

逻辑回归算法,虽然名字中带有”回归”二字,但解决的却是分类问题,它与线性回归之间有什么样的关系呢?
文章目录
1.二项逻辑斯蒂回归
概述
二项逻辑斯蒂回归,简称逻辑回归,又称为对数几率回归,是一种二分类模型。
模型:h = 1 1 + e − ( W T x + b ) h=\frac{1}{1+e^{-(W ^{T}x + b)} }h =1 +e −(W T x +b )1 代价函数:J = − 1 m ∑ i = 1 m y i ln h ( x i ) + ( 1 − y i ) ln [ 1 − h ( x i ) ] J = -\frac{1}{m} \sum_{i=1}^{m}y_{i}\ln_{}{h(x_{i})}+(1-y_{i})\ln_{}{\left [1 – h(x_{i}) \right ]}J =−m 1 i =1 ∑m y i ln h (x i )+(1 −y i )ln [1 −h (x i )] 目标:W ∗ , b ∗ = a r g m i n W , b J ( W , b ) W^{}, b^{} = \underset{W, b}{argmin} J(W, b)W ∗,b ∗=W ,b a r g min J (W ,b )
模型形式——对数几率函数
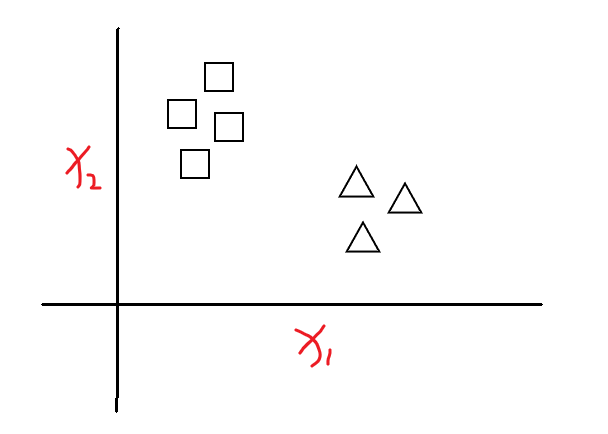

假设一组数据的分布如上图所示,建立一个什么样的模型将两个类别区分开来呢?线性回归模型z = W T x + b z = W ^{T}x + b z =W T x +b貌似可以解决这个问题,但是线性回归模型的输出值是一个实值,而二分类任务的输出标记y ∈ { 0 , 1 } y\in \left { 0,1 \right }y ∈{0 ,1 }(在二项逻辑斯蒂回归中,我们强制将正类标记为1,负类标记为0,后面将会提到这样做的原因),于是,我们考虑将 实值z z z 转换为0/1值,最理想的是 单位阶跃函数y = { 0 if z < 0 0.5 if z = 0 1 if z > 0 y=\begin{cases} 0 & \text{ if } z y =⎩⎪⎨⎪⎧0 0 .5 1 if z <0 if z =0 if z >0 .但单位阶跃函数是不连续的,我们希望找到在一定程度上接近单位阶跃函数的替代函数,并希望它单调可微, 对数几率函数正是这样一个常用的替代函数,对数几率函数(又叫sigmod函数,logistic函数):y = 1 1 + e − z y=\frac{1}{1+e^{-z} }y =1 +e −z 1
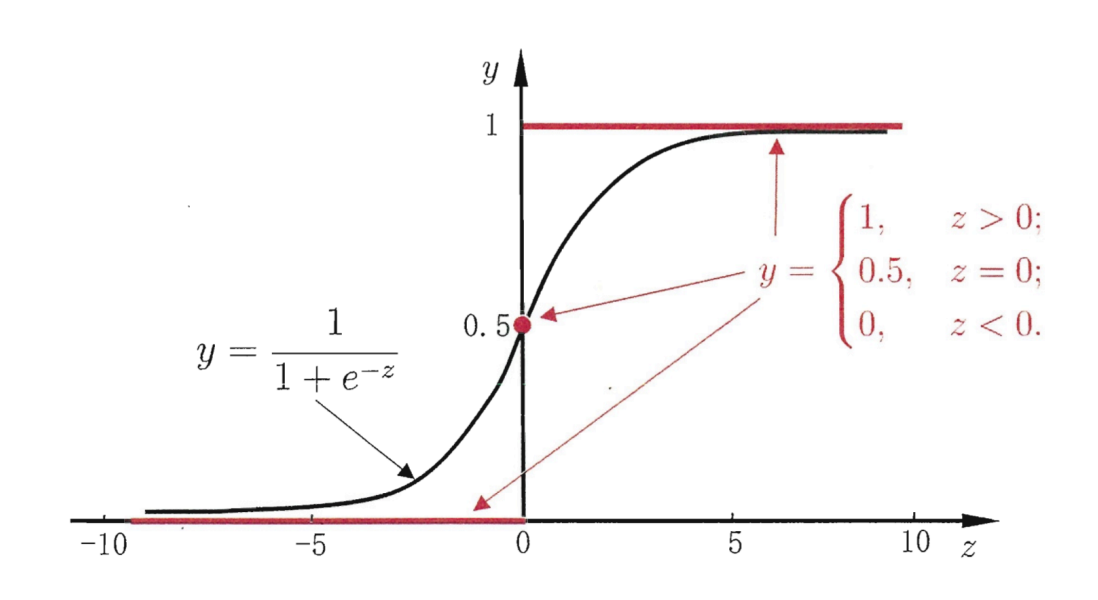
这样就把实数域的值转化到了( 0 , 1 ) (0, 1)(0 ,1 )。
综上,得到逻辑回归模型形式:h = 1 1 + e − ( W T x + b ) h=\frac{1}{1+e^{-(W ^{T}x + b)} }h =1 +e −(W T x +b )1 值域在(0, 1)之间,并且正类标记为1,负类标记为0,所以y可以看作x x x是正类的概率。
分类决策:当y > 0.5 y>0.5 y >0 .5时,判断为正类,y < 0.5 y时,判断为负类,y = 0.5 y=0.5 y =0 .5时,可以任意判别。
; 模型参数估计——最大似然估计
负平均对数似然函数
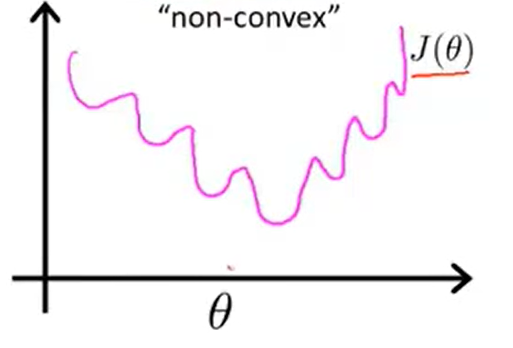
如何来估计模型的参数呢?我们需要定义模型的代价函数,线性回归模型使用的平方误差代价函数应用于逻辑回归模型中将是非凸函数,不能保证找到全局最小值,在逻辑回归模型中,我们使用负平均对数似然函数。
似然函数:一种关于模型中的参数的函数,L ( θ ∣ x ) = P ( X = x ∣ θ ) L(\theta |x) = P(X=x|\theta )L (θ∣x )=P (X =x ∣θ).
负平均对数似然函数就是在似然函数的基础上取对数再求平均再加上负号。
下面我们来推导一下样本集中m m m个独立样本出现的似然函数:
