

目录
2.选择:从Series和DataFrame实例中选择部分数据
2.2 Series属性:iloc,loc(按”行”来索引)
6.2 Pandas也支持类似于数据库查询语句GROUP BY,可完成分组按照某列
7.3 pandas可生成日期范围通过方法.date_range函数
8.1 DataFrame对象导出指定的CSV文件:to_csv()
8.2 从CSV文件读取DataFrame对象:read_csv()
8.3 DataFrame导出到xlsx文件:to_excel()
8.4 DataFrame导出到txt文件:to_csv()
- Pandas的基本概念
Pandas:
数据分析,在Numpy基础上增加了高级功能:数据自动对齐,时间序列支持、缺失数据灵活处理等等
Series、DataFrame核心数据结构,大部分Pandas功能都围绕这两种数据结构进行。
Series是一个值的序列,可以理解成一维数组,有一个列和一个索引,索引可以定制
1.1 Series方法:
import pandas as pd
s1 = pd.Series([1,2,3,4,5])
print(s1)
"""
D:\Anaconda3\python.exe D:/Python_file_forAnconda3_python/数据分析/自定义学习/Pandas01.py
0 1
1 2
2 3
3 4
4 5
dtype: int64
Process finished with exit code 0
"""
import pandas as pd
s2 = pd.Series([1,2,3,4,5],index=['a','b','c','d','e'])
print(s2)
"""
D:\Anaconda3\python.exe D:/Python_file_forAnconda3_python/数据分析/自定义学习/Pandas01.py
a 1
b 2
c 3
d 4
e 5
dtype: int64
"""
1.2 DataFrame类似于二维数组,有行列之分
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(4,4),index=['a','b','c','d'],columns=['A','B','C','D'])
print(df)
"""
D:\Anaconda3\python.exe D:/Python_file_forAnconda3_python/数据分析/自定义学习/Pandas01.py
A B C D
a 0.341299 -1.501784 1.069910 0.879989
b 0.416756 1.066293 0.569988 2.745966
c 0.711972 -0.336308 -0.006444 1.322002
d 2.217314 -0.281477 -0.706486 0.117150
Process finished with exit code 0
"""
通过指定索引-index和标签-columns创建DataFrame对象,可以通过df.index和df.columns访问索引和标签:
df.index
Out[12]: Index(['a', 'b', 'c', 'd'], dtype='object')
df.columns
Out[13]: Index(['A', 'B', 'C', 'D'], dtype='object')
2.选择:从Series和DataFrame实例中选择部分数据
2.1 Series:索引或索引位置
import pandas as pd
import numpy as np
s2 = pd.Series([1,2,3,4,5],index=['a','b','c','d','e'])
print(s2[0])
print('_______')
print(s2[0:3])
print(s2['a'])
print("________")
print(s2['a':'c'])
"""
D:\Anaconda3\python.exe D:/Python_file_forAnconda3_python/数据分析/自定义学习/Pandas01.py
1
_______
a 1
b 2
c 3
dtype: int64
1
________
a 1
b 2
c 3
dtype: int64
Process finished with exit code 0
"""
2.2 Series属性:iloc,loc(按”行”来索引)
import pandas as pd
import numpy as np
s2 = pd.Series([1,2,3,4,5],index=['a','b','c','d','e'])
print(s2.iloc[0:3]) #按照默认索引访问
print("--------------")
print(s2.loc['a':'c']) #按照自定义的index访问
"""
D:\Anaconda3\python.exe D:/Python_file_forAnconda3_python/数据分析/自定义学习/Pandas01.py
a 1
b 2
c 3
dtype: int64
a -0.931263
b -0.648751
c 0.438436
d -1.481929
Name: A, dtype: float64
"""
3.2 读取多行多列:loc方法
