

逆向爬虫17 Scrapy中间件
在学习Scrapy之前,我们已经学了很多伪装防反爬的爬虫技术。
目标: 如何在Scrapy框架中也使用这些技术呢?这是本节要讨论的问题。本节要讨论的防反爬技术有
- 处理登录Cookies
- 处理UA
- 处理代理IP
- 结合Selenium进行浏览器环境伪装
- 利用Selenium获取Cookies
一、Scrapy处理登录Cookies问题
本节依然利用17k.com小说网来说明登录Cookies问题。
原理说明:
回忆一下之前的Cookies是如何添加的。
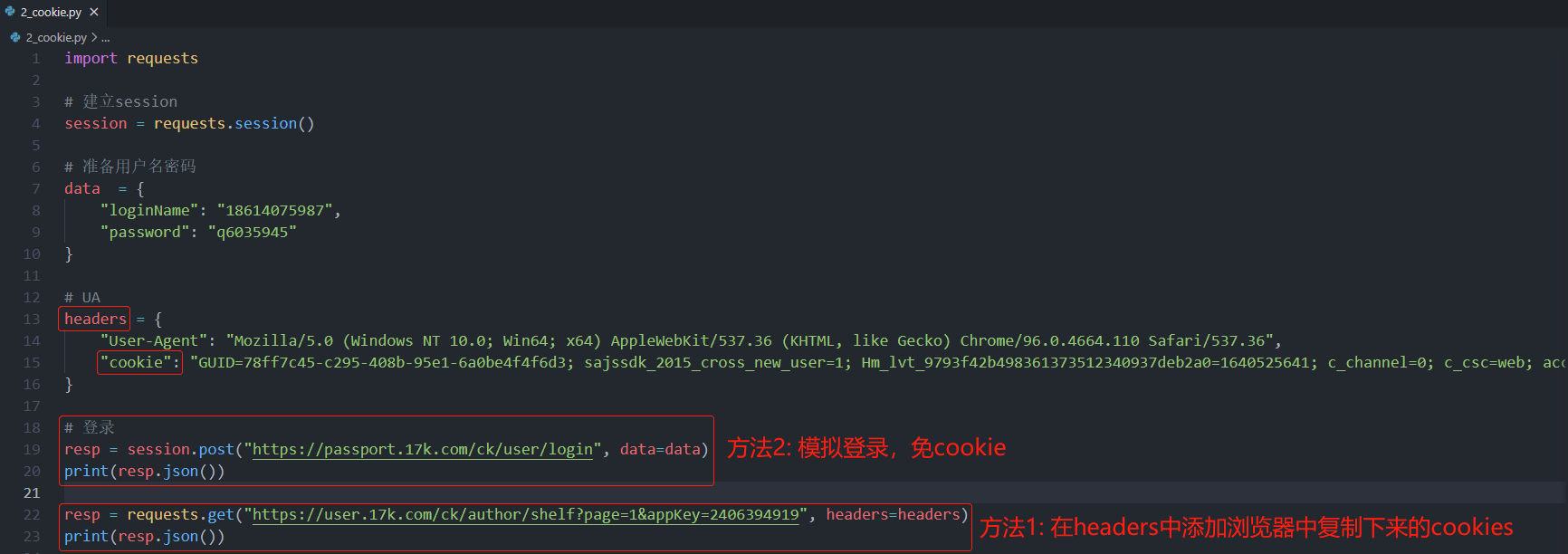

两种方式:
- 在浏览器中手动登录,从浏览器开发者工具中将cookies复制出来,放进HTTP请求头中。由于requests不会记住与服务器通信过程中的参数,每次通信时都是建立新的连接,因此每次都需要加上请求头。
- 使用requests.session()会话对象发送post请求模拟登录,无需复制Cookies,会话会记住与服务器通信过程中的参数,无需每次通信时都加上请求头,更方便。
在Scrapy中,同样也可以用这两种方式来解决登录Cookies问题。
