

今日内容概要
- 1 > 聚合查询
- 2 > 分组查询
- 3 > F与Q查询
* - 3.1 > F查询
- 3.2 > Q查询
- 4 > ORM查询优化
* - 4.1 > only与defer
- 4.2 > select_related和prefetch_related
- 5 > ORM常见字段
- 6 > 重要参数
- 7 > 事务操作
- 8 > ORM执行原生SQL
- 9 > 多对多三种创建方式
* - 9.1 > 全自动(常见)
- 9.2 > 全手动(使用频率最低)
- 9.3 > 半自动(常见)
1 > 聚合查询
MySQL聚合函数有以下几种:
max\min\sum\count\avg
Django中聚合函数也是有以上几种,关键字是aggregate,具体操做如下:
'''没有分组也可以使用聚合函数 默认整体就是一组'''
from django.db.models import Max,Min,Sum,Avg,Count
res = models.Book.objects.aggregate(Max('price'))
print(res)
{'price__max': Decimal('29888.88')}
res = models.Book.objects.aggregate(
Max('price'), Min('price'),Sum('price'),Avg('price'),Count('pk')
)
print(res)
{'price__max': Decimal('29888.88'),
'price__min': Decimal('1699.80'),
'price__sum': Decimal('146028.12'),
'pk__count': 8}
2 > 分组查询
Mysql分组操做关键字是group by。
orm的分组操做关键字是annotate。
若orm操做执行分组操做的时候产生报错,可能需要去修改sql_mode,移除only_full_group_by。
''' 分组查询小练习 '''
'''按照表名分组'''
from django.db.models import Count,Min,Sum
res = models.Book.objects.annotate(author_num=Count('authors__pk')).values('title','author_num')
print(res)
res = models.Publish.objects.annotate(price=Min('book__price')).values('name','book__title','price')
print(res)
res = models.Book.objects.annotate(author_num=Count('authors__pk')).filter(author_num__gt=1).values('title','author_num')
print(res)
res = models.Author.objects.annotate(book_price_sum=Sum('book__price')).values('name', 'book_price_sum')
print(res)
"""
上述操作都是以表为单位做分组
如果想要以表中的某个字段分组如何操作
"""
res = models.Book.objects.values('publish_id').annotate(book_num=Count('pk')).values('publish_id','book_num')
print(res)
3 > F与Q查询
当表中已经有数据的情况下 添加额外的字段 需要指定默认值或者可以为null
方式1
IntegerField(verbose_name='销量',default=1000)
方式2
IntegerField(verbose_name='销量',null=True)
方式3
在迁移命令提示中直接给默认值
3.1 > F查询
查询库存大于销量的书籍
res = models.Book.objects.filter(kucun > maichu)
res = models.Book.objects.filter(kucun__getmaichu)
当查询条件的左右两边的数据都需要表中的数据 可以使用F查询
from django.db.models import F
res = models.Book.objects.filter(kucun__gt=F('maichu'))
print(res)
将所有书的价格提升1000块
from django.db.models import F
models.Book.objects.filter(price=F('price')+1000)
将所有书的名称后面加上_爆款后缀
'''
如果要修改char字段
(千万不能用上面对数值类型的操作!!!)