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(4,4),index=['a','b','c','d'],columns=['A','B','C','D'])
print(df)
print("-----")
print(df.loc[:,['B','C','D']]) # 标签取值-多行多列 (以默认的方式)
"""
D:\Anaconda3\python.exe D:/Python_file_forAnconda3_python/数据分析/自定义学习/Pandas01.py
A B C D
a -1.205197 -0.375471 0.115681 0.111243
b -0.329662 0.001292 -0.540496 -1.274938
c -0.285998 0.122846 -0.738836 0.213211
d -1.479184 0.251340 0.322654 -0.745249
-0.23413573419505523
A B C E
a 0.0 1.0 2.0 NaN
b 3.0 5.0 7.0 3.0
c 10.0 12.0 14.0 7.0
d 8.0 9.0 10.0 11.0
'''
- 运算统计
统计:
类似Numpy,Series与DataFrame也可以使用各种统计方法:平均值、方差、求和等等,可通过descirbe方法可以获取常见统计信息
A B C
count 3.0 3.0 3.0 元素值得数量
mean 3.0 4.0 5.0 平均数
std 3.0 3.0 3.0 标准差
min 0.0 1.0 2.0 最小值
25% 1.5 2.5 3.5 取值百分比
50% 3.0 4.0 5.0 取值百分比
75% 4.5 5.5 6.5 取值百分比
max 6.0 7.0 8.0 最大值
6.数据合并与分组
6.1 合并两个DataFrame两种方法:
6.1.1 简单拼接—-concat
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.random.randn(3,3))
df2 = pd.DataFrame(np.random.randn(3,3),index=[5,6,7])
print(pd.concat([df1,df2]))
"""
D:\Anaconda3\python.exe D:/Python_file_forAnconda3_python/数据分析/自定义学习/Pandas01.py
0 1 2
0 1.236067 0.751290 0.358762
1 -1.605407 -1.296070 -0.167892
2 1.403888 1.962560 0.766084
5 -1.118603 0.845264 -0.890752
6 -1.209584 0.006337 0.310854
7 2.104464 -0.157647 -1.805883
Process finished with exit code 0
"""
6.1.2 根据列名查询逐一合并—merge
df1 = pd.DataFrame({'user_id':[5248,13],'course':[12,45],'minutes':[9,36]})
df2 = pd.DataFrame({'course':[12,5], 'name':['Numpy','Pandas']})
print(pd.merge([df1,df2]))
6.2 Pandas也支持类似于数据库查询语句GROUP BY,可完成分组按照某列
import pandas as pd
df1 = pd.DataFrame({'user_id':[5248,13,5348],'course':[12,45,23],'minutes':[9,36,45]})
a = df1[['user_id','minutes']].groupby('user_id').sum() #通过'user_id'和'minutes'来进行分组,并按'user_id'排列
print(a)
"""
D:\Anaconda3\python.exe D:/Python_file_forAnconda3_python/数据分析/自定义学习/Pandas01.py
minutes
user_id
13 36
5248 9
5348 45
Process finished with exit code 0
"""
- 时间序列处理
datetime属性对象:
.datetime 代表时间对象
.date 代表某一天
.timedelta 代表时间差
7.1 时间差的运算
from datetime import datetime, timedelta
d1 = datetime(2020,3,15)
delta = timedelta(days=10) #时间为10天
print(d1+delta)
"""
D:\Anaconda3\python.exe D:/Python_file_forAnconda3_python/数据分析/自定义学习/Pandas01.py
2020-03-25 00:00:00
"""
7.2 pandas与datetime
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