训练样本集{ ( x i , y i ) , i = 1 , 2 , … , m } \left { (x_{i}, y_{i}), i = 1, 2, \dots , m \right }{(x i ,y i ),i =1 ,2 ,…,m },假设 样本彼此独立,类别标记y ∈ { 0 , 1 } y\in \left { 0,1 \right }y ∈{0 ,1 },则样本( x i , y i ) (x_{i}, y_{i})(x i ,y i )出现的概率:P ( x i , y i ) = [ P ( y i = 1 ∣ x i ) ] y i [ 1 − P ( y i = 1 ∣ x i ) ] 1 − y i P ( x i ) , P(x_{i}, y_{i}) = \left [ P(y_{i}=1|x_{i}) \right ]^{y_{i}}\left [1 – P(y_{i}=1|x_{i}) \right ]^{1-y_{i}} P(x_{i}),P (x i ,y i )=[P (y i =1 ∣x i )]y i [1 −P (y i =1 ∣x i )]1 −y i P (x i ),m m m个独立样本出现的 似然函数为:l = ∏ i = 1 m P ( x i , y i ) = ∏ i = 1 m [ P ( y i = 1 ∣ x i ) ] y i [ 1 − P ( y i = 1 ∣ x i ) ] 1 − y i P ( x i ) = ∏ i = 1 m [ P ( y i = 1 ∣ x i ) ] y i [ 1 − P ( y i = 1 ∣ x i ) ] 1 − y i ∏ i = 1 m P ( x i ) \begin{aligned} l &= \prod_{i=1}^{m} P(x_{i}, y_{i})\ &= \prod_{i=1}^{m}\left [ P(y_{i}=1|x_{i}) \right ]^{y_{i}}\left [1 – P(y_{i}=1|x_{i}) \right ]^{1-y_{i}} P(x_{i})\ &=\prod_{i=1}^{m}\left [ P(y_{i}=1|x_{i}) \right ]^{y_{i}}\left [1 – P(y_{i}=1|x_{i}) \right ]^{1-y_{i}}\prod_{i=1}^{m}P(x_{i}) \end{aligned}l =i =1 ∏m P (x i ,y i )=i =1 ∏m [P (y i =1 ∣x i )]y i [1 −P (y i =1 ∣x i )]1 −y i P (x i )=i =1 ∏m [P (y i =1 ∣x i )]y i [1 −P (y i =1 ∣x i )]1 −y i i =1 ∏m P (x i )其中∏ i = 1 m P ( x i ) \prod_{i=1}^{m}P(x_{i})∏i =1 m P (x i )与模型参数无关,所以似然函数可简化为l = ∏ i = 1 m [ P ( y i = 1 ∣ x i ) ] y i [ 1 − P ( y i = 1 ∣ x i ) ] 1 − y i l=\prod_{i=1}^{m}\left [ P(y_{i}=1|x_{i}) \right ]^{y_{i}}\left [1 – P(y_{i}=1|x_{i}) \right ]^{1-y_{i}}l =i =1 ∏m [P (y i =1 ∣x i )]y i [1 −P (y i =1 ∣x i )]1 −y i 公式中存在很多连乘,为了计算简便,我们考虑对似然函数取对数:l ′ = ln l = ln { ∏ i = 1 m [ P ( y i = 1 ∣ x i ) ] y i [ 1 − P ( y i = 1 ∣ x i ) ] 1 − y i } = ∑ i = 1 m ln { [ P ( y i = 1 ∣ x i ) ] y i [ 1 − P ( y i = 1 ∣ x i ) ] 1 − y i } = ∑ i = 1 m y i ln [ P ( y i = 1 ∣ x i ) ] + ( 1 − y i ) ln [ 1 − P ( y i = 1 ∣ x i ) ] \begin{aligned} {l}’=\ln_{}{l} &=\ln_{}{\left { \prod_{i=1}^{m}\left [ P(y_{i}=1|x_{i}) \right ]^{y_{i}}\left [1 – P(y_{i}=1|x_{i}) \right ]^{1-y_{i}} \right } } \ &= \sum_{i=1}^{m}\ln_{}{\left { \left [ P(y_{i}=1|x_{i}) \right ]^{y_{i}}\left [1 – P(y_{i}=1|x_{i}) \right ]^{1-y_{i}} \right } }\ &=\sum_{i=1}^{m}y_{i}\ln_{}{\left [ P(y_{i}=1|x_{i}) \right ]}+(1-y_{i})\ln_{}{\left [1 – P(y_{i}=1|x_{i}) \right ]} \end{aligned}l ′=ln l =ln {i =1 ∏m [P (y i =1 ∣x i )]y i [1 −P (y i =1 ∣x i )]1 −y i }=i =1 ∑m ln {[P (y i =1 ∣x i )]y i [1 −P (y i =1 ∣x i )]1 −y i }=i =1 ∑m y i ln [P (y i =1 ∣x i )]+(1 −y i )ln [1 −P (y i =1 ∣x i )]平均对数似然函数为:l ^ = 1 m ∑ i = 1 m y i ln [ P ( y i = 1 ∣ x i ) ] + ( 1 − y i ) ln [ 1 − P ( y i = 1 ∣ x i ) ] \hat{l} =\frac{1}{m} \sum_{i=1}^{m}y_{i}\ln_{}{\left [ P(y_{i}=1|x_{i}) \right ]}+(1-y_{i})\ln_{}{\left [1 – P(y_{i}=1|x_{i}) \right ]}l ^=m 1 i =1 ∑m y i ln [P (y i =1 ∣x i )]+(1 −y i )ln [1 −P (y i =1 ∣x i )]
目标:最大化平均对数似然求解参数:a r g max l ^ w , b \underset{w,b}{arg\max \hat{l} }w ,b a r g max l ^
等价于:最小化负的平均对数似然:a r g max w , b ( − l ^ ) \underset{w,b}{arg\max}(\hat{-l} )w ,b a r g max (−l ^),这样,就可以使用梯度下降法求解参数了。
; 使用梯度下降法求解参数
使用梯度下降法求解参数的关键是求得代价函数对参数的偏导,下面来推导一下:(前面的一篇文章单独讲了梯度下降法,不了解的可以看一下:梯度下降法求解最优化问题)
J = − 1 m ∑ i = 1 m y i ln h ( x i ) + ( 1 − y i ) ln [ 1 − h ( x i ) ] h = 1 1 + e − z z = w T x + b ∂ h ∂ z = 0 − e − z ∗ ( − 1 ) ( 1 + e − z ) 2 = e − z ( 1 + e − z ) 2 = h ( 1 − h ) ∂ J ∂ w j = ∂ J ∂ h ⋅ ∂ h ∂ z ⋅ ∂ z ∂ w j = − 1 m ∑ i = 1 m ( y i h ( x i ) + 1 − y i 1 − h ( x i ) ) ⋅ h ( x i ) ( 1 − h ( x i ) ) ⋅ x i ( j ) = − 1 m ∑ i = 1 m ( y i − h ( x i ) ) x i ( j ) = 1 m ∑ i = 1 m ( h ( x i ) − y i ) x i ( j ) , ( j = 1 , 2 , … n ) ∂ J ∂ b = ∂ J ∂ h ⋅ ∂ h ∂ z ⋅ ∂ z ∂ b = − 1 m ∑ i = 1 m ( y i h ( x i ) + 1 − y i 1 − h ( x i ) ) ⋅ h ( x i ) ( 1 − h ( x i ) ) ⋅ 1 = − 1 m ∑ i = 1 m ( y i − h ( x i ) ) = 1 m ∑ i = 1 m ( h ( x i ) − y i ) \begin{aligned} J &= -\frac{1}{m} \sum_{i=1}^{m}y_{i}\ln_{}{h(x_{i})}+(1-y_{i})\ln_{}{\left [1 – h(x_{i}) \right ]}\ h&=\frac{1}{1+e^{-z} }\ z &= w ^{T}x + b\ \frac{\partial h}{\partial z} &= \frac{0-e^{-z}(-1)}{(1+e^{-z})^2} = \frac{e^{-z}}{(1+e^{-z})^2}=h(1-h)\ \frac{\partial J}{\partial w_{j}} &= \frac{\partial J}{\partial h}\cdot \frac{\partial h}{\partial z}\cdot \frac{\partial z}{\partial w_{j}}\ &= -\frac{1}{m}\sum_{i=1}^{m}(\frac{y_{i}}{h(x_{i})} +\frac{1-y_{i}}{1-h(x_{i})})\cdot h(x_{i})(1-h(x_{i}))\cdot x_{i}^{(j)}\ &= -\frac{1}{m}\sum_{i=1}^{m}(y_{i}-h(x_{i}))x_{i}^{(j)}\ &= \frac{1}{m}\sum_{i=1}^{m}(h(x_{i})-y_{i})x_{i}^{(j)}, (j = 1, 2, \dots n)\ \frac{\partial J}{\partial b} &= \frac{\partial J}{\partial h}\cdot \frac{\partial h}{\partial z}\cdot \frac{\partial z}{\partial b}\ &= -\frac{1}{m}\sum_{i=1}^{m}(\frac{y_{i}}{h(x_{i})} +\frac{1-y_{i}}{1-h(x_{i})})\cdot h(x_{i})(1-h(x_{i}))\cdot 1\ &= -\frac{1}{m}\sum_{i=1}^{m}(y_{i}-h(x_{i}))\ &= \frac{1}{m}\sum_{i=1}^{m}(h(x_{i})-y_{i}) \end{aligned}J h z ∂z ∂h ∂w j ∂J ∂b ∂J =−m 1 i =1 ∑m y i ln h (x i )+(1 −y i )ln [1 −h (x i )]=1 +e −z 1 =w T x +b =(1 +e −z )2 0 −e −z ∗(−1 )=(1 +e −z )2 e −z =h (1 −h )=∂h ∂J ⋅∂z ∂h ⋅∂w j ∂z =−m 1 i =1 ∑m (h (x i )y i +1 −h (x i )1 −y i )⋅h (x i )(1 −h (x i ))⋅x i (j )=−m 1 i =1 ∑m (y i −h (x i ))x i (j )=m 1 i =1 ∑m (h (x i )−y i )x i (j ),(j =1 ,2 ,…n )=∂h ∂J ⋅∂z ∂h ⋅∂b ∂z =−m 1 i =1 ∑m (h (x i )y i +1 −h (x i )1 −y i )⋅h (x i )(1 −h (x i ))⋅1 =−m 1 i =1 ∑m (y i −h (x i ))=m 1 i =1 ∑m (h (x i )−y i )将参数b b b与w w w向量合并为一个向量,b b b即w 0 w_{0}w 0 ,x i 0 x_{i}^{0}x i 0 始终为1,所以代价函数J J J对参数w j w_{j}w j 的偏导可以写为:∂ J ∂ w j = 1 m ∑ i = 1 m ( h ( x i ) − y i ) x i ( j ) , ( j = 0 , 1 , 2 , … n ) \frac{\partial J}{\partial w_{j}} = \frac{1}{m}\sum_{i=1}^{m}(h(x_{i})-y_{i})x_{i}^{(j)}, (j = 0, 1, 2, \dots n)∂w j ∂J =m 1 i =1 ∑m (h (x i )−y i )x i (j ),(j =0 ,1 ,2 ,…n ) 梯度下降法参数更新*:
repeat until convergence{
w j : = w j − α ∑ i = 1 m ( h ( x i ) − y i ) x i ( j ) w_{j} := w_{j} – \alpha \sum_{i=1}^{m}(h(x_{i})-y_{i})x_{i}^{(j)}w j :=w j −α∑i =1 m (h (x i )−y i )x i (j )
(simultaneously update all θ j \theta_{j}θj )
}
特征缩放
特征缩放加速收敛。给数据做如下变化:x i ′ = x i − μ s , {x}{i}{}’ = \frac{x{i} – \mu }{s},x i ′=s x i −μ,其中μ \mu μ为均值向量,s = { 各 个 特 征 的 m a x − m i n 构 成 的 向 量 标 准 差 向 量 s = \left{\begin{matrix} 各个特征的max-min构成的向量\ 标准差向量 \end{matrix}\right.s ={各个特征的m a x −m i n 构成的向量标准差向量.