需要使用下列两个方法
'''
from django.db.models.functions import Concat
from django.db.models import Value
res = models.Book.objects.update(name=Concat(F('title'), Value('爆款')))
3.2 > Q查询
查询价格大于20000或者卖出大于1000的书籍
'''filter括号内多个条件默认是and关系 无法直接修改'''
res = models.Book.objects.filter(price__gt=20000,maichu__gt=1000)
print(res)
print(res.query)
'''使用Q对象 就可以支持逻辑运算符'''
res = models.Book.objects.filter(Q(price__gt=20000), Q(maichu__gt=1000))
'''
,
,
]>
'''
res = models.Book.objects.filter(Q(price__gt=20000) | Q(maichu__gt=1000))
'''
,
,
,
,
,
,
,
]>
'''
res = models.Book.objects.filter(~Q(price__gt=5000))
print(res)
'''
]>
'''
Q对象进阶用法
'''
当我们需要编写一个搜索功能 并且条件是由用户指定 这个时候左边的数据就是一个字符串
'''
q_obj = Q()
q_obj.connector = 'or'
q_obj.children.append(('price__gt',20000))
q_obj.children.append(('maichu__gt',1000))
res = models.Book.objects.filter(q_obj)
print(res.query)
4 > ORM查询优化
在IT行业 针对数据库 需要尽量做 能不’麻烦’它就不’麻烦’它
orm查询默认都是惰性查询(能不消耗数据库资源就不消耗)
光编写orm语句并不会直接指向SQL语句 只有后续的代码用到了才会执行
orm查询默认自带分页功能(尽量减轻单次查询数据的压力)
4.1 > only与defer
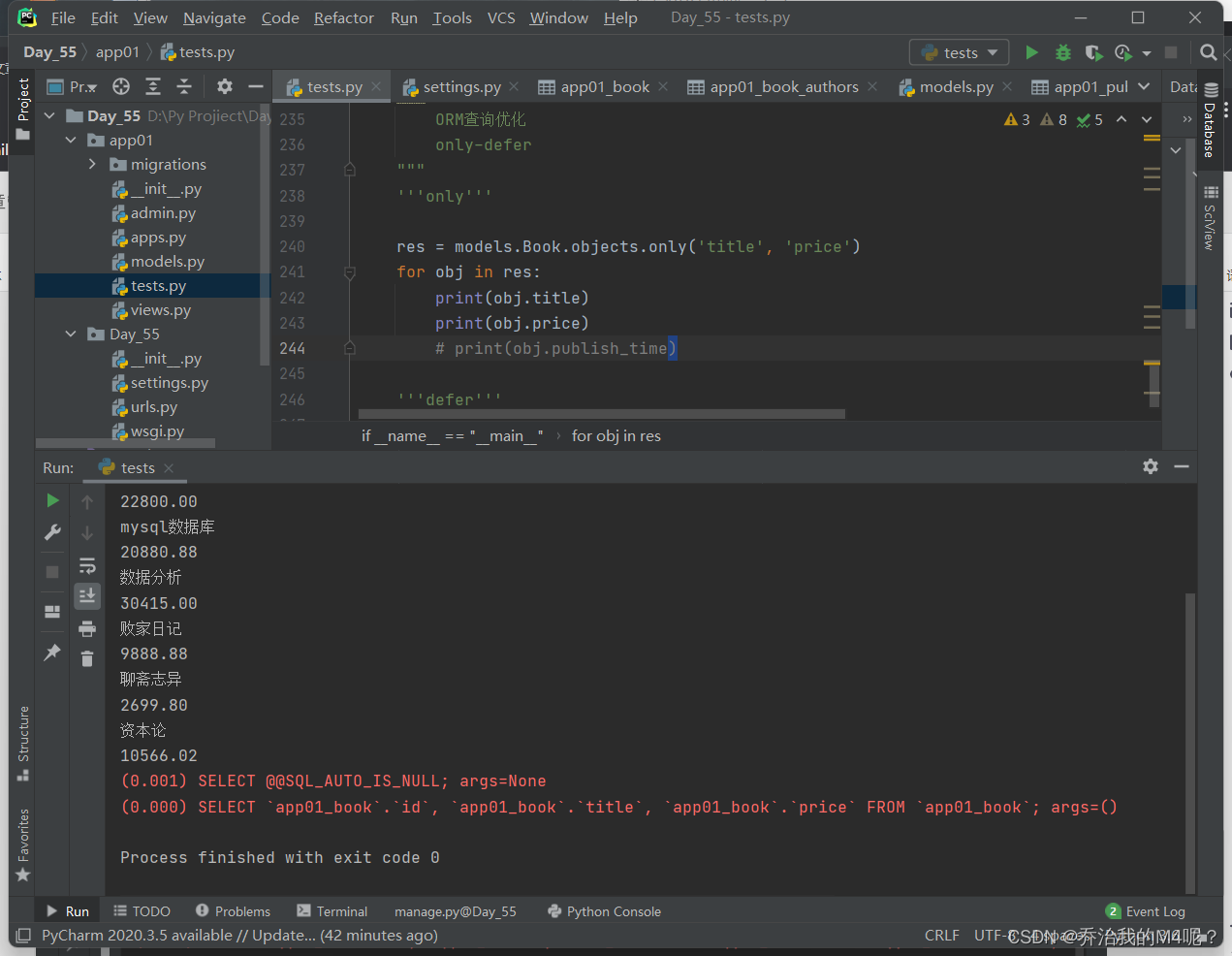
