

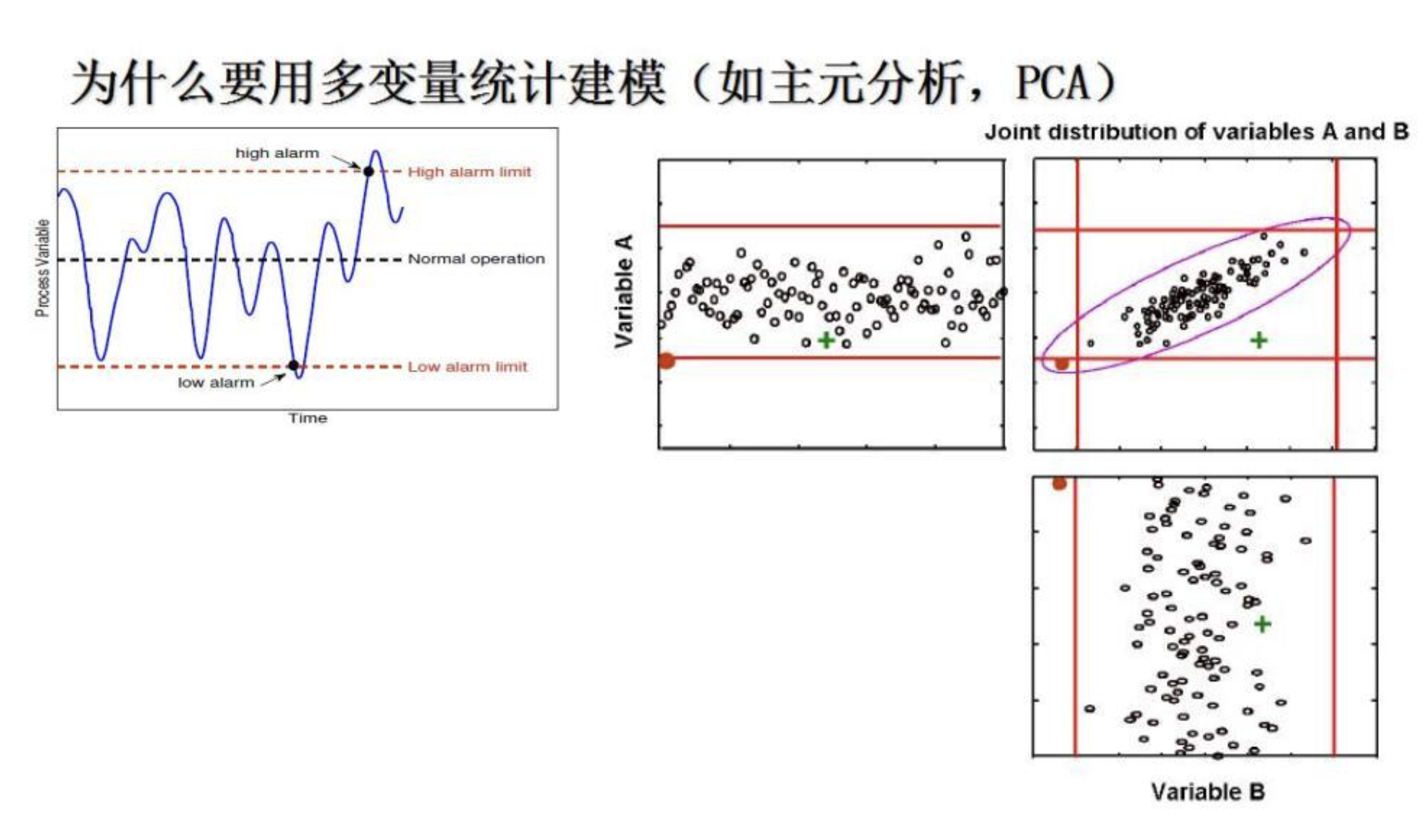
PCA降维
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。


; T2的计算

基本原理见 这里。
故障判断
如系统正常运行,则样本的T2值应该满足T2 < Tα ,反之,可认为出现故障。
SPE(Q统计量)的计算

基本原理见 这里。
; 故障判断
如系统正常运行,则样本的SPE值应该满足SPE < Qα ,反之,可认为出现故障。
Python程序如下
下面是封装成function的块
可直接调用
传入你需要训练的数据集即可
注意数据集最好为 .xls 后缀
def PCA_x(train_file_name, test_file_name, num_name):
train_data = pd.read_excel(train_file_name, sheet_name=num_name) # 导入训练数据
test_data = pd.read_excel(test_file_name, sheet_name=num_name) # 导入测试数据
# *****************使用pandas方法读取样本数据功能模块(结束)*********************
m = train_data.shape[1]; # 获取数据表格的列数
n = train_data.shape[0]; # 获取数据表格的行数
# ******************数据标准化处理(开始)*********************
S_mean = np.mean(train_data, axis=0) # 健康数据矩阵的列均值
S_mean = np.array(S_mean) # 健康数据的列均值,narry数据类型
S_var = np.std(train_data, ddof=1); # 健康数据矩阵的列方差,默认ddof=0表示对正态分布变量的方差的最大似然估计,ddof=1提供了对无限总体样本的方差的无偏估计(与Matlab一致)
S_var[S_var == 0.0] = 0.0000000000000001 # 将集合S_var中的0替换为0.0000000000000001
S_var = np.array(S_var) # 健康数据的列方差,narry数据类型
train_data -= S_mean # 求取矩阵X的均值
train_data /= S_var # 求取矩阵X的方差
train_data = np.where(train_data < 4.0e+11, train_data, 0.0) # 把标准化后的矩阵X中的0替换为0.0000000000000001
X_new = train_data; # 求得标准化处理后的矩阵X_new
# ******************求矩阵Y的协方差矩阵Z*********************
X_new = np.transpose(X_new); # 对矩阵进行转秩操作
Z = np.dot(X_new, train_data / (n - 1)) # 求取协方差矩阵Z
