

网站百科数据爬取之反爬策略JS逆向分析(二)
本次分享解析某域网站数据的反爬机制。
此次只做技术分享,如有侵权,请联系删除。
1、分析网站
需求目的:工业品网站百科数据信息。
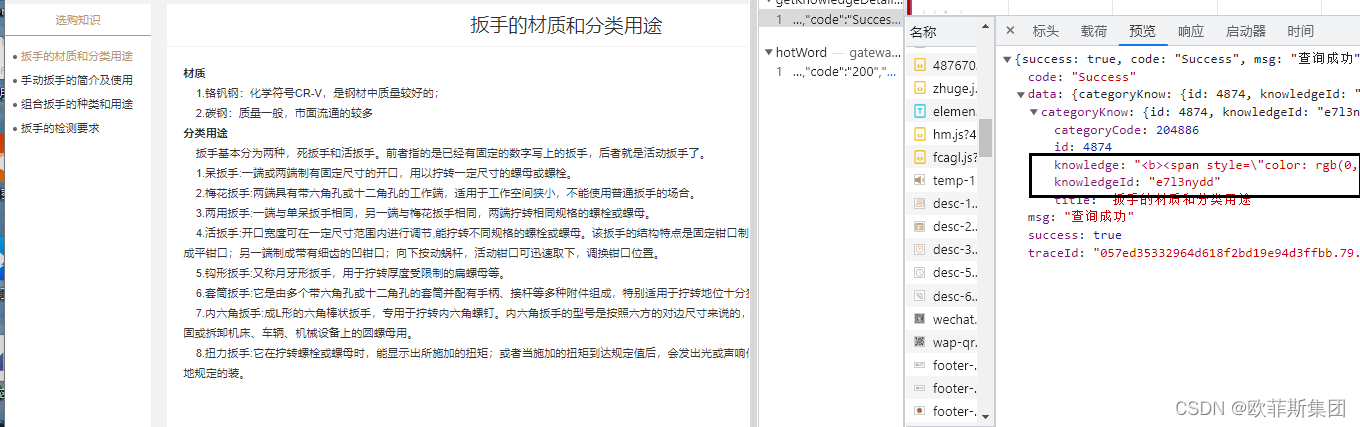

如下图:
明显可以看出三个参数,knowledgeId详情Id、sign加密字段、timestamp时间戳。重点在sign的获取。那就开始sign参数的解密过程吧。
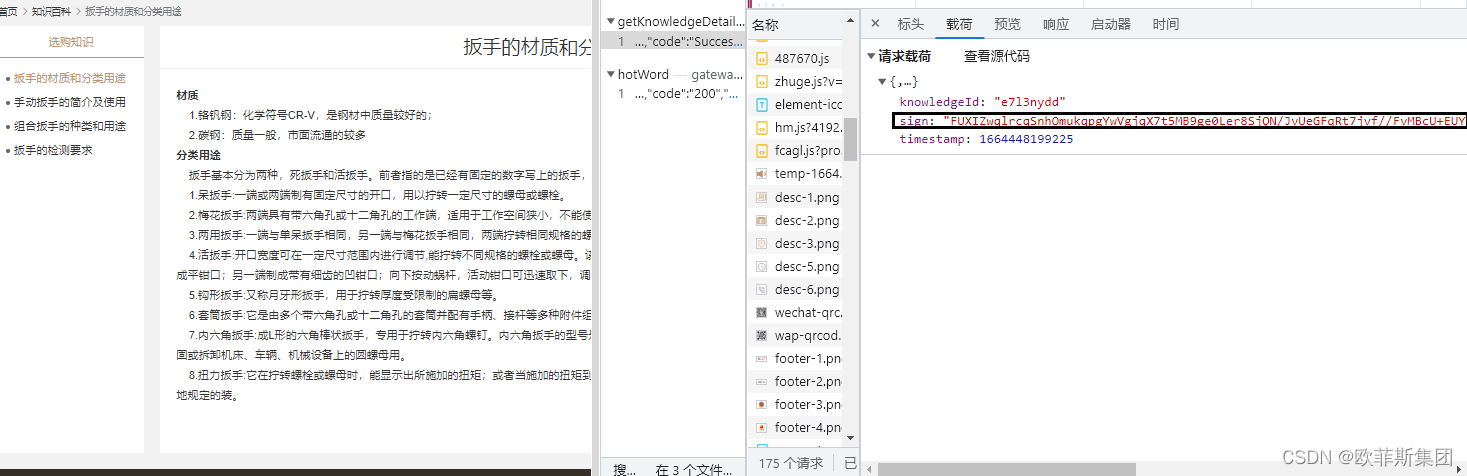
首先找到生成sign的相关js代码。如图所示:

; 2、JS文件解密分析
可以看出跟函数getByCodeKnows有关,分析代码。先放出JS结果代码如下:
var NodeRSA = require('node-rsa')
var privateKeyStr = "MIICXQIBAAKBgQDlOJu6TyygqxfWT7eLtGDwajtNFOb9I5XRb6khyfD1Yt3YiCgQWMNW649887VGJiGr/L5i2osbl8C9+WJTeucF+S76xFxdU6jE0NQ+Z+zEdhUTooNRaY5nZiu5PgDB0ED/ZKBUSLKL7eibMxZtMlUDHjm4gwQco1KRMDSmXSMkDwIDAQABAoGAfY9LpnuWK5Bs50UVep5c93SJdUi82u7yMx4iHFMc/Z2hfenfYEzu+57fI4fvxTQ//5DbzRR/XKb8ulNv6+CHyPF31xk7YOBfkGI8qjLoq06V+FyBfDSwL8KbLyeHm7KUZnLNQbk8yGLzB3iYKkRHlmUanQGaNMIJziWOkN+N9dECQQD0ONYRNZeuM8zd8XJTSdcIX4a3gy3GGCJxOzv16XHxD03GW6UNLmfPwenKu+cdrQeaqEixrCejXdAFz/7+BSMpAkEA8EaSOeP5Xr3ZrbiKzi6TGMwHMvC7HdJxaBJbVRfApFrE0/mPwmP5rN7QwjrMY+0+AbXcm8mRQyQ1+IGEembsdwJBAN6az8Rv7QnD/YBvi52POIlRSSIMV7SwWvSK4WSMnGb1ZBbhgdg57DXaspcwHsFV7hByQ5BvMtIduHcT14ECfcECQATeaTgjFnqE/