only会产生对象结果集 ,对象点括号内出现的字段不会再走数据库查询
但是如果点击了括号内没有的字段也可以获取到数据 但是每次都会走数据库查询
具体操做如下:
res = models.Book.objects.only('title', 'price')
for obj in res:
print(obj.title)
print(obj.price)
print(obj.publish_time)

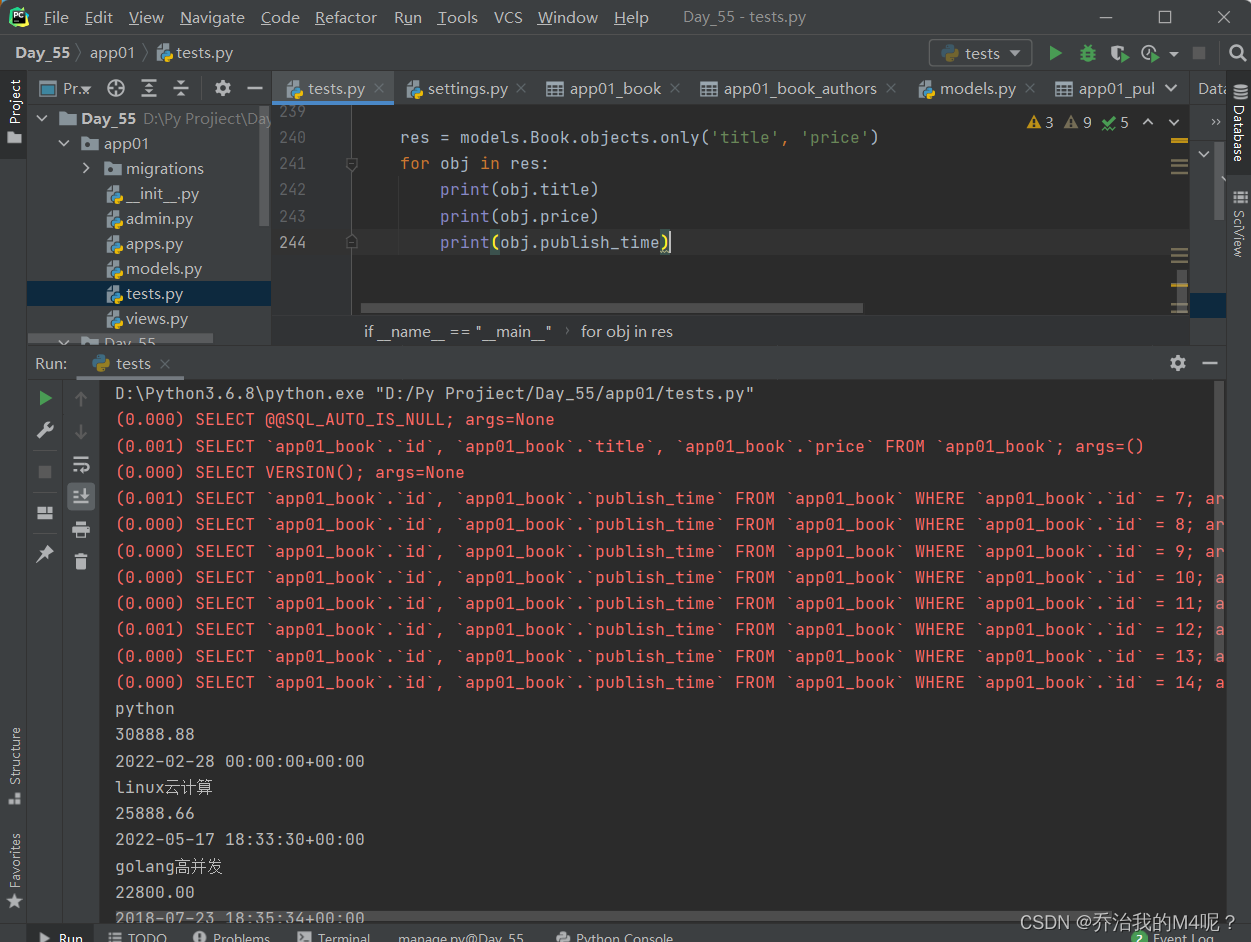
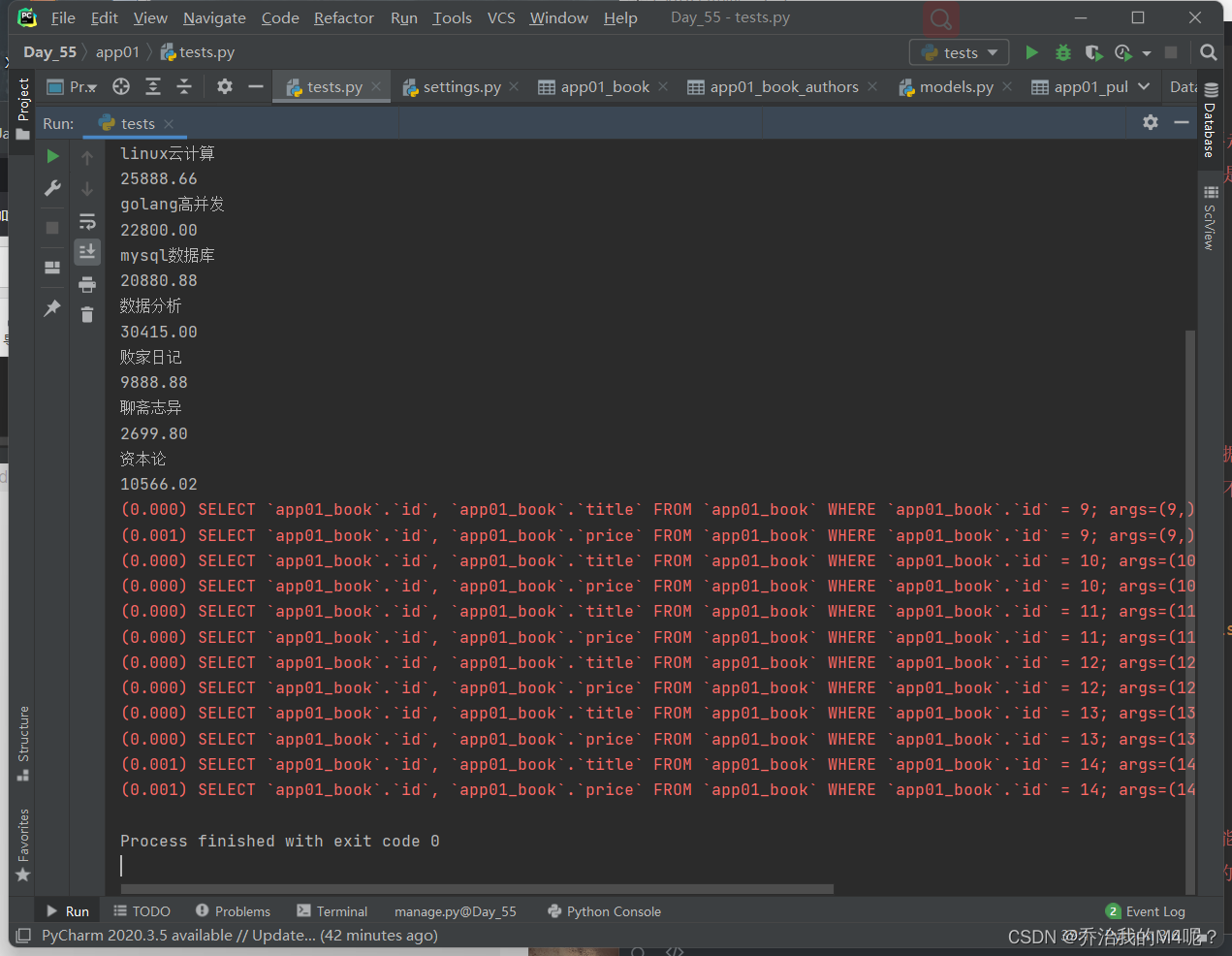
defer与only刚好相反 对象点括号内出现的字段会走数据库查询
如果点击了括号内没有的字段也可以获取到数据 每次都不会走数据库查询
res = models.Book.objects.defer('title', 'price')
for obj in res:
print(obj.title)
print(obj.price)
print(obj.publish_time)
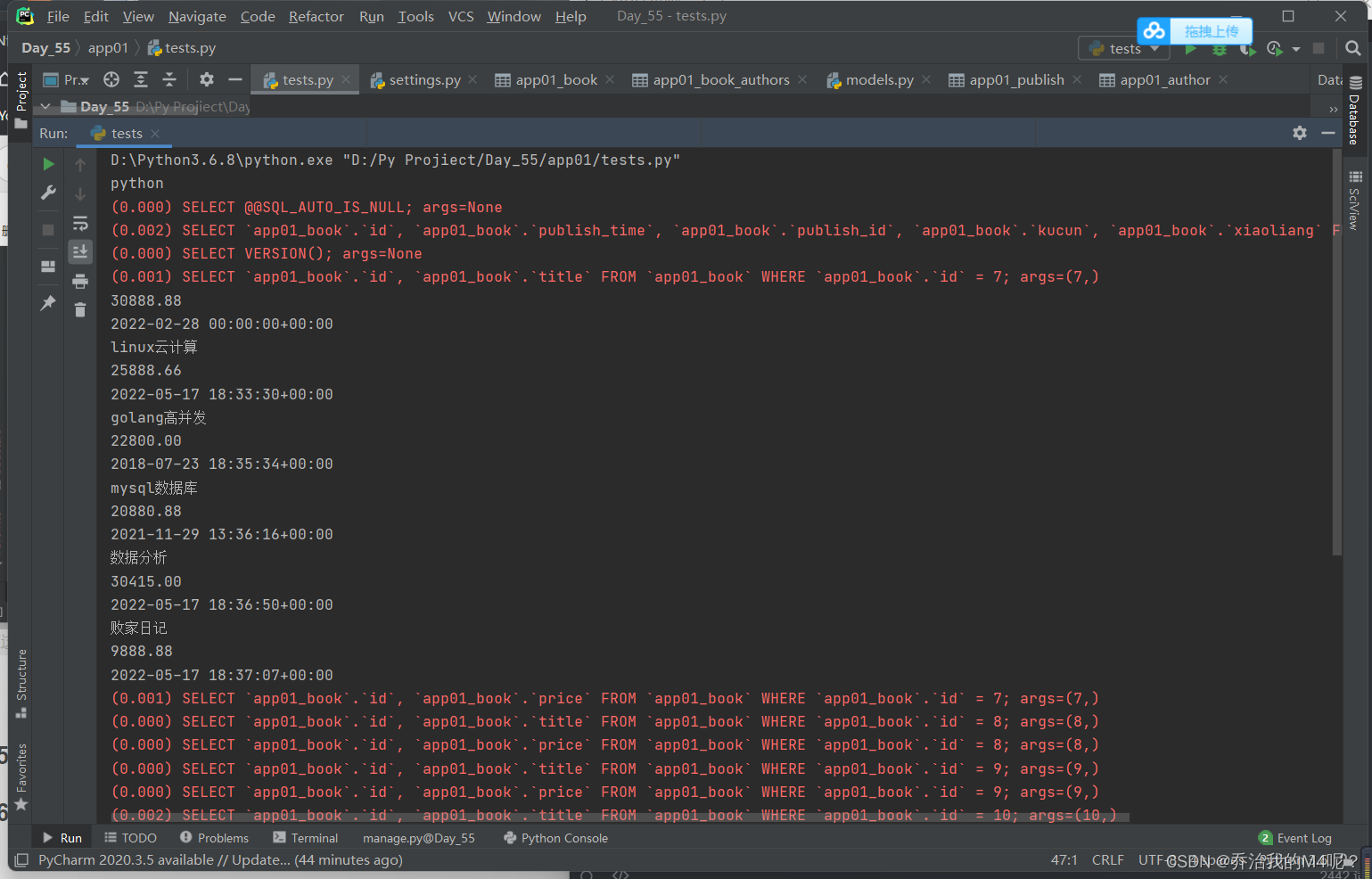
select_related括号内只能传一对一和一对多字段的外键字段 不能传多对多字段。
效果是内部直接连接表(inner join) 然后将连接之后的大表中所有的数据全部封装到数据对象中。
后续对象通过正反向查询跨表 内部不会再走数据库查询。
''' select_related '''
res = models.Book.objects.select_related('publish')
for obj in res:
print(obj.title)
print(obj.publish.name)
print(obj.publish.addr)

prefetch_related会将多次查询之后的结果封装到数据对象中 。
后续对象通过正反向查询跨表 内部不会再走数据库查询。
''' prefetch_related '''
res = models.Book.objects.prefetch_related('publish')
for obj in res:
print(obj.title)
print(obj.publish.name)
print(obj.publish.addr)
5 > ORM常见字段
