

1. 引言
在数据处理和机器学习领域,我们经常需要处理各种数据。本文重点介绍了三种非常简单的方法来检测数据集中的离群点。别说闲话了,我们开始吧。
[En]
In the fields of data processing and machine learning, we often need to deal with all kinds of data. This paper focuses on three very simple methods to detect outliers in the data set. Cut the gossip and let’s get started.
2. 举个栗子
为了便于介绍,下面给出我们的测试数据集:
[En]
To facilitate the introduction, our test data set is given here, as follows:
data = pd.DataFrame([ [87, 82, 85], [81, 89, 75], [86, 87, 69], [91, 79, 86], [88, 89, 82], [0, 0, 0], # this guy missed the exam [100, 100, 100],], columns=["math", "science", "english"])
图示如下:
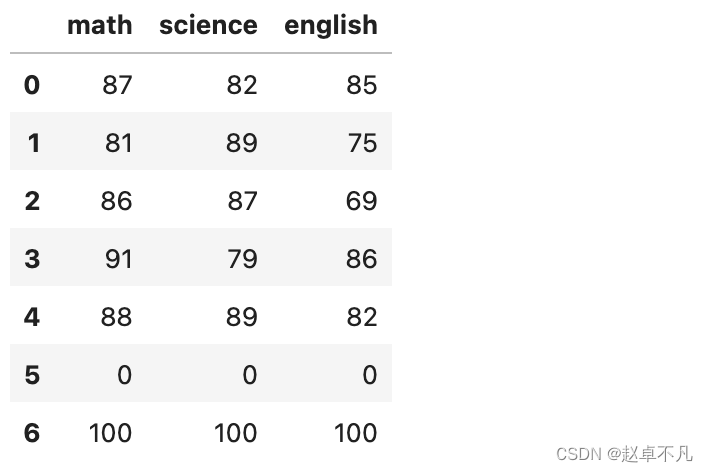

假设我们有一堆学生在三门学科–英语、数学和科学–的考试成绩。这些学生通常成绩很好,但其中一人错过了所有的考试,三门课都得了0分。我们的分析中包括,这个人可能会把事情搞砸,所以我们需要把他作为一个异类来对待。
[En]
Suppose we have a bunch of students’ test scores in three subjects-English, math and science. These students usually do well, but one of them missed all the exams and got 0 in all three subjects. It is included in our analysis that this guy may screw things up, so we need to treat him as an anomaly.
3. 孤立森林
用隔离森林算法解决上述孤立点分析非常简单,代码如下:
[En]
Using the isolated forest algorithm to solve the above outlier analysis is very simple, the code is as follows:
from sklearn.ensemble import IsolationForestpredictions = IsolationForest().fit(data).predict(data)# predictions = array([ 1, 1, 1, 1, 1, -1, -1])
这里,对每一行预测预测值,预测结果为1或-1;其中1表示该行不是离群值,-1表示该行是离群值。在上面的示例中,我们的隔离森林算法将最后两行数据预测为异常值。
[En]
Here, the predicted value is predicted for each row, and the predicted result is 1 or-1; where 1 indicates that the row is not an outlier, and-1 indicates that the row is an outlier. In the above example, our isolated forest algorithm predicts the last two rows of data as outliers.
4. 椭圆模型拟合
用孤子椭圆模型拟合算法解决上述异常值也很方便,代码如下:
[En]
It is also very convenient to use the solitary ellipse model fitting algorithm to solve the above abnormal values, the code is as follows:
from sklearn.covariance import EllipticEnvelopepredictions = EllipticEnvelope().fit(data).predict(data)# predictions = array([ 1, 1, 1, 1, 1, -1, 1])
在上面的代码中,我们使用了另一种孤立点检测算法来取代隔离森林算法,但代码保持不变。同样,在预测值中,1代表非异常值,-1代表异常值。在上述情况下,我们的椭圆模型拟合算法只将倒数第二个学生作为异常值,即所有得分为零的考生。
[En]
In the above code, we use another outlier detection algorithm to replace the isolated forest algorithm, but the code remains the same. Similarly, in the predicted value, 1 represents a non-outlier and-1 represents an outlier. In the above cases, our ellipse model fitting algorithm only takes the penultimate student as the outlier, that is, all candidates whose scores are zero.
5. 局部异常因子算法
同样,我们可以很容易地使用局部异常因子算法来分析上述数据。示例代码如下:
[En]
Similarly, we can easily use the local exception factor algorithm to analyze the above data. The sample code is as follows:
from sklearn.neighbors import LocalOutlierFactorpredictions = LocalOutlierFactor(n_neighbors=5, novelty=True).fit(data).predict(data)# array([ 1, 1, 1, 1, 1, -1, 1])
局部异常因子算法是sklearn上可用的另一种异常检测算法,我们可以简单地在这里随插随用。同样地,这里该算法仅将最后第二个数据行预测为异常值。
6. 挑选异常值检测方法
那么,我们如何决定哪种异常检测算法更好呢?简而言之,没有“最好的”离群点检测算法–我们可以把它们看作是做同一件事的不同方法(得到的结果略有不同)。
[En]
So how do we decide which anomaly detection algorithm is better? In short, there are no “best” outlier detection algorithms-we can think of them as different ways to do the same thing (and get slightly different results)
7. 异常值消除
在我们从上述三种异常检测算法中的任何一种获得异常预测之后,我们现在可以执行离群点删除。这里,我们只需要保留异常预测为1的所有数据行,如下所示:
[En]
After we have obtained the anomaly prediction from any of the above three anomaly detection algorithms, we can now perform the deletion of outliers. Here, we only need to keep all the data rows whose exception prediction is 1, as follows:
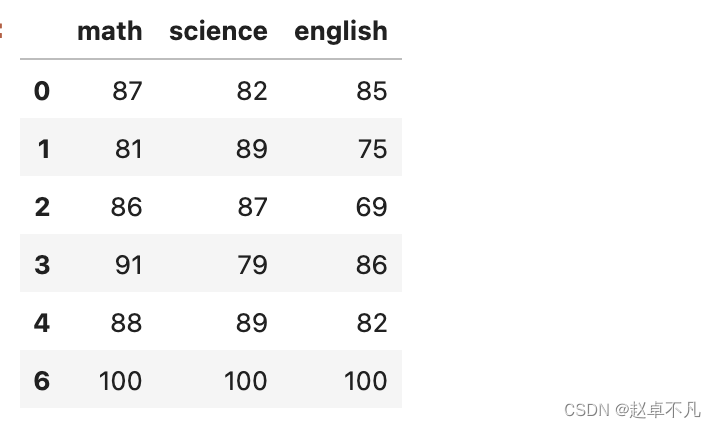
predictions = array([ 1, 1, 1, 1, 1, -1, 1])data2 = data[predictions==1]
结果如下:
8. 总结
本文重点介绍了在Python中使用sklearn机器学习库来进行异常值检测的三种方法,并给出了相应的代码示例。
您学废了嘛?

Original: https://blog.51cto.com/u_15506603/5512727
Author: sgzqc
Title: 在Python中寻找数据异常值的三种方法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/504880/
转载文章受原作者版权保护。转载请注明原作者出处!