

Scrapy架构
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。我们可以通过Scrapy快速完成一个爬虫程序
这是官网的架构图
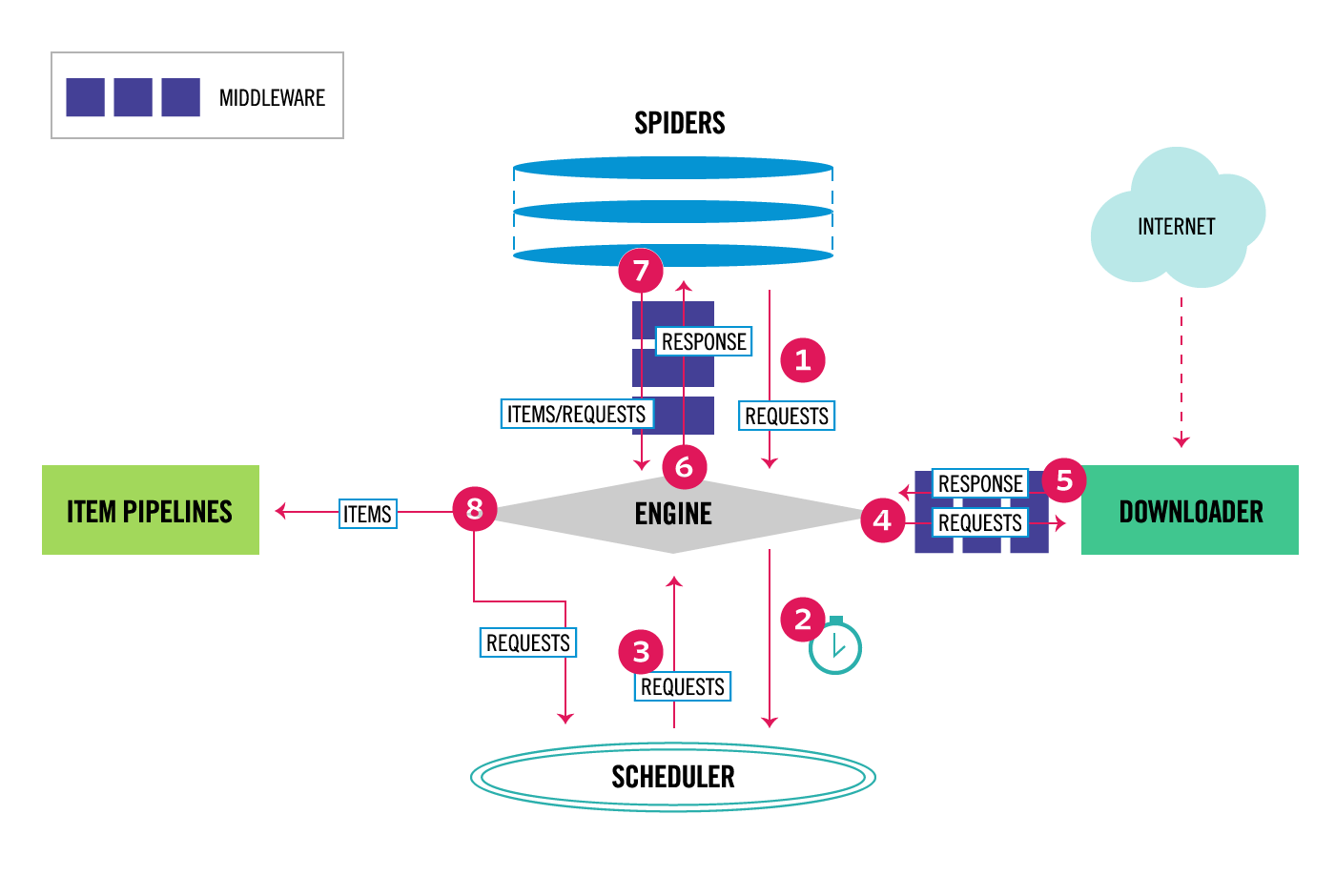