AutoField()
int自增列,必须填入参数 primary_key=True。当model中如果没有自增列,则自动会创建一个列名为id的列
CharField()
字符类型,必须提供max_length参数, max_length表示字符长度。
这里需要知道的是Django中的CharField对应的MySQL数据库中的varchar类型,没有设置对应char类型的字段
但是Django允许我们自定义新的字段。具体操做如下
from django.db import models
class FixCharField(models.Field):
'''
自定义的char类型的字段类
'''
def __init__(self,max_length,*args,**kwargs):
self.max_length=max_length
super().__init__(max_length=max_length,*args,**kwargs)
def db_type(self, connection):
'''
限定生成的数据库表字段类型char,长度为max_length指定的值
:param connection:
:return:
'''
return 'char(%s)'%self.max_length
class Class(models.Model):
id=models.AutoField(primary_key=True)
title=models.CharField(max_length=32)
class_name=FixCharField(max_length=16)
gender_choice=((1,'男'),(2,'女'),(3,'保密'))
gender=models.SmallIntegerField(choices=gender_choice,default=3)
IntergerField()
整数列(有符号的) -2147483648 ~ 2147483647
DecimalField()
10进制小数
参数:
max_digits,小数总长度
decimal_places,小数位长度
DateField()
日期字段,日期格式 YYYY-MM-DD,相当于Python中的datetime.date()实例。
参数:
auto_now: 每次保存对象时,自动将字段设置为现在。
用于"最后修改"的时间戳。注意当前日期是使用 always;
