

聚类的评价指标
对于聚类结果的评价方法一般可以分为内部评估法(internal evaluation)与外部评估方法(external evaluation)。
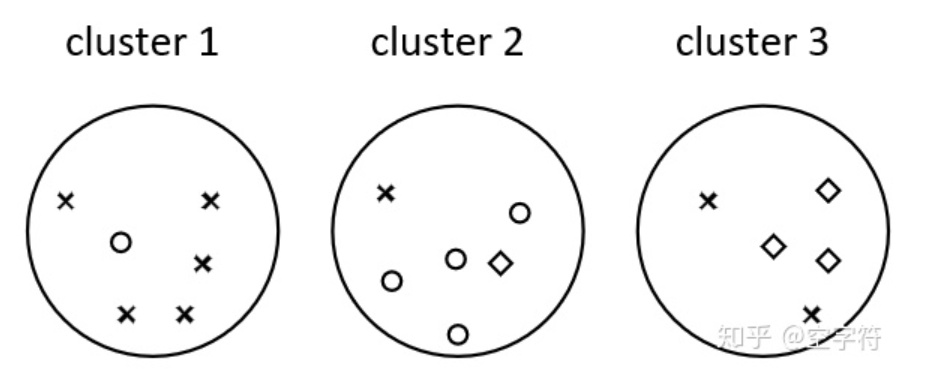

外部评估方法是指在知道真实标签(ground truth )的情况下来评估聚类结果的好坏, 例如纯度( Purity)、兰德系数(Rand Index, RI)、F值(F-score)和调整兰德系数(Adjusted Rand Index,ARI)。一般来说在做论文,或者是有少量的标注数据时,都可以用外部评估法选择一个相对最优的聚类模型,然后再应用到其它未被标记的数据中。
- 纯度:用聚类正确的样本数除以总的样本数。
- 兰德系数(Rand Index, RI)和 F值(F-score):
TP:表示两个同类样本点在同一个簇(布袋)中的情况数量;
FP:表示两个非同类样本点在同一个簇中的情况数量;
TN:表示两个非同类样本点分别在两个簇中的情况数量;
FN:表示两个同类样本点分别在两个簇中的情况数量;
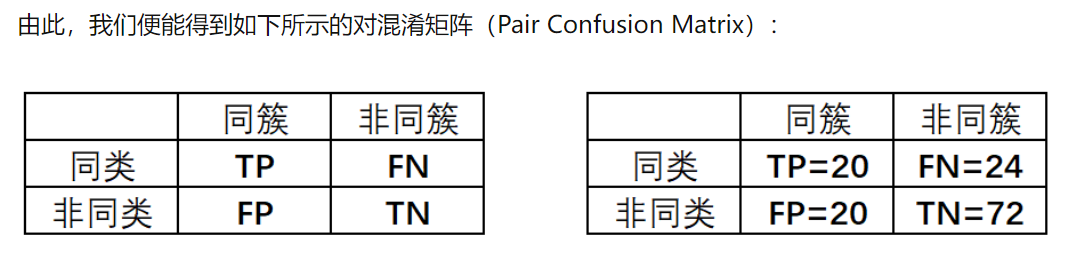
TP=20的含义就是在所有簇中,任一簇中任取两个样本均是同一类别的情况总数;
则表示在所有簇中,任两簇中各取一个样本均不是同一类别的情况总数。

在这里RI和
的取值范围均为,越大表示聚类效果越好。
- *调整兰德系数
调整兰德系数是兰德系数的一个改进版本,目的是为了去掉随机标签对于兰德系数评估结果的影响。(随机将每个样本都划到一个簇中(也就是17个簇))
根据聚类得到的结果和真实标签我们便能得到如下所示的列联表( contingency table):


