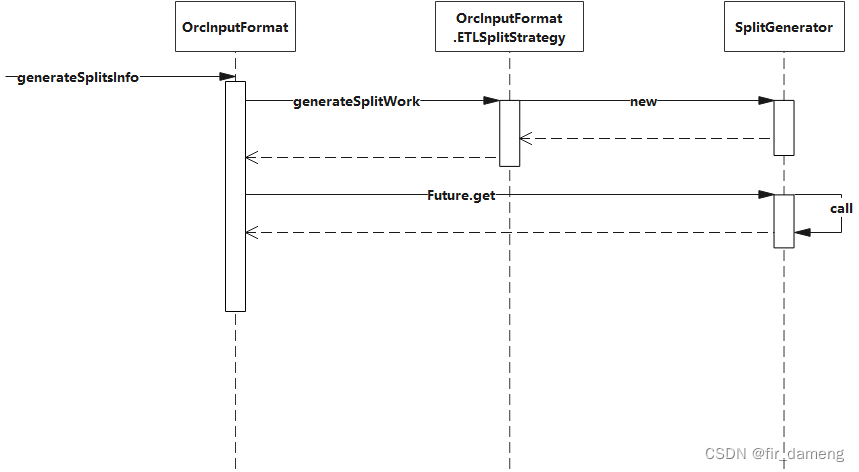
其中context.minSize,context.maxSize定义如下 :
org.apache.hadoop.hive.ql.io.orc.OrcInputFormat.Context#Context(org.apache.hadoop.conf.Configuration, int, org.apache.hadoop.hive.ql.io.orc.ExternalCache.ExternalFooterCachesByConf)
minSize = HiveConf.getLongVar(conf, ConfVars.MAPREDMINSPLITSIZE, DEFAULT_MIN_SPLIT_SIZE);
maxSize = HiveConf.getLongVar(conf, ConfVars.MAPREDMAXSPLITSIZE, DEFAULT_MAX_SPLIT_SIZE);

mapreduce.input.fileinputformat.split.minsize=1
mapreduce.input.fileinputformat.split.maxsize= 256M
因此,默认情况下,切片大小=blocksize。因为一般文件的block大小为128M, 是小于mapreduce.input.fileinputformat.split.maxsize默认值的
