

Scrapy Shell
我们想要在爬虫中使用xpath、beautifulsoup、正则表达式、css选择器等来提取想要的数据。但是因为 scrapy是一个比较重的框架。每次运行起来都要等待一段时间。因此要去验证我们写的提取规则是否正确,是一个比较麻烦的事情。因此 Scrapy提供了一个shell,用来方便的测试规则。当然也不仅仅局限于这一个功能。
打开Scrapy Shell
打开cmd终端,进入到 Scrapy项目所在的目录,然后进入到 scrapy框架所在的虚拟环境中,输入命令 scrapy shell [链接]。就会进入到scrapy的shell环境中。在这个环境中,你可以跟在爬虫的 parse方法中一样使用了。
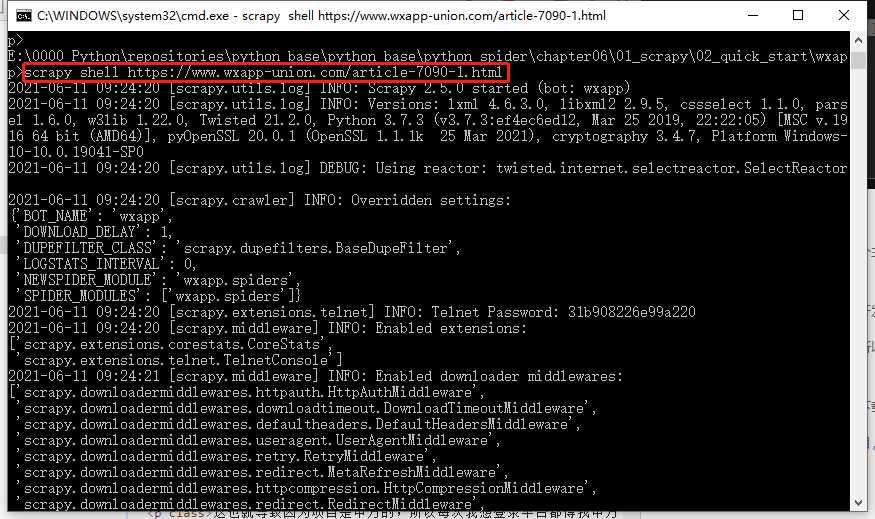

查询获取到的网页信息:
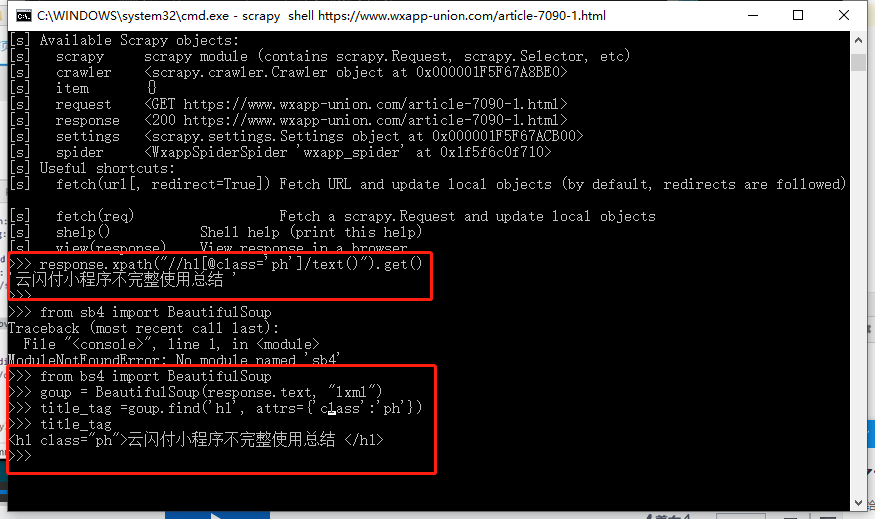
总结:
1、可以方便我们做一些数据提取的测试代码
2、如果想要执行scrapy 命令, 那么肯定要先进入到 scrapy 所在的环境中。
3、如果想要读取某个项目的配置信息,那么应该先进入到项目中,再执行 scrapy shell 命令。
更多内容有待研究。。。
Original: https://blog.csdn.net/qq_30346413/article/details/117768325
Author: 思想流浪者
Title: python_爬虫 18 Scrapy框架之(四)Scrapy Shell
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/792796/
转载文章受原作者版权保护。转载请注明原作者出处!