lQ22Rk0eGaYO80cc643BXVGafNfd9fcvwBMnk0iGX0XRsOozVt5AzilpsLBYuApa66NcVHJpCECQQDTjI2AQhFc1yRnCU/YgDnSpJVm1nASoRUnU8Jfm3Ozuku7JUXcVpt08DFSceCEX9unCuMcT72rAQlLpdZir876";
var pri = "-----*********-----".concat(privateKeyStr, "-----END RSA PRIVATE KEY-----");
var privateKey = new NodeRSA(pri);
function getByCodeKnows() {
var timestamp = new Date().getTime();
var sign = privateKey.sign(timestamp, "base64", "utf8");
item = {"timestamp": timestamp, "sign": sign}
return item
}
console.log(getByCodeKnows())
由代码可以看出JS加密涉及到RSA加密算法,首先就要去下载node-rsa模块,导入模块,变量privateKeyStr从JS文件中得知是个常量,变量pri由privateKeyStr与”—–**—–“和”—–END RSA PRIVATE KEY—–“拼接而来。接着就是对常量pri进行RSA加密生成密钥,前面已经导入了node-rsa模块,直接运用NodeRSA()方法,得到privateKey值。下面就很简单了,一个是获得时间戳、然后就是编码转换获得sign值。这里简单介绍一下RSA算法。
RSA
非对称加密,一般由发送方(客户端)和接收方(服务端)各持有一对公钥和私钥。
私钥可以推出公钥,公钥不能推出私钥。
数据交换的过程中,双方交换自己的公钥。各自私钥不公开。
发送时使用对方的公钥进行加密。接收对方发来的密文时,使用自己私钥进行解密。
发送方使用私钥将信息进行加签(签名),将密文与签名作为参数发起请求。
接收方用自己私钥解密得到的明文,请求方公钥,接收的签名,进行验签(签名验证)。
RSA签名和验签的作用
为了增强数据交换的安全性。
假设不进行签名和验签:
发送方(客户端)的请求,可能被第三方拦截(中间人攻击)。中间人在拦截发送方请求(不知道拦截的请求参数明文)由于接收方(服务端)的公钥是公开的,中间人可以使用公钥对参数加密,替换拦截到的参数密文,发送给原接收方(服务端)。(当然这个发送的参数格式是什么,中间人知道不知道就另寻它路了)这导致接收方(服务端)无法判断得到的请求是否是可信的客户端发送的。(因为请求头什么的都是对的,参数被中间人替换了)发送方如果增加签名可以不用加密请求参数,但第三方拦截后能看到请求参数的明文(参数格式和内容被公开)。
安全性的前提是私钥没有泄露,私钥若被攻击者获取了,那么签名也可以伪造了。
结果展示
运行js代码,查看结果。如下图:
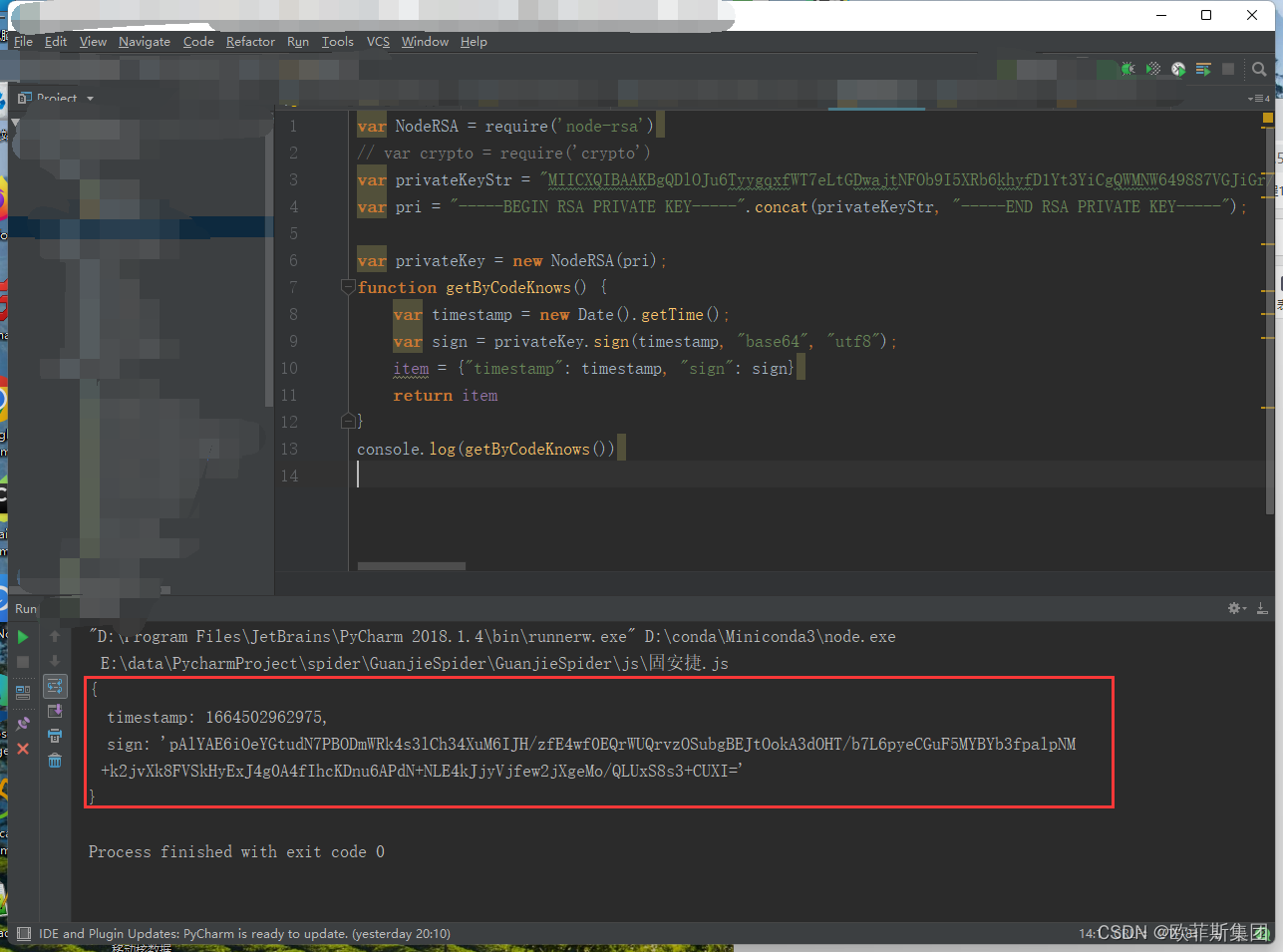
可以看到返回的字典中包括了时间戳以及sign的值,那么接下来就很简单了,可以通过postman模拟接口请求或者直接编写爬虫代码验证,我直接编写爬虫代码实现验证。
; 3.、爬取数据
在得到sign字段的值后,编写爬取代码就简单了,观察得到是POST请求,form表单提交请求数据,编写headers请求头,需要pyexecjs模块是python爬虫库里关于javaScript的一套程序,它能帮你解析python代码的js代码。 有经验的爬虫程序员应该知道,在你的请求头中有一部分是被js代码加密的,而这一套js加密程序就保存在你当前访问的网站中(事实上就是存在本地),每一次访问都需要调用js做加密再请求。这个机制可以抵挡大部分的爬虫程序,除非你模仿js加密程序之后再做请求。你可以模拟js程序写一段python程序,也可以直接把网页里的js代码复制下来,使用pyexecjs模块来运用。其最终实现部分爬虫代码如下:
def get_detail_request(self,knowledgeId,title):
with open(r'js文件路径', 'r',encoding='utf-8') as r:
js = r.read()
jsdm = execjs.compile(js)
result = jsdm.call('getByCodeKnows')
timestamp=result.get("timestamp")
sign=result.get("sign")
start_url="请求的网站链接"
headers = {
"Accept": " application/json, text/plain, */*",