dates = [datetime(2020,3,15),datetime(2020,3,16),datetime(2020,3,17),datetime(2020,3,18)]
ts = pd.Series(np.random.randn(4),index=dates) # 数组ts的索引index定义为dates的值
print(ts)
print('------')
print(dates)
print('------')
print(ts.index[0])
"""
D:\Anaconda3\python.exe D:/Python_file_forAnconda3_python/数据分析/自定义学习/Pandas01.py
2020-03-15 -0.185834
2020-03-16 -2.075404
2020-03-17 -1.093103
2020-03-18 0.171173
dtype: float64
2020-03-15 00:00:00
"""
pandas取索引对应的值:
ts[ts.index[0]] # ts.index[0] 表示的是索引值
ts['2020/3/15']
ts['3/15/2020']
ts[datetime(2020,3,15)]
7.3 pandas可生成日期范围通过方法.date_range函数
pandas可生成日期范围通过方法.date_range函数
该函数可传参:
start: 指定日期范围起始时间
end: 指定日期范围截止时间
preiods: 指定日期范围间隔时间
freq: 指定日期频率:D-每天,H-每小时,M-每月
5D - 5天
MS- 每个月第一天
BM- 每个月最后一个工作日
1h30min 1小时30分钟
pd.date_range('2020-1-1','2021',freq='MS')
8.读写数据
8.1 DataFrame对象导出指定的CSV文件:to_csv()
其中:index是否要索引,header是否要列名,True就是需要。
import pandas as pd
F = pd.DataFrame(np.array([[100,200,300],[20,10,15]]))
F.to_csv(r".\t1.csv") # 默认逗号分割
F.to_csv(r".\t2.csv",sep=' ') # 用一个空格分割
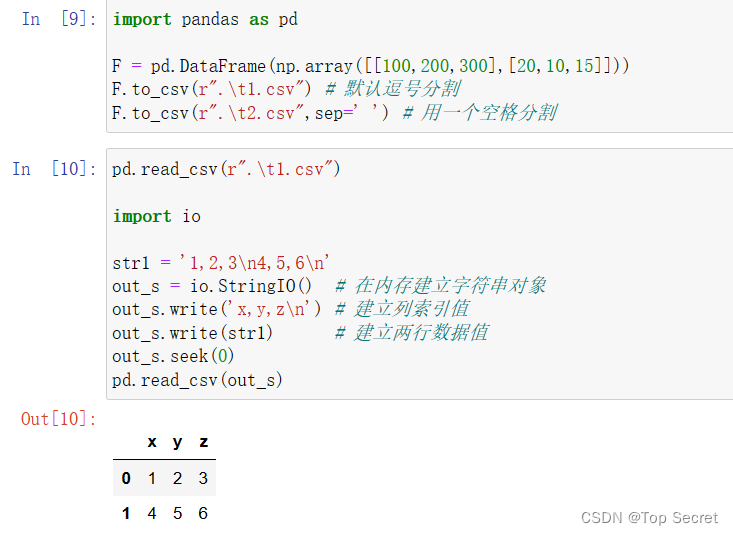
8.2 从CSV文件读取DataFrame对象:read_csv()
pd.read_csv(r".\t1.csv")
import io
str1 = '1,2,3\n4,5,6\n'
out_s = io.StringIO() # 在内存建立字符串对象
out_s.write('x,y,z\n') # 建立列索引值
out_s.write(str1) # 建立两行数据值
out_s.seek(0)
pd.read_csv(out_s)

8.3 DataFrame导出到xlsx文件:to_excel()
outputpath='d:/Users/chen_lib/Desktop/fenci.xlsx'
df.to_excel(outputpath,sep='\t',index=False,header=False)
8.4 DataFrame导出到txt文件:to_csv()
这个和导出到csv的唯一区别,就是分隔符了,txt文件是\t作为分隔符的,csv是用,作为分隔符。
df.to_csv('d:/Users/chen_lib/Desktop/fenci_result.txt',sep='\t',index=False)
8.5 Pickling格式导入导出
(1) 对象写入pickle文件:函数 pd.to_pickle(obj,path,compression=’infer’,protocol=4)
import pandas as pd
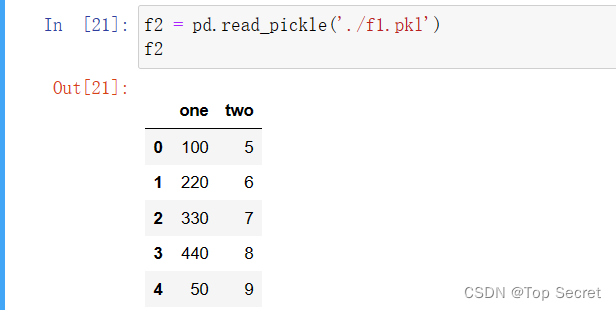
data1 = pd.DataFrame({"one":[100,220,330,440,50],"two":range(5,10)})
pd.to_pickle(data1,r'./f1.pkl')
(2) 从pickle文件读取对象:pd.read_pickle(path,compression=’infer’) # compression指定压缩方式。
8.6 HDF5格式导入导出
HDF5是分层数据管理结构,集中存储管理不同类型的图像,数值数据等内容的一种文件格式。
(1)从DataFrame写入HDF5:to_hdf(path,key,**kwargs)
import pandas as pd
data2 = pd.DataFrame({'Tom':[100,88,99],'Jack':[99,100,98],'Alice':[92,100,100]})
data2.to_hdf('./F1.h5',key='f1')
(2) 读取:read_hdf()
Original: https://blog.csdn.net/m0_55196097/article/details/125455085
Author: Top Secret
Title: python数据分析03—Pandas
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/754236/
转载文章受原作者版权保护。转载请注明原作者出处!