

前言:不是每个网页都能模拟成功,仅供学习
模拟网页登陆
–安装模块–
pip install urllib (运行cmd输入此段代码即可安装)
点击查看代码
from urllib import request
import urllib
from http import cookiejar
定义文件名
filename = 'cookie.txt'
声明一个cookie,传入文件名
cookie = cookiejar.MozillaCookieJar(filename)
定义cookie处理
handler = request.HTTPCookieProcessor(cookie)
定义下载器,传入处理器
opener = request.build_opener(handler)
定义登录用的账号密码
postdata = urllib.parse.urlencode({
'username': '账号',
'password': '密码'
}).encode(encoding='UTF8')
url
loginUrl = '网站'
模拟登录页面
resp = opener.open(loginUrl, postdata)
保存cookie到文件
cookie.save(ignore_discard=True, ignore_expires=True)
再次访问网站
url2 = "网站"
打开页面
try:
result = opener.open(url2)
except request.HTTPError as e:
if hasattr(e, "code"):
print(e.code)
except request.URLError as e:
if hasattr(e, "reason"):
print(e.reason)
else:
print(result.read())
正则表达式
了解正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个”规则字符串”,这个”规则字符串”用来表达对字符串的一种过滤逻辑。
安装模块
pip install re (运行cmd输入此段代码即可安装)
import re
将正则表达式编译成Pattern对象,注意hello前面的r的意思是”原生字符串”
pattern = re.compile(r’hello’)
使用re.match匹配文本,获得匹配结果,无法匹配时将返回None
result1 = re.match(pattern,’hello’)
result2 = re.match(pattern,’helloo YC!’)
result3 = re.match(pattern,’helo YC!’)
result4 = re.match(pattern,’hello YC!’)
match表示从头开始匹配 匹配不到返回none
search可以从任意位置匹配
认识匹配规则字符:
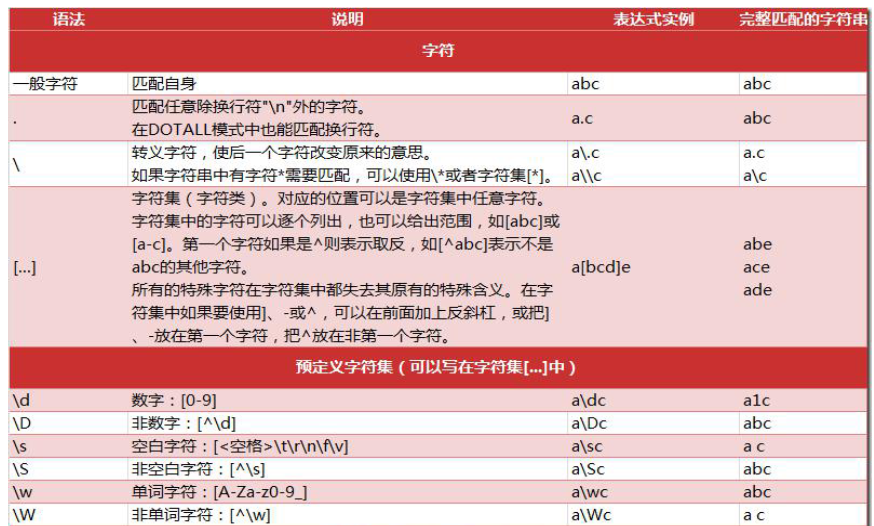

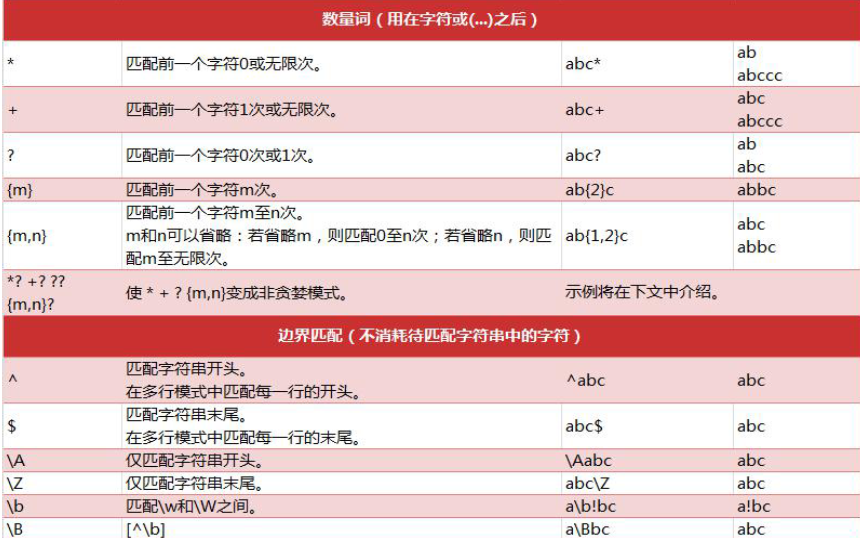
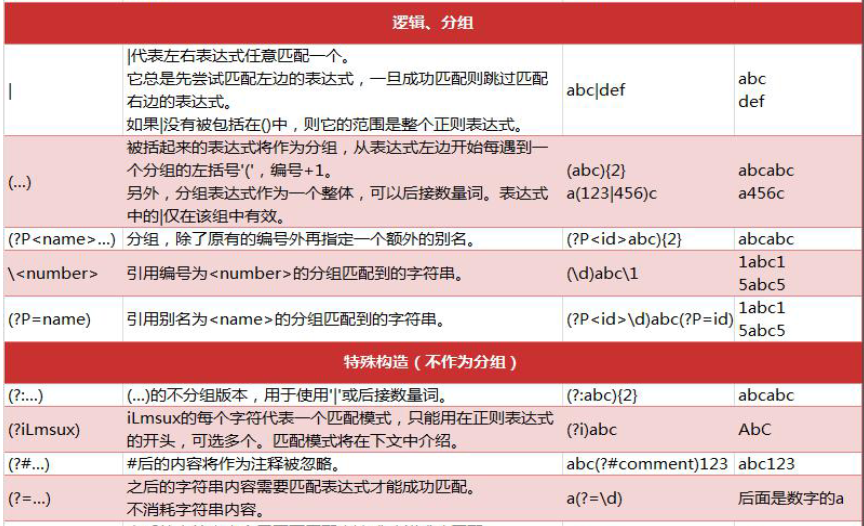
点击查看代码
import re
定义正则化规则=匹配模式,r表示原生字符串
rexg = re.compile(r'\d*\w*')
