

scrapy介绍
Scrapy 是一套基于Twisted、纯python实现的异步爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,相当的方便~
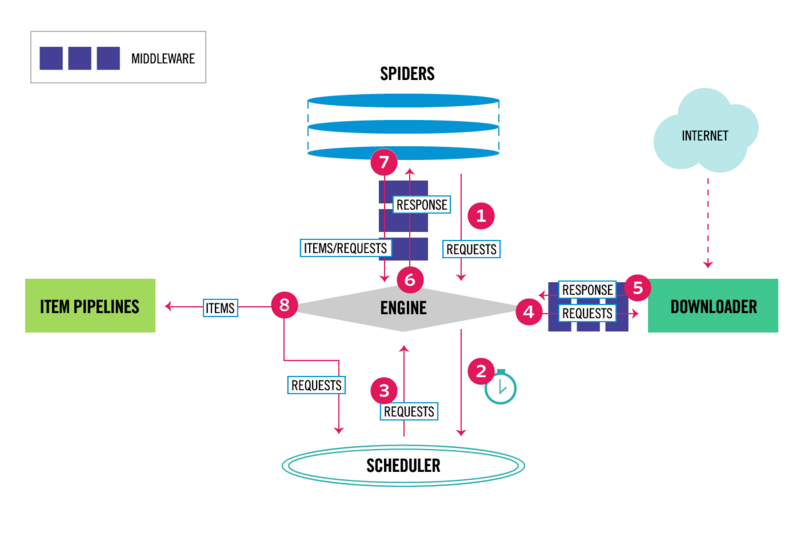

整体架构和组成
Scrapy Engine(引擎)
引擎负责控制数据流在系统所有组件中的流动,并在相应动作发生时触发事件,是框架的核心。
Scheduler(调度器)
调度器从引擎接受request并将他们入队,在引擎再次请求时将请求提供给引擎。
Downloader(下载器)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spider(爬虫)
Spider是Scrapy用户编写用于分析response并提取item(即获取到item)或额外跟进的URL的类,定义了爬取的逻辑和网页内容的解析规则。 每个spider负责处理一个特定(或一些)网站。
Item Pipeline(管道)
Item Pipeline负责处理被spider提取出来的item。典型的处理有清洗,验证及持久化(例如存取到数据库中)
Downloader Middlewares(下载中间件)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response(也包括引擎传递给下载器的Request)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
Spider Middlewares(Spider中间件)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
安装
pip install scrapy
爬虫项目
准备工作
创建项目
scrapy startproject xingmingdq
新建爬虫
scrapy genspider xingming resgain.net/xmdq.html
这个时候,目录下会创建xingmingdq文件夹,文件夹下就是xingmingdq scrapy项目,spiders下有xingming爬虫文件。
建立item
items.py中添加以下代码:
class Xingming_Item(scrapy.Item):
name = scrapy.Field()
xingshi = scrapy.Field()
xingshi_zh = scrapy.Field()
爬取名字
爬虫文件spiders/xingming.py书写网页解析规则。
–– coding: utf-8 ––
import scrapy
from xingmingdq.items import Xingming_Item
class XingmingSpider(scrapy.Spider):
name = ‘xingming’
allowed_domains = [‘www.resgain.net/xmdq.html’]
start_urls = [‘http://www.resgain.net/xmdq.html’]
def parse(self, response):
content = response.xpath(‘//div[@class=”col-xs-12″]/a/@href’).extract()
for i in content:
page = 0
href = ‘http:’ + i
base = href.split(‘/name’)[0] + ‘/name_list_’
while page < 10:
url = base + str(page) + ‘.html’
page += 1
yield scrapy.Request(url, callback=self.parse_in_html)
解析每一页
def parse_in_html(self, response):
person_info = response.xpath(‘//div[@class=”col-xs-12″]/div[@class=”btn btn-default btn-lg namelist”]/div[@style=”margin-top: 20px;”]’)
xingshi_zh = response.xpath(‘//div[@class=”navbar-header”]/a/div[@style=”text-align: center;”]/text()’).extract()[0].split(‘姓之家’)[0]
xingshi = response.url.split(‘/’)[2].split(‘.’)[0]
for every_one in person_info:
name = every_one.xpath(‘./text()’).extract()[0]
the_item = Xingming_Item()
the_item[‘name’] = name
the_item[‘xingshi’] = xingshi
the_item[‘xingshi_zh’] = xingshi_zh
yield the_item
处理流程
pipelines.py中,编写结果写入文件的处理。
class XingmingdqPipeline(object):
def init(self):
self.fp = open(‘xingming.csv’, ‘w’, encoding=’utf-8′)
def process_item(self, item, spider):
self.fp.write(‘%s,%s,%s\n’ % (item[‘name’], item[‘xingshi_zh’], item[‘xingshi’]))
return item
def close_spider(self, spider):
self.fp.close()
设置参数
要想执行pipelines,需要在settings.py中进行配置,搜索USER_AGENT和ITEM_PIPELINES进行修改。
修改USER_AGENT
USER_AGENT = ‘Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)’
配置ITEM_PIPELINES
ITEM_PIPELINES = {
‘xingmingdq.pipelines.XingmingdqPipeline’: 300,
}
执行爬虫
命令执行
scrapy crawl xingming
脚本执行
写入python文件,创建run.py,编辑下面代码,pycharm中运行。
import os
os.system(“scrapy crawl xingming”)
结果文件
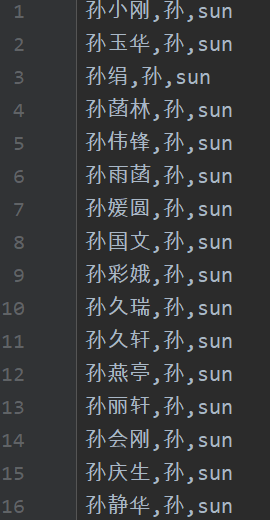
词云分析
导入爬取的姓名数据,分析出图:

哈哈哈,最多的竟然是婷婷

找找有你的名字没有吧。
Original: https://blog.csdn.net/weixin_32689769/article/details/113566164
Author: 123456zggb
Title: scrapy mysql 词云_利用Scrapy爬取姓名大全作词云分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/792256/
转载文章受原作者版权保护。转载请注明原作者出处!