再回顾一下Scrapy发起HTTP的流程:
在 爬虫 中指定start_urls,封装成request请求对象交给 调度器, 引擎 从 调度器 中取出requests对象交给 下载器, 下载器 去发起HTTP请求,并接收服务器返回的响应,封装成response响应对象交给 引擎, 引擎 再转交给 爬虫,完成了一次HTTP请求。
Cookies本身属于请求头内部的参数,需要添加到request对象中,而request对象是在 爬虫 中生成的,因此这部分的功能需要在 爬虫 中来添加。 再回顾一下之前使用Scrapy的案例 ,每次我们都只需要指定start_urls,Scrapy会自动帮我们完成requests对象封装。当然Scrapy是不会知道我们要添加什么Cookies的,因此我们需要知道Scrapy是如何帮我们封装request对象的,这就需要一点看Scrapy源码的能力和面向对象的知识了。
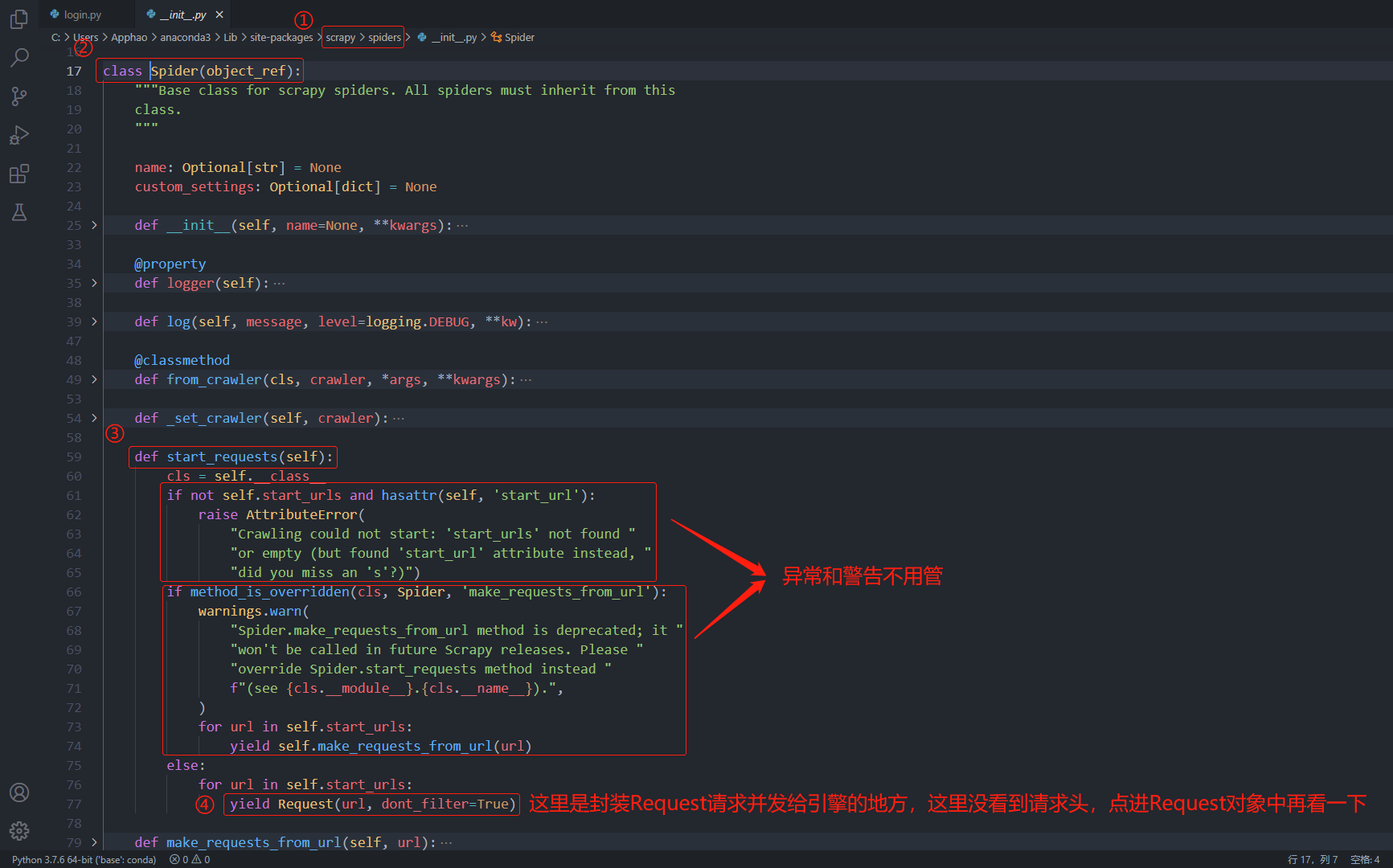
