

文章目录
- Scrapy入门
* - 1.目标
- 2.准备工作
- 3.创建项目
- 4.创建 Spider
- 5.创建 Item
- 6.解析 Response
- 7.使用Item
- 8.后续Request
- 9.运行
- 10.保存到文件
- 11.使用Item Pipeline
Scrapy入门
上一节我们介绍了Scrapy 框架的基本架构、数据流过程和项目架构,对Scrapy有了初步的认识。接下来我们用 Scrapy 实现一个简单的项目,完成一遍 Scrapy 抓取流程。通过这个过程,我们可以对Scrapy的基本用法和原理有大体了解。
1.目标
本节要完成的目标如下。
- 创建一个 Scrapy 项目,熟悉 Scrapy项目的创建流程。
- 编写一个 Spider 来抓取站点和处理数据,了解 Spider的基本用法。
- 初步了解Item Pipeline 的功能,将抓取的内容保存到MongoDB数据库。
- 运行Scrapy 爬虫项目,了解 Scrapy 项目的运行流程。
这里我们以 Scrapy 推荐的官方练习项目为例进行实战演练,抓取的目标站点为 https://quotes.toscrape.com/,页面如图所示。


这个站点包含了一系列名人名言、作者和标签,我们需要使用Scrapy将其中的内容爬取并保存下来。
; 2.准备工作
在开始之前,我们需要安装好Scrapy框架、MongoDB和PyMongo库,具体的安装参考流程如下:
- Scrapy:使用pip命令进行安装
- MongoDB:https://cuiqingcai.com/31070.html
- PyMongo:使用pip命令进行安装
安装好这三部分之后,我们就可以正常使用 Scrapy 命令了,同时也可以使用PyMongo连接MongoDB数据库并写入数据了。
3.创建项目
首先我们需要创建一个Scrapy项目,可以直接用命令生成,项目名称可以叫作 scrapytutorial,创建命令如下:
scrapy startproject scrapytutorial

运行完毕后,当前文件夹下会生成一个名为scrapytutorial的文件夹:
使用Pycharm打开文件,文件夹结构如下所示:

4.创建 Spider
Spider是自己定义的类,Scrapy 用它来从网页里抓取内容,并解析抓取的结果。不过这个类必须继承 Scrapy 提供的 Spider 类 scrapy.Spider,还要定义 Spider 的名称和起始 Request,以及怎样处理爬取后的结果的方法。
也可以使用命令行创建一个 Spider。比如要生成 Quotes 这个 Spider,可以执行如下命令:
cd scrapytutorial
scrapy genspider quotes quotes.toscrape.com
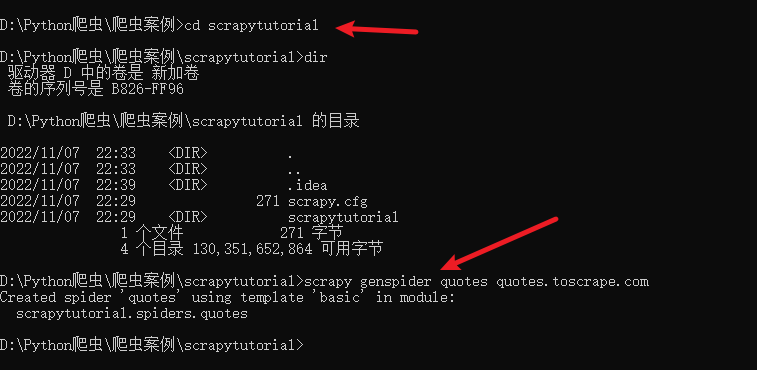
进人刚才创建的scrapytutorial 文件夹,然后执行genspider 命令。第一个参数是 Spider的名称,第二个参数是网站域名。执行完毕后,spiders 文件夹中多了一个 quotes.py,它就是刚刚创建的Spider,我们再把start_urls中的http协议改成https,最终代码如下所示:
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['https://quotes.toscrape.com/']
def parse(self, response):
pass
这个QuotesSpider 就是刚才命令行自动创建的 Spider,它继承了 scrapy 的Spider类,QuotesSpitder有3个属性,分别为name、allowed_domains 和 start_urls,还有一个方法parse。
name是每个项目唯一的名字,用来区分不同的Spider。allowed_domains是允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉。start_urls包含了 Spider 在启动时爬取的URL列表,初始请求是由它来定义的。parse是 Spider的一个方法。在默认情况下,start_urls里面的链接构成的请求完成下载后,parse 方法就会被调用,返回的响应就会作为唯一的参数传递给 parse方法。该方法负责解析返回的响应、提取数据或者进一步生成要处理的请求。
5.创建 Item
Item是保存爬取数据的容器,定义了爬取结果的数据结构。它的使用方法和字典类似。不过相比字典,Item多了额外的保护机制,可以避免拼写错误或者定义字段错误。
创建Item 需要继承scrapy的Item类,并且定义类型为Field的字段,这个字段就是我们要爬取的字段。
那我们需要爬哪些字段呢?观察目标网站,我们可以获取到的内容有下面几项。
- text:文本,即每条名言的内容,是一个字符串。
- author:作者,即每条名言的作者,是一个字符串。
- tags:标签,即每条名言的标签,是字符串组成的列表。
这样的话,每条爬取数据就包含这3个字段,那么我们就可以定义对应的tem,此时将items.py修改如下:
import scrapy
class QuoteItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
这里我们声明了QuoteItem,继承了Item类,然后使用 Field定义了3个字段,接下来爬取时我们会使用到这个Item。
6.解析 Response
前面我们看到,parse 方法的参数 response 是 start_urls 里面的链接爬取后的结果,即页面请求后得到的 Response,Scrapy 将其转化为了一个数据对象,里面包含了页面请求后得到的Response Status、Body 等内容。所以在parse方法中,我们可以直接对response 变量包含的内容进行解析,比如浏览请求结果的网页源代码,进一步分析源代码内容,或者找出结果中的链接而得到下一个请求。
我们可以看到网页中既有我们想要的结果,又有下一页的链接,这两部分内容我们都要进行处理。
首先看看网页结构,如图所示。每一页都有多个class为 quote的区块,每个区块内都包含text、author、tags。那么我们先找出所有的quote,然后提取每个quote 中的内容。