注:x 0 x_{0}x 0 不需要进行缩放,x 0 = 1 x_{0}=1 x 0 =1.
代码实现
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
def load_data():
dataset = datasets.load_breast_cancer()
dataX = dataset.data
dataY = dataset.target
print("dataX的shape:", dataX.shape)
return dataX, dataY
def normalization(dataX):
'''z-score归一化
Parameters:
dataX: 输入特征向量
Returns:
dataX1: 归一化之后的dataX
mu: 均值向量
sigma: 标准差向量
'''
mu = dataX.mean(0)
sigma = dataX.std(0)
dataX1 = (dataX - mu) / sigma
return dataX1, mu, sigma
class logistic_regression():
def __init__(self, dataX, dataY, alpha=0.1):
self.datasize = dataX.shape[0]
ones = np.ones(self.datasize)
self.dataX = np.c_[ones, dataX]
self.dataY = dataY
self.alpha = alpha
self.theta = np.zeros(self.dataX.shape[1])
def fit(self):
iterations = 100
for i in range(iterations):
updated_theta = []
y_hat = []
z = np.dot(self.dataX, self.theta)
for zi in z:
if zi < 0:
y = np.exp(zi) / (np.exp(zi) + 1)
else:
y = 1 / (1 + np.exp(-zi))
y_hat.append(y)
y_hat = np.array(y_hat)
loss = -1 / self.datasize * np.sum(self.dataY * np.log(y_hat + 1e-5) + (1 - self.dataY) * np.log(1 - y_hat + 1e-5))
print('第', i, '次迭代的loss:', loss)
for j, theta_j in enumerate(self.theta):
xj = self.dataX[:, j]
updated_theta_j = theta_j - self.alpha * np.sum((y_hat - self.dataY) * xj)
updated_theta.append(updated_theta_j)
self.theta = updated_theta
print('训练完成!')