# ******************计算协方差矩阵Z的特征值和特征向量*********************
a, b = np.linalg.eig(Z) ##特征值赋值给a,对应特征向量赋值给b
lambda1 = sorted(a, reverse=True) # 特征值从大到小排序
lambda_i = [round(i, 3) for i in lambda1] # 保留三位小数
print('lambda特征值由大到小排列:', lambda_i)
# 计算方差百分比
sum_given = 0 # 设置初值为0
sum_given = sum(lambda_i)
variance_hud = [] # 设置存放方差百分比的矩阵
for i in tqdm(range(m)):
if i m:
variance_hud.append(lambda_i[i] / sum_given)
else:
break
variance_hud = [round(i, 3) for i in variance_hud] # 保留三位小数
print('方差百分比从大到小排序:', variance_hud)
# 累计贡献率
leiji_1 = []
new_value = 0
for i in tqdm(range(0, m)):
if i m:
new_value = new_value + variance_hud[i]
leiji_1.append(new_value)
else:
break
print('累计贡献率:', leiji_1)
# ******************主元个数选取 *********************
totalvar = 0 # 累计贡献率,初值0
for i in tqdm(range(m)):
totalvar = totalvar + lambda1[i] / sum(a) # 累计贡献率,初值0
if totalvar >= 0.85:
k = i + 1 # 确定主元个数
break # 跳出for循环
PCnum = k # 选取的主元个数
PC = np.eye(m, k) # 定义一个矩阵,用于存放选取主元的特征向量
for j in tqdm(range(k)):
wt = a.tolist().index(lambda1[j]) # 查找排序完成的第j个特征值在没排序特征值里的位置。
PC[:, j:j + 1] = b[:, wt:wt + 1] # 提取的特征值对应的特征向量
print('成分矩阵:', PC)
print('贡献率85%以上的主元个数为:', k)
df_cfjz = pd.DataFrame(PC)
# ******************根据建模数据求取 T2 阈值限 *********************
# ******************置信度 = (1-a)% =(1-0.05)%=95% *************
F = f.ppf(1 - 0.05, k, n - 1) # F分布临界值
T2 = k * (n - 1) * F / (n - k) # T2求取
# ****************** 健康数据的 SPE 阈值限求解 *********************
ST1 = 0 # 对应SPE公式中的角1初值