我们可以使用CSS选择器或XPath选择器进行提取,这个过程我们可以直接借助response的css或 xpath 方法实现,这都是 Scrapy给我们封装好的方法,直接调用即可。
在这里我们使用CSS选择器进行选择,可以将parse方法的内容进行如下改写:
def parse(self, response):
quotes=response.css('.quote')
for quote in quotes:
text=quote.css('.text::text').extract_first()
author=quote.css('.author::text').extract_first()
tags=quote.css('.tags .tags::text').extract()
这里首先利用CSS 选择器选取所有的quote 并将其赋值为quotes变量,然后利用for 循环遍历每个quote,解析每个quote的内容。
对text来说,观察到它的class为text,所以可以用.text选择器来选取,这个结果实际上是整个带有标签的节点,要获取它的正文内容,可以加 ::text。这时的结果是长度为1的列表,所以还需要用extract_first方法来获取第一个元素。而对于tags来说,由于我们要获取所有的标签,所以用extract 方法获取整个列表即可。
7.使用Item
上文我们已经定义了QuoteItem,接下来就要使用它了。
我们可以把 ltem理解为一个字典,和字典还不太相同,其本质是一个类,所以在使用的时候需要实例化。实例化之后,我们依次用刚才解析的结果赋值 Item的每一个字段,最后将Item 返回。
QuotesSpider的改写如下:
import scrapy
from scrapytutorial.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['https://quotes.toscrape.com/']
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tags::text').extract()
yield item
如此一来,首页的所有内容就被解析出来并被赋值成了一个个QuoteItem了,每个Quoteltem就代表一条名言,包含名言的内容、作者和标签。
8.后续Request
上面的操作实现了从首页抓取内容,如果运行它,我们其实已经可以从首页提取到所有quote信息并将其转化为一个个QuoteItem 对象了。
但是,这样还不够,下一页的内容该如何抓取呢?这就需要我们从当前页面中找到信息来生成下一个Request,利用同样的方式进行请求并解析就好了。那再下一页呢?也是一样的原理,我们可以在下一个页面里找到信息再构造再下一个Request。这样循环往复迭代,从而实现整站的爬取。
我们将刚才的页面拉到最底部,如图所示。