res = re.search(rexg, '555555555ddddddddddddd5')
print(res)
rexg1 = re.compile(r'\d+\w*')
res1 = re.search(rexg1, 'ppppp555555555ddddddddddddd5')
print(res1)
rexg2 = re.compile(r'\d?dddddd')
res2 = re.search(rexg2, 'ppppp555555555ddddddddddddd5')
print(res2)
电话号码
rexg3 = re.compile(r'1\d{10}')
res3 = re.search(rexg3, '13865256323')
print(res3)
定义邮箱
rexg4 = re.compile(r'\d{5,12}@\w{2}\.\w{3}')
res4 = re.search(rexg4, '1sdfsdfdsfdsdfs647709191@qq.com')
print(res4)
rexg5 = re.compile(r'\d+')
res5 = re.search(rexg5, '11sdfsdfdsfdsdfs647709191@qq.com')
print(res5)
rexg6 = re.compile(r'\d{5,12}? ?')
res6 = re.search(rexg6, '11sdfsdfdsfdsdfs6477d09191@qq.com')
print(res6)
边界匹配-匹配字符串开头
rexg7 = re.compile(r'\Aabc')
res7 = re.search(rexg7, 'abcqqqqqqqqqabccttttttttttt'
'abcctttttttttabc')
print(res7)
任意
rexg8 = re.compile(r'1\d{10}|\d{5,12}@\w{2}\.\w{3}')
res8 = re.search(rexg8, "sahsyhs1d8285555556gashgshasdag12345@qq.com")
print(res8)
分组
rexg9 = re.compile(r'(abc){3}')
res9 = re.search(rexg9, "zUJXHUJHXuabcabcabcosaojaodiabcosajosabc")
print(res9)
分组 + 别名
rexg10 = re.compile(r'(?P<tt>abc)888(?P=tt)')
res10 = re.search(rexg10, "hasghsabc888abc")
print(res10)
分组 + 编号
rexg11 = re.compile(r'(\d{5})uu\1')
res11 = re.search(rexg11, "12345uu12345")
print(res11)
</tt>
Original: https://www.cnblogs.com/wei3306/p/16000998.html
Author: N暖阳_李维宁
Title: pyhon爬虫模拟网页登陆、正则表达式
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/814742/
转载文章受原作者版权保护。转载请注明原作者出处!