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'Content-Type': ' application/json',
'Origin': ' **********',
'Referer':' **********',
'User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
meta={
"knowledgeId":knowledgeId,
"title":title,
}
params: dict = {"sign":sign,"timestamp":timestamp,"knowledgeId": knowledgeId}
return scrapy.Request( url=start_url,
method="POST",
callback=self.detail_parse,
headers=headers,
meta=meta,
body=json.dumps(params),
dont_filter=True)
def detail_parse(self, response):
title=response.meta["title"]
MongoHelpS = MongoHelp("localhost", "GuAnJie", "baike_category_deatil")
data_text=response.text
data_json=json.loads(data_text)
data=data_json["data"]["categoryKnow"]
knowledge=data["knowledge"]
item={"title":title,"knowledge":knowledge}
MongoHelpS.insert(item)
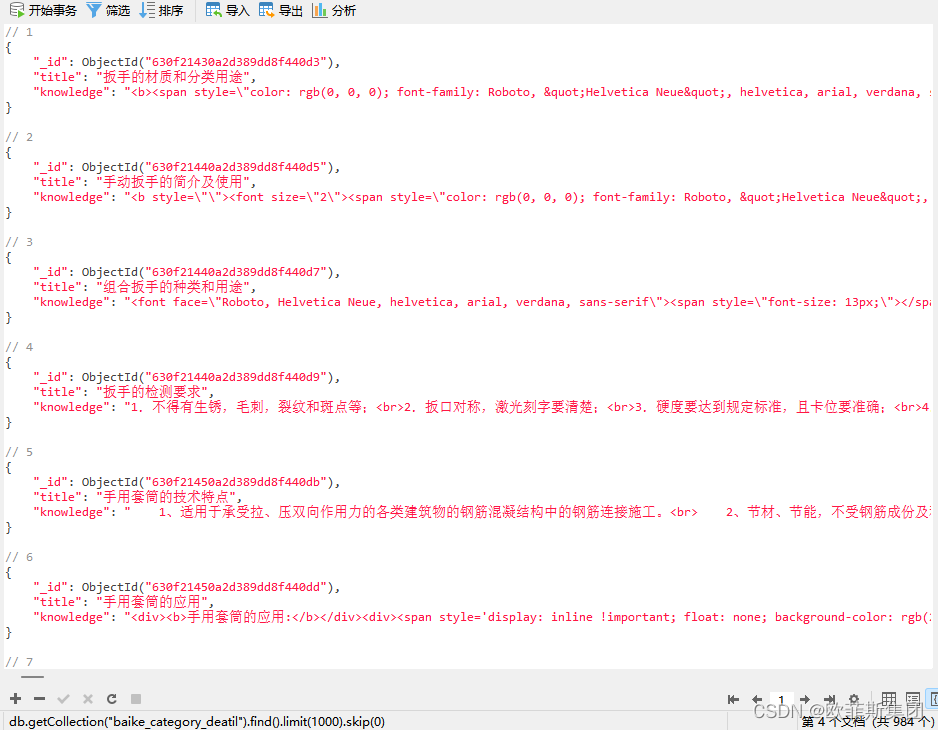
最终实现爬取数据如图:
Original: https://blog.csdn.net/weixin_36723038/article/details/127111965
Author: 欧菲斯集团
Title: JS逆向爬虫案例分享(RSA非对称加密)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/788851/
转载文章受原作者版权保护。转载请注明原作者出处!