已知的是,request对象是由 爬虫 模块完成的,而 爬虫 模块是继承了scrapy.Spider的一个对象,我们在子对象中指定了start_urls,却没有指定HTTP请求头,那么指定请求头的工作,多半是在父对象scrapy.Spider中完成了,因此去看一下scrapy.Spider的源码
; scrapy.Spider类
Request类
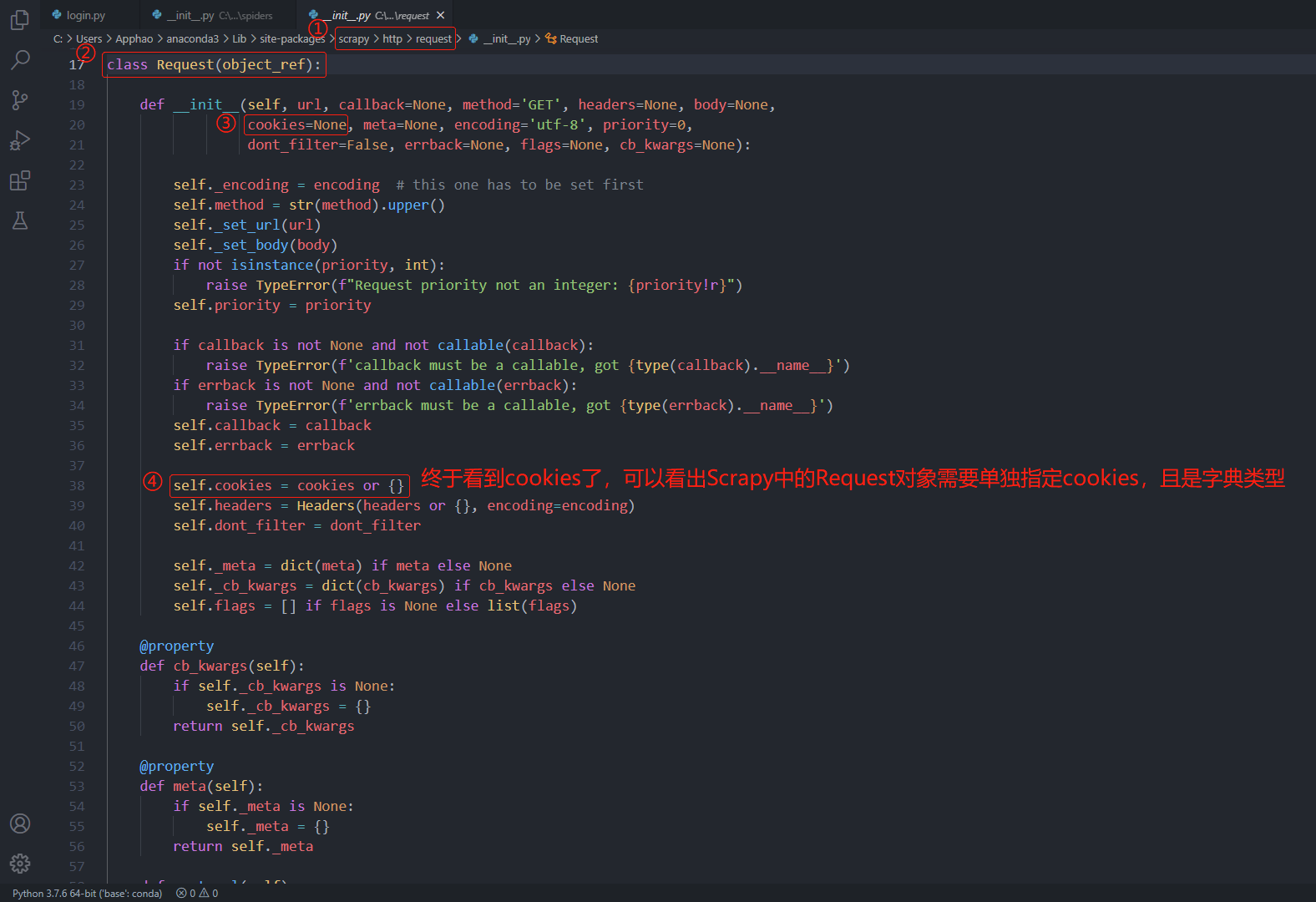
因此,通过阅读Scrapy源码,我们知道了 爬虫 默认继承的scrapy.Spider对象的start_requests函数是不会指定请求头参数的,如果我们需要自己指定请求头参数,就必须重写父类scrapy.Spider中的start_requests函数,这是面向对象的知识,应该是属于继承多态的特性。当父类的功能不满足子类的需求时,子类可以重写父类中的功能,然后利用面向对象中多态的特性,最后根据调用过程中传递的对象类型,来判断是调用父类的方法还是子类中重写的方法。
因此,我们就在 爬虫 模块中,重写一下start_requests函数。 这是方式1,在浏览器中登录成功后,复制Cookiess信息。
; 重写start_requests方法1(访问时带上Cookies)
