

爬取汽车之家图片
- 需求:爬取汽车之家某一个汽车的图片
一、 普通scrapy
第一步 页面分析
- 目标url:
https://car.autohome.com.cn/photolist/series/265/p1/
https://car.autohome.com.cn/photolist/series/265/p2/ 第二页
https://car.autohome.com.cn/photolist/series/265/p3/ 第三页 - 观察网页很明显265是该车型的编码
- 页数p1 p2编码
- 观察图片url:
- 大图:https://car2.autoimg.cn/cardfs/product/g25/M0B/29/A8/800x0_1_q95_autohomecar__wKgHIlrwJHaAK02EAAsUwWrTmXY510.jpg
- 小图:
https://car2.autoimg.cn/cardfs/product/g25/M0B/29/A8/240x180_0_q95_c42_autohomecar__wKgHIlrwJHaAK02EAAsUwWrTmXY510.jpg
第二步 实现步骤
- 1 创建scrapy项目
scrapy startproject lsls
2 创建爬虫程序
scrapy genspider hy car.autohome.com.cn
3 实现逻辑

; (一)准备程序
在terminal终端输入
scrapy startproject lsls
爬虫程序名最好不要和爬虫程序重名
scrapy genspider hy car.autohome.com.cn
- 创建start.py文件,放在与scrapy.cfg同层目录下
要运行整个程序的话,只需要运行这个文件
from scrapy import cmdline
cmdline.execute('scrapy crawl hy'.split())
cmdline.execute(['scrapy','crawl','hy'])
(二)setting.py文件
- 固定格式
LOG_LEVEL = 'WARNING'
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
开启管道
ITEM_PIPELINES = {
'lsls.pipelines.LslsPipeline': 300,
}
开启自定义下载中间键,设置随机请求头
DOWNLOADER_MIDDLEWARES = {
# 'lsls.middlewares.LslsDownloaderMiddleware': 543,
'lsls.middlewares.UserAgentDownloaderMiddleware': 543
}
(三)hy.py文件
import scrapy
from lsls.items import LslsItem
class HySpider(scrapy.Spider):
name = 'hy'
allowed_domains = ['car.autohome.com.cn']
start_urls = ['https://car.autohome.com.cn/photolist/series/265/p1/']
print('爬取第1页')
n = 1
def parse(self, response):
imgList = response.xpath('//ul[@id="imgList"]/li')
for img in imgList:
src = img.xpath('./a/img/@src').get()
if src[-1] != 'g':
src = img.xpath('./a/img/@src2').get()
# 拼接url 并换成大图
url = 'https:' + src.replace('240x180_0_q95_c42','800x0_1_q95')
title = img.xpath('./div/a/text()').get()
item = LslsItem(
title = title,
url = url
)
yield item
# 翻页
next_btn = response.xpath('//div[@class="page"]/a[@class="page-item-next"]')
if next_btn:
self.n+=1
print(f'爬取第{self.n}页')
url = f'https://car.autohome.com.cn/photolist/series/265/p{self.n}/'
yield scrapy.Request(url=url)
else:
print('页面爬取完毕')
(四)item.py文件
import scrapy
class LslsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
url = scrapy.Field()
pass
(五)middlewares.py文件
- 不变
from scrapy import signals
from fake_useragent import UserAgent
import random
class UserAgentDownloaderMiddleware:
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"]
# 第一种方式 里面改变策略
# def process_request(self, request, spider):
# user_agent = random.choice(self.USER_AGENTS)
# request.headers['User-Agent'] = user_agent
# 第二种方式
def process_request(self, request, spider):
ua = UserAgent()
user_agent = ua.random
request.headers['User-Agent'] = user_agent
(六)pipelines.py文件
import urllib.request
class LslsPipeline:
def open_spider(self, spider):
self.title_list = {}
def process_item(self, item, spider):
url = 'https:'+ dict(item)['url']
title = dict(item)['title']
if name in self.title_list.keys():
self.title_list[title]+=1
else:
self.title_list.setdefault(title,1)
path = r'D:\python_lec\全栈开发\爬虫项目\爬虫小练习\qczj\图片下载'
urllib.request.urlretrieve(url=url,filename=path+f'\{title} {self.title_list[title]}.jpg')
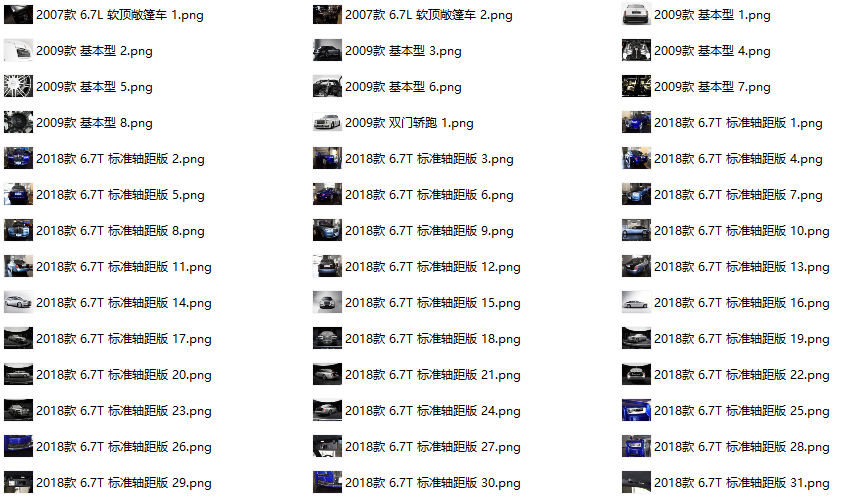
- 保存的是800大小的图
二、 crawlspider
- 翻页过程更加简单
(一)准备程序
scrapy startproject qczj
爬虫程序名最好不要和爬虫程序重名
cd qczj
scrapy genspider lsls car.autohome.com.cn
(二)lsls.py
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from qczj.items import QczjItem
class LslsSpider(CrawlSpider):
name = 'lsls'
allowed_domains = ['car.autohome.com.cn']
start_urls = ['https://car.autohome.com.cn/photolist/series/265/p1/']
rules = (
# 主页
Rule(LinkExtractor(allow=r'https://car.autohome.com.cn/photolist/series/265/p[1-17]/'),follow=True),
# 详情页
Rule(LinkExtractor(allow=r'https://car.autohome.com.cn/photo/series/31145/\d+/\d+.html'), callback='parse_item'),
)
def parse_item(self, response):
item = QczjItem()
img = response.xpath('//*[@id="img"]/@src').get()
name = response.xpath('//*[@id="czts"]/div/div/p[1]/a/text()').get()
item['img'] = img
item['name'] = name
return item
(三)pipelines.py
import urllib.request
class QczjPipeline:
def open_spider(self, spider):
self.title_list = {}
def process_item(self, item, spider):
url = 'https:'+ dict(item)['img']
name = dict(item)['name']
if name in self.title_list.keys():
self.title_list[name]+=1
else:
self.title_list.setdefault(name,1)
path = r'D:\python_lec\全栈开发\爬虫项目\爬虫小练习\qczj\图片下载'
urllib.request.urlretrieve(url=url,filename=path+f'\{name} {self.title_list[name]}.jpg')
Original: https://blog.csdn.net/weixin_43761516/article/details/117636488
Author: 洋芋本人
Title: 爬取汽车之家图片 – scrapy – crawlspider – python爬虫案例
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/790032/
转载文章受原作者版权保护。转载请注明原作者出处!