这里我们发现有一个Next按钮,查看一下源代码,可以看到它的链接是/page/2/,实际上全链接就是 https://quotes.toscrape.com/page/2,通过这个链接我们就可以构造下一个Request了。
构造Request时需要用到scrapy的Request 类。这里我们传递两个参数,分别是url和 callback,这两个参数的说明如下。
url:目标页面的链接。callback:回调方法,当指定了该回调方法的Request完成下载之后,获取Response,Engine会将该Response 作为参数传递给这个回调方法。回调方法进行Response的解析生成一个或多个Item 或 Request,比如上文的parse方法就是回调方法。
由于刚才所定义的parse 方法就是用来提取名言text、author、tags的方法,而下一页的结构和刚才已经解析的页面结构是一样的,所以我们可以再次使用parse方法来做页面解析。
接下来我们要做的就是利用选择器得到下一页链接并生成请求,在parse方法后追加如下的代码:
next = response.css('.pager .next a::attr(href)').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url=url, callback=self.parse())
第一行代码首先通过CSS选择器获取下一个页面的链接,即要获取超链接a中的href 属性,这里用到了::attr(href)进行提取,其中 attr 代表提取节点的属性,href 则为要提取的属性名,然后再下一步调用extract_first方法获取内容。
第二行代码调用了urljoin方法,urljoin方法可以将相对URL构造成一个绝对URL。例如,获取到的下一页地址是/page/2/,urljoin方法处理后得到的结果就是 https://quotes.toscrape.com/page/2/。
第三行代码通过url和callback变量构造了一个新的Request,回调方法callback依然使用parse方法。这个 Request 执行完成后,其对应的Response 会重新经过parse方法处理,得到第二页的解析结果,然后以此类推,生成第二页的下一页,也就是第三页的请求。这样爬虫就进入了一个循环,直到最后一页。
通过几行代码,我们就轻松实现了一个抓取循环,将每个页面的结果抓取下来了。
现在,改写后的整个Spider类如下所示:
import scrapy
from scrapytutorial.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['https://quotes.toscrape.com/']
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tags::text').extract()
yield item
next = response.css('.pager .next a::attr(href)').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url=url, callback=self.parse())
可以看到整个站点的抓取逻辑就轻松完成了,不需要再去编写怎样发送Request,不需要去关心异常处理,因为这些工作Scrapy都帮我们完成了,我们只需要关注Spider本身的抓取和提取逻辑即可。
9.运行
接下来就是运行项目了,点击终端,输入命令:
scrapy crawl quotes

就可以看到Scrapy的运行结果了:


这里只是部分运行结果,省略了一些中间的抓取结果。
首先,Scrapy 输出了当前的版本号以及正在启动的项目名称。然后输出了当前 settings.py 中一些重写后的配置。接着输出了当前所应用的Middlewares和Item Pipelines。 Middlewares和 Item Pipelines都沿用了Scrapy的默认配置,我们可以在 settings.py中配置它们的开启和关闭,后文会对它们的用法进行讲解。
接下来就是输出各个页面的抓取结果了,可以看到爬虫一边解析,一边翻页,直到将所有内容抓取完毕,然后终止。
最后,Scrapy输出了整个抓取过程的统计信息,如请求的字节数、请求次数、响应次数、完成原因等。
整个Scapy程序成功运行。我们通过非常简单的代码就完成了一个站点内容的爬取,所有的名言都被我们抓取下来了。
10.保存到文件
运行完Scrapy后,我们只在控制台上看到了输出结果。如果想保存结果该怎么办呢?
要完成这个任务其实不需要任何额外的代码,Scrapy 提供的Feed Exports 可以轻松将抓取结果出。例如,如果我们想将上面的结果保存成JSON文件,那么可以执行如下命令:
scrapy crawl quotes -o quotes.json
命令运行后,项目内多了一个quotesjson 文件,文件包含了刚才抓取的所有内容,内容是JSON格式。
另外我们还可以让每一个Item 输出一行JSON,输出后缀为j1,为jsonline的缩写,命令如下所示:
scrapy crawl quotes -o quotes.jl
或
scrapy crawl quotes -o quotes.jsonlines
Feed Exports支持从输出格式还有很多,例如csv、xml、pickle、marshal等,同时它支持ftp、s3等远程输出,另外还可以通过自定义ItemExporter 来实现其他的输出。
例如,下面命令对应的输出分别为csv、xml、pickle、marshal格式以及ftp远程输出:
scrapy crawl quotes -o quotes.csv
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.pickle
scrapy crawl quotes -o quotes.marshal
scrapy crawl quotes -o ftp://user:pass@ftp.example.com/path/to/quotes.csv
其中,ftp 输出需要正确配置用户名、密码、地址、输出路径,否则会报错。
通过Scrapy 提供的Feed Exports,我们可以轻松地将抓取结果到输出到文件中。对于一些小型项目来说,这应该足够了。
如果想要更复杂的输出,如输出到数据库等,我们可以使用Item Pileline来完成。
11.使用Item Pipeline
如果想进行更复杂的操作,如将结果保存到 MongoDB数据库中或者筛选某些有用的Item,那么我们可以定义Item Pipeline 来实现。
ltem Pipeline 为项目管道。当 Item生成后,它会自动被送到 Item Pipeline 处进行处理,我们可以用Item Pipeline来做如下操作:
- 清洗HTML数据;
- 验证爬取数据,检查爬取字段;
- 查重并丢弃重复内容;
- 将爬取结果储存到数据库。
要实现 Item Pipeline 很简单,只需要定义一个类并实现process_item方法即可。启用Item Pipeline后,Item Pipeline 会自动调用这个方法。process_item方法必须返回包含数据的字典或Item对象,或者抛出 DropItem异常。
process_item 方法有两个参数。一个参数是item,每次 Spider 生成的Item都会作为参数传递过来。另一个参数是spider,就是 Spider 的实例。
接下来,我们实现一个 Item Pipeline,筛掉 text 长度大于 50的Item,并将结果保存到 MongoDB。修改项目里的 pipelines.py 文件,之前用命令行自动生成的文件内容可以删掉,增加一个TextPipeline 类,内容如下所示:
from scrapy.exceptions import DropItem
class Textpipeline(object):
def _init_(self):
self.limit = 50
def process_item(self, item, spider):
if item['text']:
if len(item['text']) > self.limit:
item['text'] = item['text'][0:self.limit].rstrip() + '...'
return item
else:
return DropItem('Missing Text')
这段代码在构造方法里定义了限制长度为50,实现了process_item方法,其参数是 item 和 spider。首先该方法判断item的text属性是否存在,如果不存在,则抛出DropItem异常。如果存在,再判断长度是否大于50,如果大于,那就截断然后拼接省略号,再将item返回。
接下来,我们将处理后的item 存入 MongoDB,定义另外一个 Pipeline。同样在 pipelines.py 中,我们实现另一个类MongoPipeline,内容如下所示:
import pymongo
class MongoDBPipeline(object):
def _init_(self, connection_string, database):
self.connection_string = connection_string
self.database = database
@classmethod
def from_crawler(cls, crawler):
return cls(
connection_string=crawler.settings.get('MONGODB_CONNECTION_STRING'),
database=crawler.settings.get('MONCODB_DATABASE')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.connection_string)
self.db = self.client[self.database]
def process_item(self, item, spider):
name = item._class_._name_
self.db[name].insert_one(dict(item))
return item
def close_spider(self, spider):
self.client.close()
MongoPipeline类实现了另外几个API定义的方法。
- from_crawler:一个类方法,用@classmethod标识,这个方法是以依赖注入的方式实现的,方法的参数就是crawler。通过crawler,我们能拿到全局配置的每个配置信息,在全局配置settings-py 中,可以通过定义 MONGO_URI和 MONGO_DB来指定 MongoDB连接需要的地址和数据库名称,拿到配置信息之后返回类对象即可。所以这个方法的定义主要是用来获取 settings.py中的配置的。
- open_spider:当 Spider 被开启时,这个方法被调用,主要进行了一些初始化操作。
- close_spider:当 Spider 被关闭时,这个方法被调用,将数据库连接关闭。
最主要的process_item方法则执行了数据插入操作,这里直接调用 insert_one 方法传入item对象即可将数据存储到 MongoDB。
定义好 TextPipeline 和 MongoDBPipeline 这两个类后,我们需要在 settings.py 中使用它们。MongoDB的连接信息还需要定义。
我们在 setings.py 中加入如下内容:
ITEM_PIPELINES = {
'scrapytutorial.pipelines.TextPipeline': 300,
'scrapytutorial.pipelines.MongoDBPipeline': 400,
}
MONGODB_CONNECTION_STRING = 'localhost'
MONGODB_DATABASE = 'scrapytutorial'
这里我们声明了 ITEM_PIPELINES 字典,键名是 Pipeline 的类名称,健值是调用优先级,是一个数字,数字越小则对应的Pipeline 越先被调用,另外我们声明了MongoDB的连接字符串和存储的数据库名称。
再重新执行爬取,命令还是一样的:
scrapy crawl quotes
爬取结束后,我们可以看到MongoDB中创建了一个 scrapytutorial的数据库和QuoteItem的表,内容如图所示。

Original: https://blog.csdn.net/W_chuanqi/article/details/127854585
Author: W_chuanqi
Title: Scrapy入门
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/790619/
转载文章受原作者版权保护。转载请注明原作者出处!