

在前面的几章中,我们了解了如何开发Scrapy爬虫。当我们对爬虫的功能感到满意时,接下来会有两个选项。如果我们需要的只是使用它们执行简单的抓取工作,那么此时使用开发机运行即可。而另一方面,更常见的情况是需要周期性地运行抓取任务,此时可以使用云服务器,如Amazon、RackSpace或其他提供商,不过这些都需要创建、配置和维护工作。此时就是Scrapinghub发挥作用的时候了。
Scrapinghub是Scrapy托管的Amazon服务器,它是由Scrapy开发者创建的Scrapy云基础设施提供商。它是一个付费服务,不过也提供了免费方案。如果你想在几分钟内,就能够让Scrapy爬虫运行在专业的创建和维护环境中的话,那么本章非常适合你。
第一步是在 http://scrapinghub.com/上面创建账号。我们所需填写的只有邮箱地址和密码。在单击确认邮件的链接后,就可以登录到其服务中。我们可以看到的第一个页面是个人面板。目前,我们还没有任何项目,因此现在单击 +Service按钮(1)来创建一个项目,如图6.1所示。
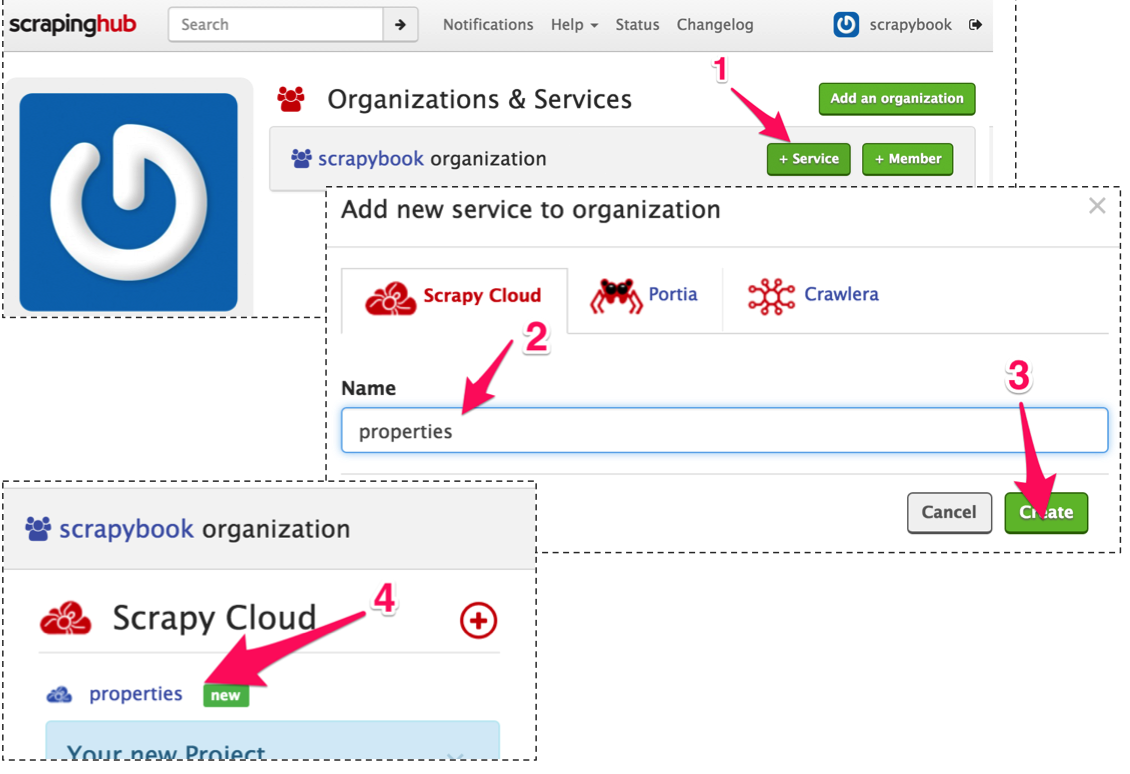

图6.1 在scrapinghub上创建新项目
将项目命名为 properties(2),然后单击 Create按钮(3
Original: https://blog.csdn.net/rmyd01/article/details/118604613
Author: 人民邮电出版社有限公司
Title: 《精通Python爬虫框架Scrapy》第6章 部署到Scrapinghub
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/792511/
转载文章受原作者版权保护。转载请注明原作者出处!