def predict(self, testX, testY):
ones = np.ones(testX.shape[0])
testX = np.c_[ones, testX]
z = np.dot(testX, self.theta)
y_hat = []
for zi in z:
if zi < 0:
y = np.exp(zi) / (np.exp(zi) + 1)
else:
y = 1 / (1 + np.exp(-zi))
label = 1 if y >= 0.5 else 0
y_hat.append(label)
y_hat = np.array(y_hat)
cnt = 0
n = len(testY)
for i in range(n):
if y_hat[i] == testY[i]:
cnt += 1
print('模型预测正确率:', cnt / n)
return y_hat
if __name__ == "__main__":
dataX, dataY = load_data()
trainX, testX, trainY, testY = train_test_split(dataX, dataY, test_size=0.3, random_state=0)
newTrainX, mu, sigma = normalization(trainX)
print('mu =', mu, "sigma =", sigma)
newTestX = (testX - mu) / sigma
model = logistic_regression(newTrainX, trainY)
model.fit()
y_hat = model.predict(newTestX, testY)
print("预测值:", y_hat)
print("真实值:", testY)
代码运行结果:

2.多项逻辑斯蒂回归
概述
多项逻辑斯蒂回归又称为softmax回归,是二项逻辑斯蒂回归的推广,用于多类别分类。
模型:y j = e z j ∑ i = 1 C e z i y_{j} = \frac{e^{z_{j}} }{\sum_{i=1}^{C}e^{z_{i}} }y j =∑i =1 C e z i e z j 即softmax函数形式(softmax函数的推导详见参考文献1),将z j = w j T x + b j z_{j} = w^{T}{j}x + b{j}z j =w j T x +b j 带入,得到:P ( y = j ∣ x ) = e w j T x + b j ∑ i = 1 C e w i T x + b i , j = 1 , 2 , … , C P(y=j|x) = \frac{e^{w^{T}{j}x + b{j}} }{\sum_{i=1}^{C}e^{w^{T}{i}x + b{i}} },j=1,2,\dots, C P (y =j ∣x )=∑i =1 C e w i T x +b i e w j T x +b j ,j =1 ,2 ,…,C同样使用最大似然函数可得 代价函数:J = − 1 m ∑ i = 1 m ∑ k = 1 C [ ln P ( y i ∣ x i ) I ( y i = k ) ] J = -\frac{1}{m}\sum_{i=1}^{m}\sum_{k=1}^{C}\left [ \ln_{}{P(y_{i}|x_{i})^{I(y_{i}=k)}} \right ]J =−m 1 i =1 ∑m k =1 ∑C [ln P (y i ∣x i )I (y i =k )] 目标:W ∗ , b ∗ = a r g m i n W , b J ( W , b ) , W^{}, b^{} = \underset{W, b}{argmin} J(W, b),W ∗,b ∗=W ,b a r g min J (W ,b ),得到C组参数。
梯度下降法求解
下面推导一下代价函数J J J对w j w_{j}w j 的偏导,这里的w j w_{j}w j 是一个向量,并且偏置值b b b也包含在其中。(推导过程我搞了两三天没求出来,最终还是多亏了向大佬求助)J = − 1 m ∑ i = 1 m ∑ j = 1 C [ ln P ( y i ∣ x i ) I ( y i = j ) ] P ( y = i ∣ x ) = P i = e z i ∑ l = 1 C e z l z i = w i T x ∂ P ∂ z k = { e z k ∗ ∑ l = 1 C e z l − e z k ∗ e z k ( ∑ l = 1 C e z l ) 2 = P k − P k 2 if i = k 0 − e z i ∗ e z k ( ∑ l = 1 C e z l ) 2 = − P i P k if i ≠ k ∂ J ∂ w k = ∂ J ∂ P ⋅ ∂ P ∂ z ⋅ ∂ z ∂ w k = − 1 m ∑ i = 1 m [ I ( y i = k ) 1 P k ⋅ ( P k − P k 2 ) + ∑ j = 1 , j ≠ k C I ( y i = j ) 1 P j ⋅ ( − P j P k ) ] ⋅ x i = − 1 m ∑ i = 1 m [ I ( y i = k ) − I ( y i = k ) P k − P k ∑ j = 1 , j ≠ k C I ( y i = j ) ] ⋅ x i = − 1 m ∑ i = 1 m [ I ( y i = k ) − I ( y i = k ) P k − P k ( 1 − I ( y i = k ) ) ] ⋅ x i = − 1 m ∑ i = 1 m [ I ( y i = k ) − P k ] ⋅ x i \begin{aligned} J &= -\frac{1}{m}\sum_{i=1}^{m}\sum_{j=1}^{C}\left [ \ln_{}{P(y_{i}|x_{i})^{I(y_{i}=j)}} \right ]\ P(y=i|x) &= P_{i}= \frac{e^{z_{i}} }{\sum_{l=1}^{C}e^{z_{l}} }\ z_{i} &= w_{i}^{T}x\ \frac{\partial P}{\partial z_{k}}&=\begin{cases} \frac{e^{z_{k}}\sum_{l=1}^{C}e^{z_{l}} – e^{z_{k}}e^{z_{k}}}{(\sum_{l=1}^{C}e^{z_{l}})^{2}}= P_{k} – P_{k}^{2} & \text{ if } i=k \ \frac{0 – e^{z_{i}}*e^{z_{k}}}{(\sum_{l=1}^{C}e^{z_{l}})^{2}} =-P_{i}P_{k} & \text{ if } i\neq k \end{cases}\ \frac{\partial J}{\partial w_{k}} &= \frac{\partial J}{\partial P}\cdot \frac{\partial P}{\partial z}\cdot \frac{\partial z}{\partial w_{k}}\ &= -\frac{1}{m}\sum_{i=1}^{m}\left [ I(y_{i}=k)\frac{1}{P_{k}}\cdot (P_{k} – P_{k}^{2})+\sum_{j=1,j\neq k}^{C}I(y_{i}=j)\frac{1}{P_{j}}\cdot (-P_{j}P_{k}) \right ]\cdot x_{i}\ &= -\frac{1}{m}\sum_{i=1}^{m}\left [ I(y_{i}=k)-I(y_{i}=k)P_{k}-P_{k}\sum_{j=1,j\neq k}^{C}I(y_{i}=j) \right ]\cdot x_{i} \ &= -\frac{1}{m}\sum_{i=1}^{m}\left [ I(y_{i}=k)-I(y_{i}=k)P_{k}-P_{k}(1-I(y_{i}=k)) \right ]\cdot x_{i}\ &= -\frac{1}{m}\sum_{i=1}^{m}\left [ I(y_{i}=k)-P_{k} \right ]\cdot x_{i} \end{aligned}J P (y =i ∣x )z i ∂z k ∂P ∂w k ∂J =−m 1 i =1 ∑m j =1 ∑C [ln P (y i ∣x i )I (y i =j )]=P i =∑l =1 C e z l e z i =w i T x =⎩⎨⎧(∑l =1 C e z l )2 e z k ∗∑l =1 C e z l −e z k ∗e z k =P k −P k 2 (∑l =1 C e z l )2 0 −e z i ∗e z k =−P i P k if i =k if i =k =∂P ∂J ⋅∂z ∂P ⋅∂w k ∂z =−m 1 i =1 ∑m ⎣⎡I (y i =k )P k 1 ⋅(P k −P k 2 )+j =1 ,j =k ∑C I (y i =j )P j 1 ⋅(−P j P k )⎦⎤⋅x i =−m 1 i =1 ∑m ⎣⎡I (y i =k )−I (y i =k )P k −P k j =1 ,j =k ∑C I (y i =j )⎦⎤⋅x i =−m 1 i =1 ∑m [I (y i =k )−I (y i =k )P k −P k (1 −I (y i =k ))]⋅x i =−m 1 i =1 ∑m [I (y i =k )−P k ]⋅x i
参数更新:
repeat until convergence{
w k : = w k + α ∑ i = 1 m I ( y i = k ) ( 1 − P ( y i = k ∣ x i ) ) ⋅ x i w_{k} := w_{k} + \alpha \sum_{i=1}^{m}I(y_{i}=k)(1 – P(y_{i}=k|x_{i}))\cdot x_{i}w k :=w k +α∑i =1 m I (y i =k )(1 −P (y i =k ∣x i ))⋅x i
(simultaneously update all w j w_{j}w j )
}
代码实现
以下是使用多项逻辑斯蒂回归算法实现鸢尾花类别分类的代码。
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
def load_data():
dataset = datasets.load_iris()
dataX = dataset.data
dataY = dataset.target
print('dataX的shape', dataX.shape)
return dataX, dataY
def normalization(dataX):
'''z-score归一化
Parameters:
dataX: 输入特征向量
Returns:
dataX1: 归一化之后的dataX
mu: 均值向量
sigma: 标准差向量
'''
mu = dataX.mean(0)
sigma = dataX.std(0)
dataX1 = (dataX - mu) / sigma
return dataX1, mu, sigma
def dense_to_onehot(dense, n_classes):
'''将类别标号转为onehot向量
Parameters:
dense: 稠密的类别向量
n_classes: 类别数目
Returns:
onehot: 类别向量独热编码后的矩阵
注:此函数写的较为简单,只适用于类别从0开始编号,且依次递增1的情况
'''
n_labels = dense.shape[0]
onehot = np.zeros((n_labels, n_classes))
for i in range(n_labels):
onehot[i, dense[i]] = 1
return onehot
class multinomial_logistic_regression():
def __init__(self, dataX, dataY, alpha=0.1):
self.datasize = dataX.shape[0]
self.n_classes = len(set(dataY))
ones = np.ones(self.datasize)
self.dataX = np.c_[ones, dataX]
self.dataY = dense_to_onehot(dataY, self.n_classes)
self.alpha = alpha
self.theta = np.zeros((self.dataX.shape[1], self.n_classes))
def softmax(self, z):
'''softmax函数
Parameters:
z: shape(m, c)
Returns:
y: shape(m, c)
'''
y = np.zeros(z.shape)
for i, z_i in enumerate(z):
l = np.array([(lambda num: np.exp(z_ij) if z_ij < 0 else (1 / np.exp(-z_ij)))(z_ij) for z_ij in z_i])
l = l / sum(l)
y[i] = l
return y
def fit(self):
iterations = 100
for iteration in range(iterations):
z = np.dot(self.dataX, self.theta)
y_hat = self.softmax(z)
loss = -1 / self.datasize * np.sum(np.log(np.sum(np.multiply(y_hat, self.dataY), axis=1)))
print('第', iteration, '次迭代的loss:', loss)
updated_theta = np.zeros(self.theta.shape)
for j in range(self.n_classes):
temp = (self.dataY[:, j] - y_hat[:, j]).reshape((self.datasize, 1))
theta_j = self.theta[:, j] + self.alpha * np.sum(np.multiply(temp, self.dataX), axis=0)
updated_theta[:, j] = theta_j
self.theta = updated_theta
print('训练完成!')