内部评估法是不借助于外部信息,仅仅只是根据聚类结果来进行评估, 常见的有轮廓系数( Silhouette Coefficient)、Calinski-Harabasz Index等,这些sklearn中也都有实现可以直接调用。一般来说,在完全没有标记数据的情况下可以通过这种方式来评估聚类结果的好坏。
轮廓系数(Silhouette Coefficient)聚类性能评估-轮廓系数 – 知乎
是聚类效果好坏的一种评价方式。轮廓系数取值范围为[-1,1],取值越接近1则说明聚类性能越好,相反,取值越接近-1则说明聚类性能越差。
- a:某个样本与其所在簇内其他样本的平均距离
- b:某个样本与其他簇样本的平均距离
针对某个样本的轮廓系数s为:
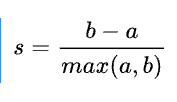
聚类总的轮廓系数SC为:
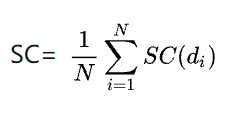
轮廓系数的优点
- 轮廓系数为-1时表示聚类结果不好,为+1时表示簇内实例之间紧凑,为0时表示有簇重叠。
- 轮廓系数越大,表示簇内实例之间紧凑,簇间距离大,这正是聚类的标准概念。
轮廓系数的缺点
- 对于簇结构为凸的数据轮廓系数值高,而对于簇结构非凸需要使用DBSCAN进行聚类的数据,轮廓系数值低,因此,轮廓系数不应该用来评估不同聚类算法之间的优劣,比如Kmeans聚类结果与DBSCAN聚类结果之间的比较。
根据折线图可直观的找到系数变化幅度最大的点,认为发生畸变幅度最大的点就是最好的聚类数目。
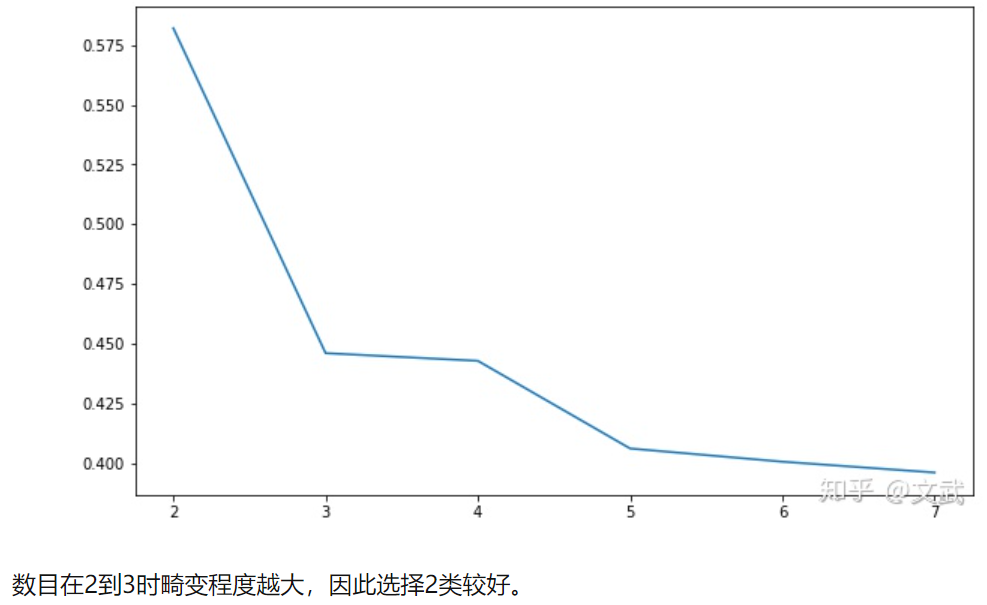
Calinski-Harabaz 指数 聚类模型评价(python) – 知乎
Calinski-Harabaz指数也可以用来选择最佳聚类数目,且运算速度远高于轮廓系数。当内部数据的协方差越小,类别之间的协方差越大,Calinski-Harabasz分数越高。
Original: https://blog.csdn.net/weixin_39915444/article/details/120979705
Author: 儒雅的晴天
Title: 聚类的评价指标
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/785436/
转载文章受原作者版权保护。转载请注明原作者出处!