它不只是一个默认值,你可以覆盖。
auto_now_add:在首次创建对象时自动将字段设置为现在。
用于创建时间戳。注意当前日期是使用 always;
它不只是一个默认值,你可以覆盖。
DateTimeField()
日期时间字段,格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ],相当于Python中的datetime.datetime()实例。
参数:
auto_now:
auto_now_add:
BigIntergerField()
长整型(有符号的) -9223372036854775808 ~ 9223372036854775807
BooleanField()
布尔值类型
TextField()
文本类型
FileField()
字符串,路径保存在数据库,文件上传到指定目录
参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
EmailField()
字符串类型,Django Admin以及ModelForm中提供验证机制
6 > 重要参数
primary_key
将字段设置主键字段 一个Model只允许设置一个字段为primary_key
max_length
最大长度
verbose_name
给字段加备注
null
用于表示某个字段可以为空。
default
默认值
max_digits
DecimalField(max_digits=8, decimal_places=2)
decimal_places
DecimalField(max_digits=8, decimal_places=2)
unique
如果设置为unique=True 则该字段在此表中必须是唯一的 。
db_index
为该字段设置默认值。
auto_now
配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库。
auto_now_add
配置上auto_now=True,每次更新数据记录的时候会更新该字段。
choices
用于可以被列举完全的数据
eg:性别 学历 工作经验 工作状态
class User(models.Model):
username = models.CharField(max_length=32)