各部分组件的功能如下:
Engine( 引擎 ): 负责 Spider 、 ItemPipeline 、 Downloader 、 Scheduler 中间的通讯,信
号、数据传递等。
Scheduler( 调度器 ): 它负责接受引擎发送过来的 Request 请求,并按照一定的方式进行整理排
列,入队,当引擎需要时,交还给引擎。
Downloader (下载器):负责下载 Scrapy Engine( 引擎 ) 发送的所有 Requests 请求,并将其
获取到的 Responses 交还给 Scrapy Engine( 引擎 ) ,由引擎交给 Spider 来处理,
Spider (爬虫):它负责处理所有 Responses, 从中分析提取数据,获取 Item 字段需要的数
据,并将需要跟进的 URL 提交给引擎,再次进入 Scheduler( 调度器 ).
Item Pipeline( 管道 ) :它负责处理 Spider 中获取到的 Item ,并进行进行后期处理详细分析过滤、存储等)的地方。
Downloader Middlewares (下载中间件):你可以当作是一个可以自定义扩 展下载功能的组
件。
Spider Middlewares ( Spider 中间件):你可以理解为是一个可以自定扩展 和操作引擎和
Spider 中间通信的功能组件(比如进入 Spider 的 Responses; 和从 Spider 出去的 Requests )
所以: 对应上面架构图上的scrapy运行流程就是:
(1)首先我们在spider中发起一个request,将一个需要处理的url提交给engine
(2)engine收到这个请求后会发送给scheduler,所有的requset都需要在scheduler中排队等待被处理
(3)scheduler将排序后的request发送给engine
(4)engine收到这个requset后,向d ownloader发起请求下载url链接里面的数据
(5)d ownloader下载好数据后,将数据都存储在response中,将response交给engine
如果下载失败了,这个引擎告诉调度器,这个request 下载失败了,记录一下,我们待会儿再下载
(6)engine把response交给spider处理,spider会处理response,从中分析提取数据
(7) 首先spider提取需要的数据放入item中发送给engine;并且将后面还有要获取数据的url发送给engine作为一个新的request,发送给engine
(8)item数据发送给Pipeline处理,request继续进入scheduler,重复第二步操作
如果scheduler中还有request,程序就不会停止
首先我们需要安装scrapy框架,终端输入命令:
#安装scrapy框架
pip install scrapy
#安装完scrapy后我们查看一下scrapy的命令有哪些
scrapy
首先用到startproject命令,可以直接创建一个scrapy的项目
scrapy startproject ScrapyDemo
然后在你当前目录下就会生成刚才创建的项目

创建好项目后会有这么一段提示:

所以我们直接进入刚才的目录下,创建我们第一个爬虫程序
#进入刚才创建的目录下
cd ScrapyDemo
#快速生成一个爬虫程序
scrapy genspider genspider example example.com
查看生成的爬虫程序 Scrapy.Demo/SpiderDemo/spiders/example.py
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['example.com']
start_urls = ['http://example.com/']
def parse(self, response):
pass
我们仿照他写一个爬虫程序,BaiDuSpider,查看百度的页面信息
import scrapy
class BaiDuSpider(scrapy.Spider):
# 爬虫的名称,用于启动爬虫
name='BaiDuSpider'
# 设置爬虫允许爬取的域名
allowed_domains=["baidu.com"]
# 启动的url
start_urls=["http://www.baidu.com"]
#response默认的解析函数
def parse(self,response):
print(response.text)
终端启动爬虫命令:
scrapy crawl BaiDuSpider
成功获取到了数据
Original: https://blog.csdn.net/zzds111/article/details/121996462
Author: 今天该取什么名字好
Title: Scrapy爬虫框架
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/788820/
转载文章受原作者版权保护。转载请注明原作者出处!