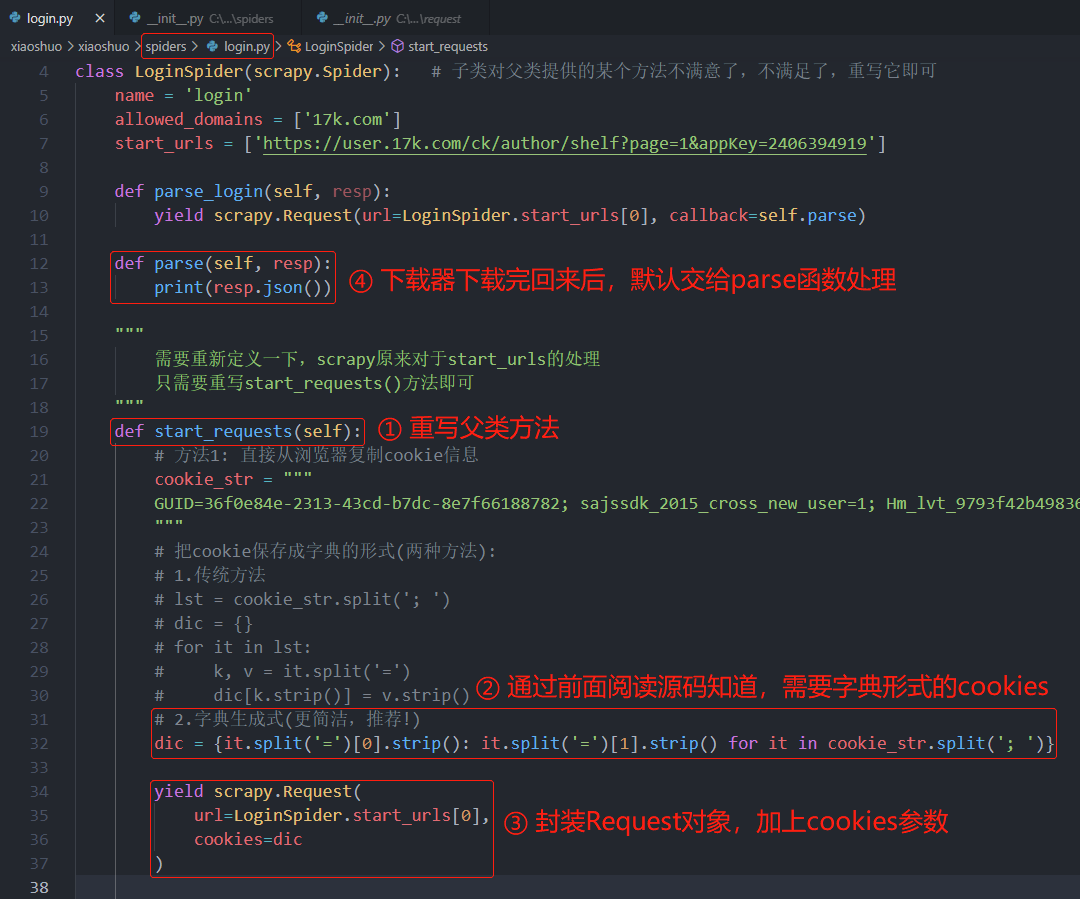
下面再看一下方式2,模拟浏览器登录。
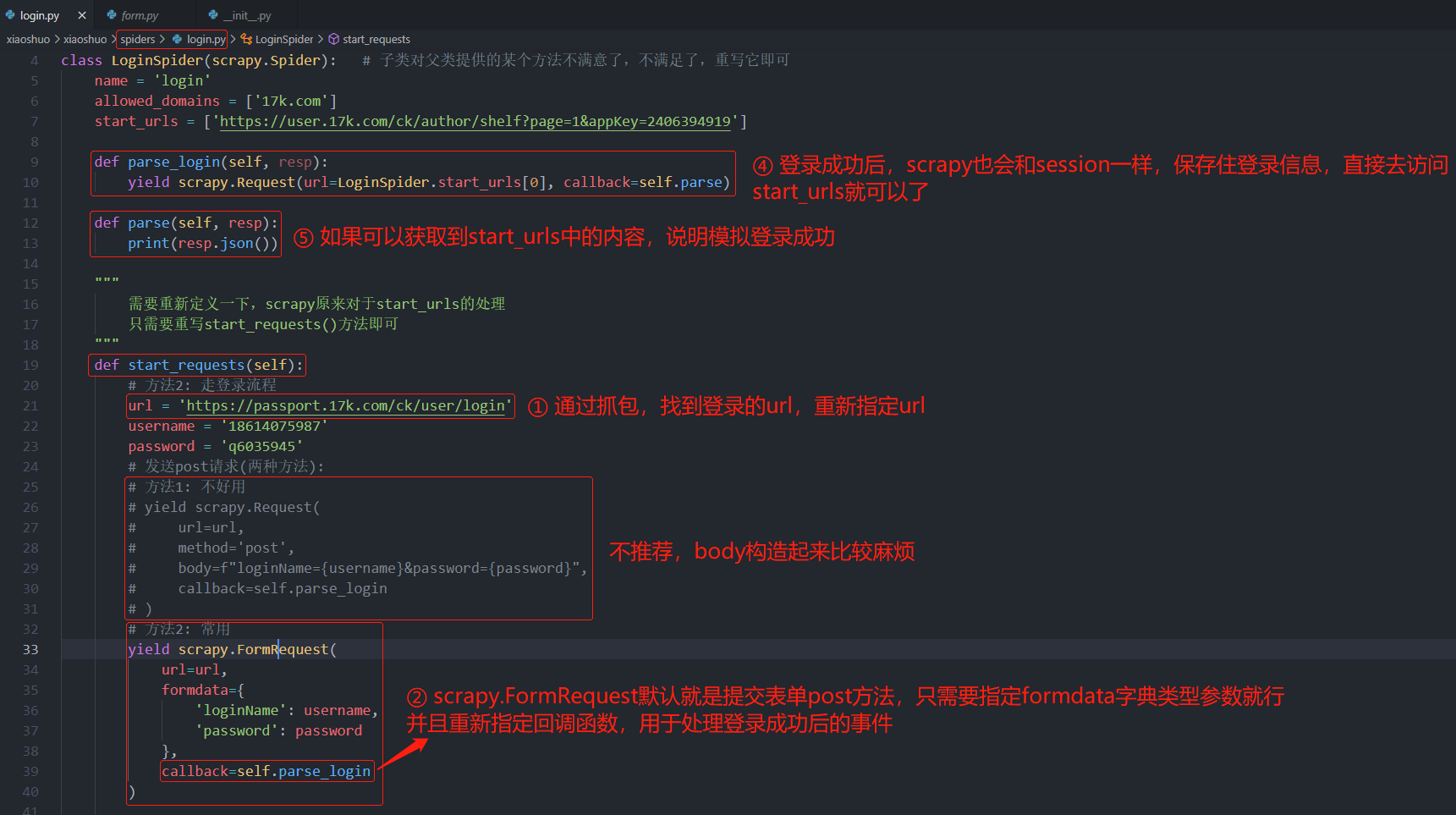
重写start_requests方法2(模拟浏览器登录)
; 有感而发
这部分内容又让我想起了之前考研时听过的一句话: 不要强求不可知,要从已知推未知。 回顾整个过程,虽然Scrapy本身是比较未知且陌生的东西,但是里面所用到的知识点,其实就是一些Scrapy工作流程,网络基础和面向对象中的内容。理论上即使没有老师带着走,我们依然应该能够通过过去学到的东西,自己一点一点地把整个过程推理出来。
login.py源码
import scrapy
class LoginSpider(scrapy.Spider):
name = 'login'
allowed_domains = ['17k.com']
start_urls = ['https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919']
def parse_login(self, resp):