ST2 = 0 # 对应SPE公式中的角2初值
ST3 = 0 # 对应SPE公式中的角3初值
for i in range(k - 1, m):
ST1 = ST1 + lambda1[i] # 对应SPE公式中的角1
ST2 = ST2 + lambda1[i] * lambda1[i] # 对应SPE公式中的角2
ST3 = ST3 + lambda1[i] * lambda1[i] * lambda1[i] # 对应SPE公式中的角3
h0 = 1 - 2 * ST1 * ST3 / (3 * pow(ST2, 2))
Ca = 1.6449
SPE = ST1 * pow(Ca * pow(2 * ST2 * pow(h0, 2), 0.5) / ST1 + 1 + ST2 * h0 * (h0 - 1) / pow(ST1, 2),
1 / h0) # 健康数据SPE计算
# ******************测试样本数据*********************
m1 = test_data.shape[1]; # 获取数据表格的列数
n1 = test_data.shape[0]; # 获取数据表格的行数
test_data = np.array(test_data) # 将DataFrame数据烈性转化为ndarray类型,使得数据矩阵与Matlab操作一样。
I = np.eye(m) # 产生m*m的单位矩阵
PC1 = np.transpose(PC) # PC的转秩
SPEa = np.arange(n1).reshape(1, n1) # 定义测试数据的SPE矩阵,为正数矩阵
SPEa = np.double(SPEa) # 将正数矩阵,转化为双精度数据矩阵
TT2a = np.arange(n1).reshape(1, n1) # 定义测试数据的T2矩阵,为正数矩阵
TT2a = np.double(TT2a) # 将正数矩阵,转化为双精度数据矩阵
DL = np.diag(lambda1[0:k]) # 特征值组成的对角矩阵
DLi = np.linalg.inv(DL) # 特征值组成的对角矩阵的逆矩阵
# ******************绘制结果 *********************
# mpl.rcParams['font.sans-serif'] = ['SimHei'] # 在图形中显示汉字
for i in range(n1):
xnew = (test_data[i, :] - S_mean) / S_var; # 对应 Matlab程序:xnew=(Data2(i,1:m)-S_mean)./S_var;
# 以下是实现Matlb程序: err(1,i)=xnew*(eye(14)-PC*PC')*xnew';
xnew1 = np.transpose(xnew) # xnew的转秩
PC1 = np.transpose(PC) # PC的转秩
XPC = np.dot(xnew, PC) # 矩阵xnew与PC相乘
XPCPC1 = np.dot(XPC, PC1) # 矩阵XPC与PC1相乘
XXPCPC1 = xnew - XPCPC1 # 矩阵xnew减去XPCPC1