def predict(self, testX, testY):
ones = np.ones(testX.shape[0])
testX = np.c_[ones, testX]
z = np.dot(testX, self.theta)
y_hat = np.argmax(z, axis=1)
cnt = 0
n = len(testY)
for i in range(n):
if y_hat[i] == testY[i]:
cnt += 1
print('模型预测正确率:', cnt / n)
return y_hat
if __name__ == "__main__":
dataX, dataY = load_data()
trainX, testX, trainY, testY = train_test_split(dataX, dataY, test_size=0.3, random_state=0)
newTrainX, mu, sigma = normalization(trainX)
newTestX = (testX - mu) / sigma
model = multinomial_logistic_regression(newTrainX, trainY)
model.fit()
y_hat = model.predict(newTestX, testY)
print("预测值:", y_hat)
print("真实值:", testY)
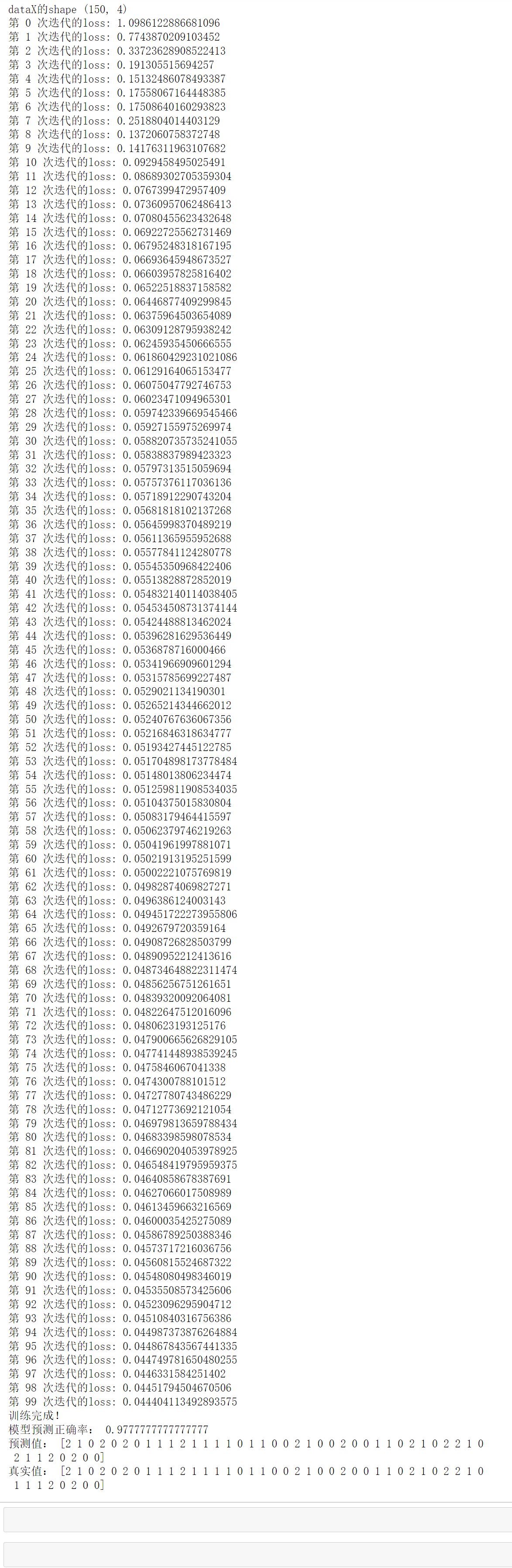
代码执行结果:
3.总结
以上就是逻辑斯蒂回归的全部内容了,推导过程有些复杂,希望大家可以自己推导一下。
参考文献:
1. 多类别逻辑回归(Multinomial Logistic Regression)Original: https://blog.csdn.net/weixin_44142858/article/details/121545450
Author: 期待诗和远方
Title: 逻辑回归算法(Logistic Regression)原理(含多项逻辑斯蒂回归对参数求偏导的推导过程)及numpy代码实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/760509/
转载文章受原作者版权保护。转载请注明原作者出处!