yield scrapy.Request(url=LoginSpider.start_urls[0], callback=self.parse)
def parse(self, resp):
print(resp.json())
"""
需要重新定义一下,scrapy原来对于start_urls的处理
只需要重写start_requests()方法即可
"""
def start_requests(self):
url = 'https://passport.17k.com/ck/user/login'
username = 'xxxxxxxxxx'
password = 'xxxxxxxxxx'
yield scrapy.FormRequest(
url=url,
formdata={
'loginName': username,
'password': password
},
callback=self.parse_login
)
二、Scrapy的中间件
在说明如何处理后面几种防反爬技术前,需要先引入一下Scrapy的中间件。因为这些防反爬功能,都是写在Scrapy的下载器中间件中。
中间件的作用:负责处理 引擎 和 爬虫 以及 引擎 和 下载器 之间的请求和响应,主要是可以对request和response做预处理,为后面的操作做好充足的准备。在Scrapy中有两种中间件,分别是 下载器中间件 和 爬虫中间件 。
1. DownloaderMiddleware下载器中间件
下载器中间件位于 引擎 和 下载器 之间, 引擎 在获取到request对象后,会交给 下载器 去下载,在这之间我们可以设置 下载器中间件 ,它的执行流程:
引擎 拿到request ==> 中间件1 (process_request) ==> 中间件2 (process_request) … ==> 下载器拿到request
引擎 拿到response
Original: https://blog.csdn.net/weixin_40743639/article/details/122779457
Author: 一个小黑酱
Title: 逆向爬虫17 Scrapy中间件
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/788882/
转载文章受原作者版权保护。转载请注明原作者出处!