

目录
2.1.6 以Series 作为分组字段,根据索引对记录进行映射分组
2.1.7 以函数作为分组字段,根据函数对索引的执行结果进行分组
大家如果用过数据库,肯定对 group by 命令很熟悉,Pandas 的 .groupby() 函数作用和数据库中的 group by 非常相似。它会将 DataFrame 数据根据一定的规则进行分组,返回给用户一个 groupby 对象,这个对象包括了不同组的相关信息。
参考官方给的原文:


其中:
- split:按照某给定的原则(groupby字段)进行拆分,相同属性分为一组
- apply:对拆分后的各组执行相应的独立的转换操作
apply 的概念,可以参考这篇文章:Pandas 模块-操纵数据(6)-DataFrame 使用自定义函数
-
combine:将结果转换成一定的数据结构(汇总功能)并输出
-
.groupby() 语法
1.1 .groupby() 语法结构
DataFrame.groupby(by=None, axis=0, level=None, as_index: ‘bool’ = True, sort: ‘bool’ = True, group_keys: ‘bool’ = True, squeeze: ‘bool’ =
DataFrame.groupby 会将 DataFrame 数据根据一定的规则进行分组,返回给用户一个 groupby 对象,这个对象包括了不同组的相关信息。具体的 groupby 操作涉及拆分对象,应用函数并合并结果等。
参考如下:
Help on method groupby in module pandas.core.frame:
groupby(by=None, axis=0, level=None, as_index: 'bool' = True, sort: 'bool' = True, group_keys: 'bool' = True, squeeze: 'bool' = , observed: 'bool' = False, dropna: 'bool' = True) -> 'DataFrameGroupBy' method of pandas.core.frame.DataFrame instance
Group DataFrame using a mapper or by a Series of columns.
A groupby operation involves some combination of splitting the
object, applying a function, and combining the results. This can be
used to group large amounts of data and compute operations on these
groups.
Parameters
----------
by : mapping, function, label, or list of labels
Used to determine the groups for the groupby.
If 1.2 .groupby() 参数说明
- by : 可以是映射, 函数, 标签或者标签列表,用于指定 groupby 的组。
如果 by 是函数,它会按照 index 调用每一个值。
如果 by 是字典或者 Series ,它们的值将用于决定组(Series 的值会第一个对齐,参看 .align() method)。
如果 by 是 ndarray,这个值将用于 as-is 以决定分组。
如果 by 是标签或者标签列表,将会被用于根据相应的列进行分组。
如果 by 是tuple 元组类型,那么将会被视作一个单独的 key 。 - axis :可以是 {0 or ‘index’, 1 or ‘columns’}, 默认为 0 。决定是按照行还是列进行切割。
- level : 可以是 int 数值,level 名称,或者相关的序列。默认为 None。 如果 axis 是一个多级索引,那么可以按照一个特定的 level 或者特定的多级 level 进行分组。
- as_index : 布尔值,是否将分组列名作为输出的索引,默认为True;当设置为False时相当于加了reset_index功能
- sort :布尔值,默认为 True。是对组排序的关键。如果想要更好的性能,可以关掉它。请注意,这个并不影响每个组的内在顺序, Groupby 保留每个组中的行顺序。
- group_keys :布尔值, default True When calling apply, add group keys to index to identify pieces。
-
dropna:True or False ,默认为True,为真则删除含有空值的行和列。
-
.groupby() 范例
准备数据
import random
random.seed()
df = pd.DataFrame({'str':['a', 'a', 'b', 'b', 'a'],
'no':['one', 'two', 'one', 'two', 'one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df

2.1 分组字段:by
2.1.1 单列作为分组字段,不设置索引
grouped=df.groupby('str')
返回的是一个 DataFrameGroupBy 对象,可以看到其内存。

通过 list 命令看内容,已经按照 str 列表的数据(a,b)将原始 DataFrame 的内容进行了分组。

得到这个对象只是第一步,我们往往要得到相关信息,如每个组,中位数,最大值等,即 apply 后的结果。
grouped.data1.sum() #每组的 data1 的总和

grouped.data1.max() #每组的 data1 的最大值

我们可以利用 for 循环对分好的组进行遍历
for name,group in grouped:
print(type(name))
print(name)
print(type(group))
print(group)

此外对 DataFrameGroupBy 对象常用的操作很多,如:
aggregate:Aggregate using one or more operations over the specified axis.
apply :Apply function func group-wise | and combine the results together.
transform :Aggregate using one or more | operations over the specified axis.
本文篇幅有限,会在后续说,此处不再多说。
2.1.2 单列字段的数据转换一下作为分组字段
例如# 以 no 的长度作为分组依据,因为长度都是3,得到一组
以 no 的长度作为分组依据,因为长度都是3,得到一组
grouped=df.groupby(df['no'].str.len())
list(grouped)

以 no 第一个字符作为分组依据
以 no 第一个字符作为分组依据,分为 0 组 和 t 组
grouped=df.groupby(df['no'].str[0])
list(grouped)

2.1.4 以多列作为分组字段
例如
以 "str","no"o 作为分组依据,分为 4 组
grouped=df.groupby(["str","no"])
list(grouped)