SPEa[0, i] = np.dot(XXPCPC1, XXPCPC1) # 矩阵XXPCPC1与XXPCPC1相乘
XPi = np.dot(XPC, DLi) # 矩阵XPC与DLi相乘
XPiP = np.dot(XPi, PC1) # 矩阵XPi与PC1相乘
TT2a[0, i] = np.dot(XPiP, xnew1) # 矩阵XPiP与xnew1相乘
Sampling = r_[0.:n1] # 产生的序列值式0到n1
SPE1 = SPE * ones((1, n1)) # 产生SPE数值相同的矩阵
print('spe统计量的值:', SPEa)
# df_spe = pd.DataFrame(SPEa.T)
new_SPE = SPEa.T
# df_spe.to_csv('SPE值.csv') # 将SPE值保存成.csv
T21 = T2 * ones((1, n1)) # 产生T2数值相同的矩阵
print('t2统计量的值:', TT2a)
# df_T2 = pd.DataFrame(TT2a.T)
new_TT = TT2a.T
# df_T2.to_csv('T2值.csv') # 将T2值保存成.csv
return new_SPE, new_TT, Sampling, TT2a, T21, SPEa, SPE1, n1, T2, SPE, m, variance_hud, leiji_1, df_cfjz
上面程序会把T2和SPE的值保存在后台,且每次有超过阈值会打标签,以 label 保存结果在后台。
返回值有好几个,可用作其他用处,各取所需。
下面给出T2和SPE制图Python程序:
可视化T2和SPE
def graph_TT_SPE(Sampling, TT2a, T21, SPEa, SPE1, n1, T2, SPE, layer):
figure(1) # 画的第一张图
plot(Sampling, TT2a[0, :], '*-', Sampling, T21[0, :], 'r-') # 绘制出测试数据SPEa的数据集合,和健康数据训练得到的SPE阈值限
xlabel('sample points') # 给X轴加标注
ylabel('T^2') # 给Y轴加标注
legend(['T^2 value', 'T^2 limit']) # 为绘制出的图形线条添加标签注明
title("T^2 statistic" + layer) # 绘制的图形主题为"SPE统计量"
figure(2)
plot(Sampling, SPEa[0, :], '*-', Sampling, SPE1[0, :], 'r-') # 绘制出测试数据TT2a的数据集合,和健康数据训练得到的T2阈值限
xlabel('sample points') # 给X轴加标注
ylabel('SPE') # 给Y轴加标注
legend(['SPE value', 'SPE limit']) # 为绘制出的图形线条添加标签注明
title("SPE statistic" + layer) # 绘制的图形主题为"SPE统计量"
show() # 显示绘制的图形
# 循环对象TT2a,SPEa,循环基线T2,SPE
sum1 = 0