根据orc文件的stripe,结合参数配置,最终生成split
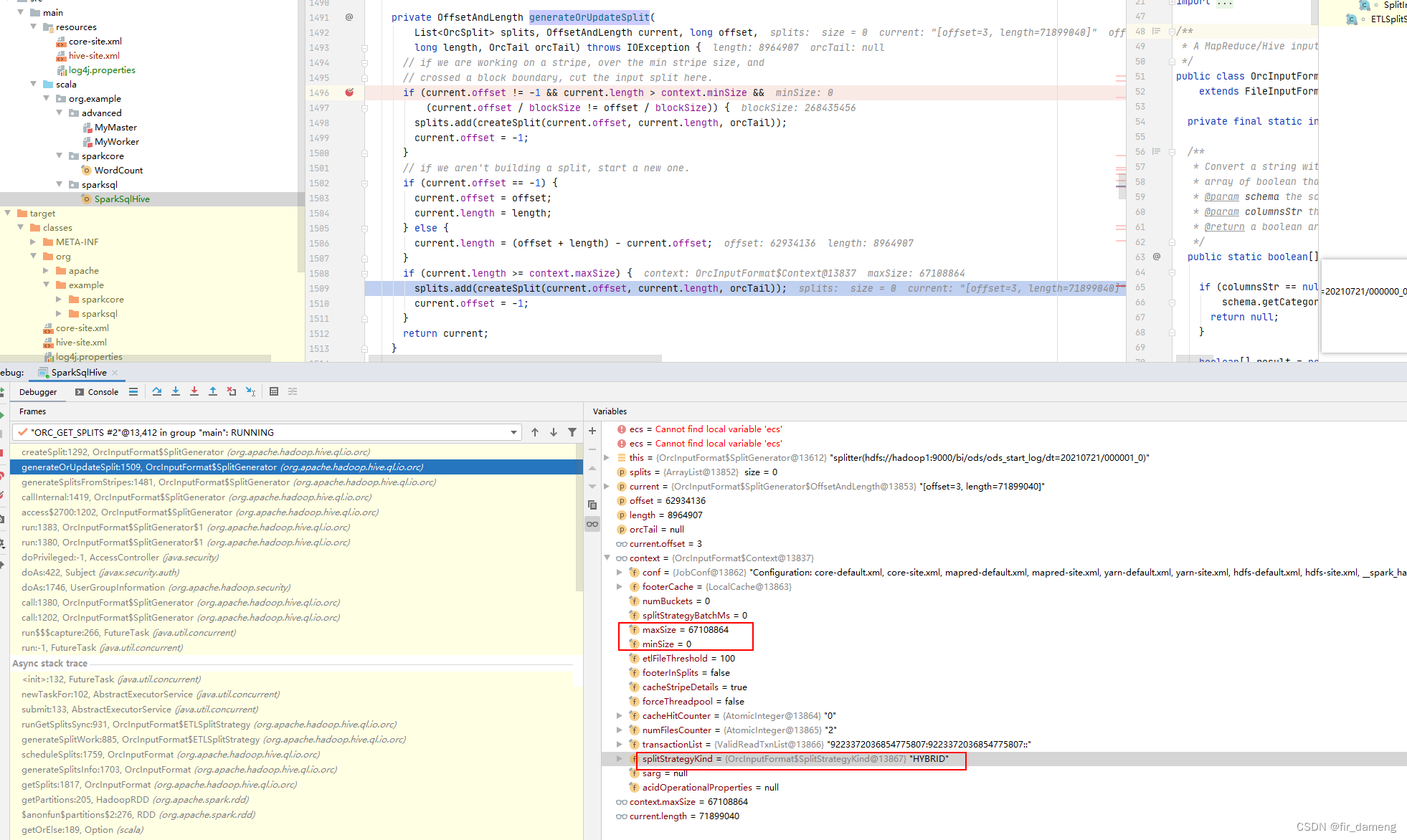
结论: 因此使用 "spark.hadoop.mapreduce.input.fileinputformat.split.maxsize" 能够控制生成split个数,进而控制读取的map task数量
小疑问:为什么设置
spark.hadoop.mapreduce.input.fileinputformat.split.maxsize最后怎么生效成mapreduce.input.fileinputformat.split.maxsize?
答案在org.apache.spark.deploy.SparkHadoopUtil#appendSparkHadoopConfigs中,创建Sparkcontext时,,将spark.hadoop开头的参数截取后面部分,设置为hadoop的参数
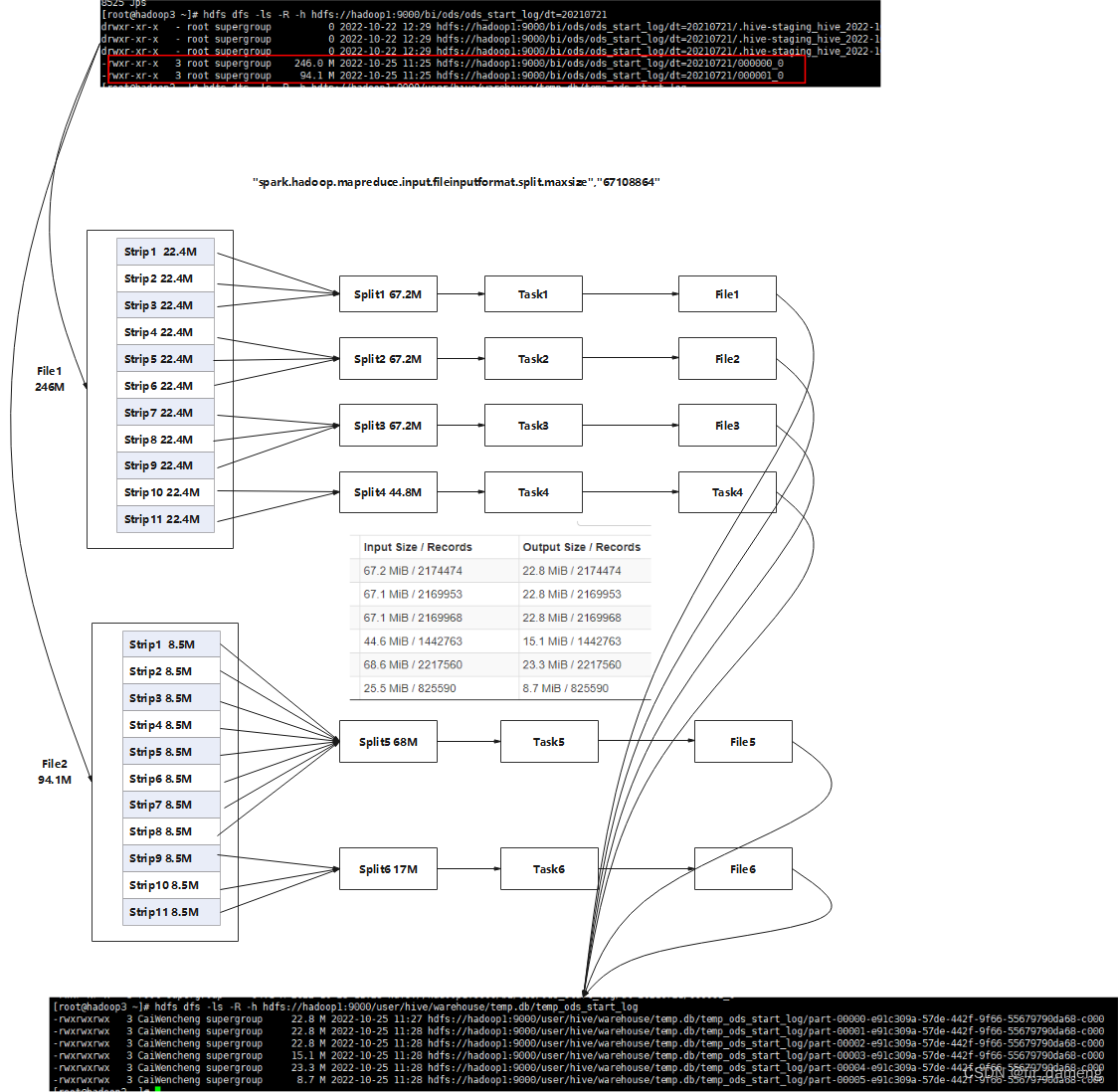
以下为设置 "spark.hadoop.mapreduce.input.fileinputformat.split.maxsize"为 "67108864"时,spark sql 读取orc文件的示意图
3、总结
(1)通过orc文件的stripe 生成split,是以stripe 为基本单位,组装成spllt, 而不会继续分割stripe
(2)默认情况下,split大小=文件blocksize。因为一般文件的block大小为128M, 是小于mapreduce.input.fileinputformat.split.maxsize默认值256M
(3)当使用 "spark.hadoop.mapreduce.input.fileinputformat.split.maxsize" 小于自身文件block值时,能够提高生成split个数,进而提高读取的map task数量
4、遗留问题
orc表文件中的stripe是如何生成的?
https://www.jianshu.com/p/0ba4f5c3f113
https://cloud.tencent.com/developer/article/1580677
https://blog.csdn.net/dante_003/article/details/79245240
Original: https://blog.csdn.net/u014034497/article/details/127543274
Author: fir_dameng
Title: Spark3.0 Sql 使用HiveTableScanExec 读取Hive orc表源码分析及参数调优
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/817283/
转载文章受原作者版权保护。转载请注明原作者出处!