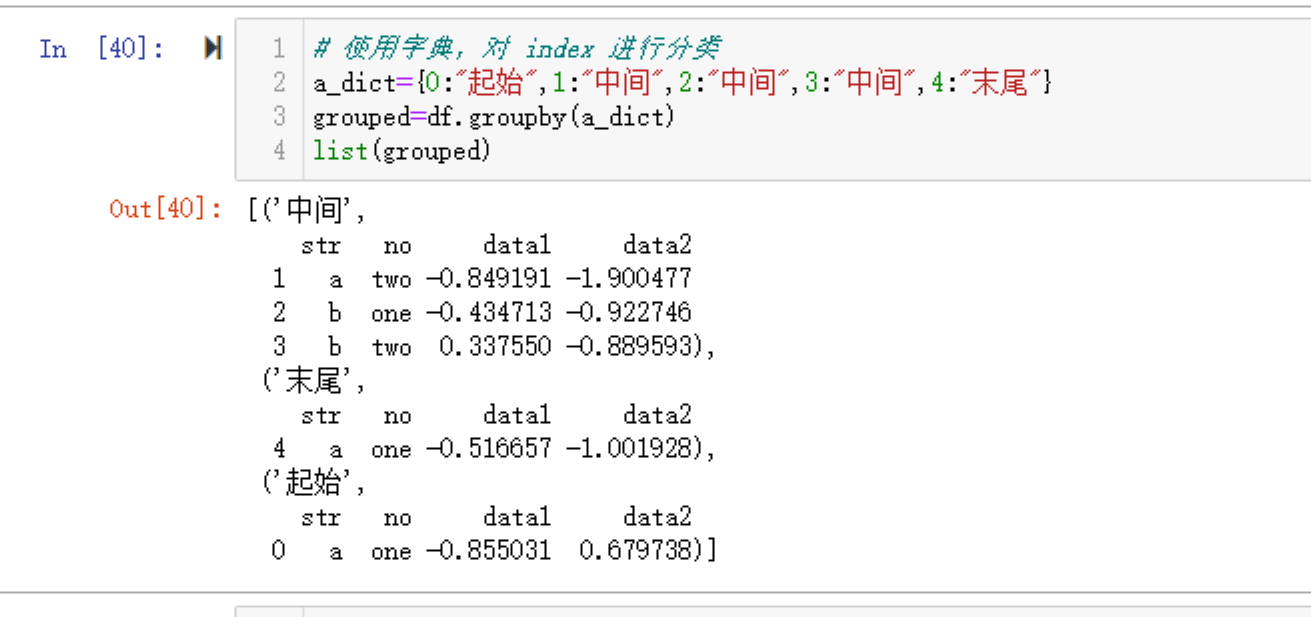
2.1.5 以字典作为分组字段,根据索引对记录进行映射分组
例如
使用字典,对 index 进行分类
a_dict={0:"起始",1:"中间",2:"中间",3:"中间",4:"末尾"}
grouped=df.groupby(a_dict)
list(grouped)
2.1.6 以Series 作为分组字段,根据索引对记录进行映射分组
使用 series,对 index 进行分类,结果类似于以字典作为分组字段
使用 series,对 index 进行分类
a_dict={0:"起始",1:"中间",2:"中间",3:"中间",4:"末尾"}
a_series=pd.Series(a_dict)
grouped=df.groupby(a_series)
list(grouped)
运行结果

2.1.7 以函数作为分组字段,根据函数对索引的执行结果进行分组
使用函数,对 index 进行分类
grouped=df.groupby(lambda x: True if x%2!=0 else False)
list(grouped)
运行结果

2.2 轴:axis
请看 2.3 level 小节。
2.3 级别:level
准备测试数据
columns=pd.MultiIndex.from_arrays([['China','China','China','Japan','Japan'],
["1","2","3","1","2"]],names=['Country','no'])
hier_df=pd.DataFrame(abs(np.random.randn(4,5)*1000),columns=columns)

默认的 axis=0,即按照行来进行分组,如果 axis =1 即按照列来进行分组,但是什么情况下按列分组呢。往往是对多级别的列表进行分组时候。如下这个范例,有两个列级别,第一个是 Country,第二个 是 no。
按照 level=’Country’,axis=1 即按照列来分组数据
list(hier_df.groupby(level='Country',axis=1))

按照 level=’no’,axis=1 即按照列来分组数据
按照 level='no',axis=1 即按照列来分组数据

2.4 是否保留 index 名:as_index
as_index : 布尔值,是否将分组列名作为输出的索引,默认为 True ;当设置为 False 时相当于加了reset_index功能。
1) 请注意,as_index 只有在 axis=0 时候有效,否则就会报错。

2) 请注意,as_index 一般在使用聚合函数时候有体现,用 list 或者 for 循环时候是看不出来差异的。
使用 list 时候查看分组是没有区别的

如果使用聚合函数就不一样了

2.5 对组排序:sort
sort :布尔值,默认为 True。是对组排序的关键。如果想要更好的性能,可以关掉它。请注意,这个并不影响每个组的内在顺序, Groupby 保留每个组中的行顺序。
2.6 组键值:group_keys
group_keys :布尔值, default True When calling apply, add group keys to index to identify pieces。这个后续在讲 groupby.apply 时候再讲。
”’
要是大家觉得写得还行,麻烦点个赞或者收藏吧,想给博客涨涨人气,非常感谢!
”’
Original: https://blog.csdn.net/u010701274/article/details/121868272
Author: 江南野栀子
Title: Pandas 模块-操纵数据(10)-数据分组 .groupby()
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/756652/
转载文章受原作者版权保护。转载请注明原作者出处!