for ij in range(n1): # 对测试样本个数进行循环
if ((TT2a[0, ij] T2) & (SPEa[0, ij] SPE)): # 判断各个值是否小于阈值线
TT2a[0, ij] = 0 # 将小于阈值线的样本点位置上的数置为0
SPEa[0, ij] = 0 # 将小于阈值线的样本点位置上的数置为0
else:
TT2a[0, ij] = 1 # 将小于阈值线的样本点位置上的数置为1
SPEa[0, ij] = 1 # 将小于阈值线的样本点位置上的数置为1
sum1 += 1
# print(i)#输出有故障的样本点
print(sum1)
d1 = pd.DataFrame(TT2a.T)
d1['label'] = d1[0]
d1.drop(0, axis=1, inplace=True)
d1.to_csv('label.csv', index=False)
print(d1.sum())
print(SPEa)
上面 layer 是我为了主程序循环,每次出图能够传入不同层的数据,可自行修改。
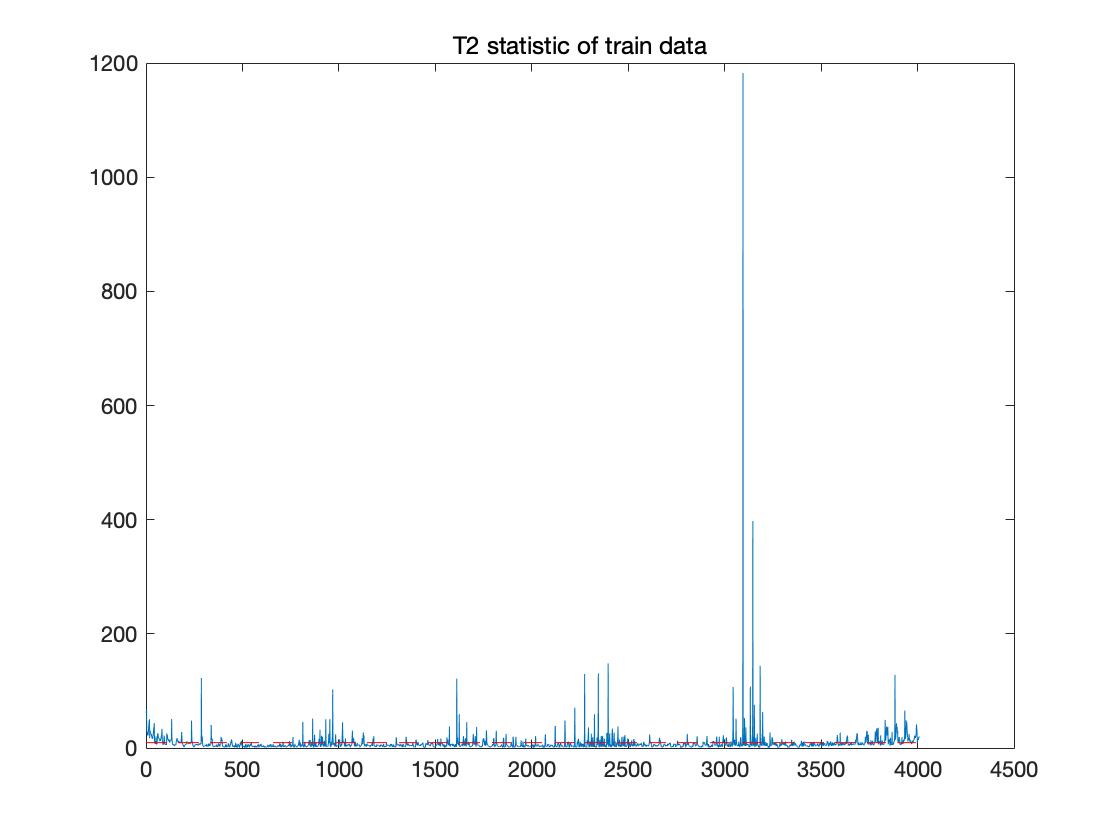
运行效果如下:
T2结果
SPE结果
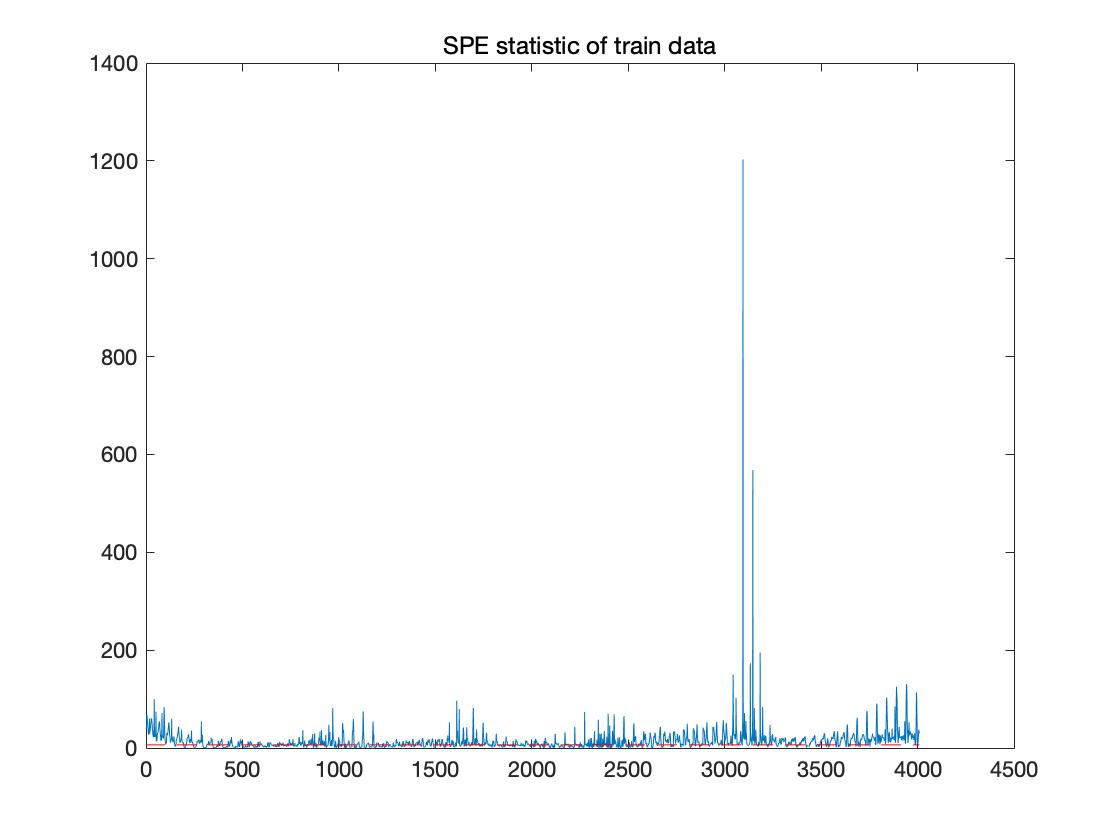
在第二部分制图, 样式、颜色、图例、坐标等均可自行 Matplot进行修改。
完整程序( 功能很多、 分量很大):
主成分分析PCA降为及故障诊断T2和SPE统计量出图Python.py
另外还有个 MATLAB的 PCA程序:
比心♥️~
“
这个世界
有人不了解海
不知爱海
也有人了解海
不敢爱海
“
Reference:
(1):主成分分析(PCA)原理详解
https://blog.csdn.net/program_developer/article/details/80632779
(2):主成分分析(PCA)原理与故障诊断(SPE、T^2以及结合二者的综合指标)-MATLAB实现
https://blog.csdn.net/u013829973/article/details/77981701
(3):基于PCA的线性监督分类的故障诊断方法-T2与SPE统计量的计算
https://blog.csdn.net/And_ZJ/article/details/90576240
(4):3多变量统计故障诊断方法
https://wenku.baidu.com/view/b9ef2df9dd3383c4bb4cd2e0.html
(5):PCA故障诊断步骤
https://wenku.baidu.com/view/f8b6c51c08a1284ac9504339.html
Original: https://blog.csdn.net/weixin_44333889/article/details/118410189
Author: 府学路18号车神
Title: Python代码实现-主成分分析(PCA)降维及故障诊断中的T2和SPE统计量Matplotlib出图|Python技能树征题
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/767138/
转载文章受原作者版权保护。转载请注明原作者出处!