password = models.IntegerField()
gender_choice = (
(1,'男性'),
(2,'女性'),
(3,'变性')
)
gender = models.IntegerField(choices=gender_choice)
user_obj.get_gender_display()
to
设置要关联的表。
to_field
设置要关联的字段。
db_constraint
db_constraint=False,这个就是保留跨表查询的便利(双下划线跨表查询),
但是不用约束字段了,一半公司都用false,这样就省的报错,因为没有了约束(Field字段对象,既约束,又建立表与表之间的关系)
外键字段中可能还会遇到related_name参数
外键字段中使用related_name参数可以修改正向查询的字段名
7 > 事务操作
MySQL事务:四大特性(ACID)
原子性
一致性
独立性
持久性
start transcation;
rollback;
commit;
'''
创建事务代码
'''
from django.db import transaction
try:
with transaction.atomic():
pass
except Exception:
pass
8 > ORM执行原生SQL
用于在orm当中去写原生sql语句代码
from django.db import connection, connections
cursor = connection.cursor()
cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
cursor.fetchone()
models.UserInfo.objects.extra(
select={'newid':'select count(1) from app01_usertype where id>%s'},
select_params=[1,],
where = ['age>%s'],
params=[18,],
order_by=['-age'],
tables=['app01_usertype']
)
9 > 多对多三种创建方式
9.1 > 全自动(常见)
orm自动创建第三张表 但是无法扩展第三张表的字段
authors = models.ManyToManyField(to='Author')
9.2 > 全手动(使用频率最低)
优势在于第三张表完全自定义扩展性高 劣势在于无法使用外键方法和正反向
class Book(models.Model):
title = models.CharField(max_length=32)
class Author(models.Model):
name = models.CharField(max_length=32)
class Book2Author(models.Model):
book_id = models.ForeignKey(to='Book')
author_id = models.ForeignKey(to='Author')
9.3 > 半自动(常见)
正反向还可以使用 并且第三张表可以扩展 唯一的缺陷是不能用
add\set\remove\clear四个方法
class Book(models.Model):
title = models.CharField(max_length=32)
authors = models.ManyToManyField(
to='Author',
through='Book2Author',
through_fields=('book','author')
)
class Author(models.Model):
name = models.CharField(max_length=32)
'''多对多建在任意一方都可以 如果建在作者表 字段顺序互换即可'''
books = models.ManyToManyField(
to='Author',
through='Book2Author',
through_fields=('author','book')
)
class Book2Author(models.Model):
book = models.ForeignKey(to='Book')
author = models.ForeignKey(to='Author')
Original: https://blog.csdn.net/weixin_64178950/article/details/124843869
Author: 乔治我的M4呢?
Title: orm查询方式与优化
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/737241/
转载文章受原作者版权保护。转载请注明原作者出处!