

一、爬虫部分
爬虫说明:
1、本爬虫是以面向对象的方式进行代码架构的
2、本爬虫是通过将前程无忧网页转换成移动端来进行求职信息爬取的
3、本爬虫爬取的数据存入到MongoDB数据库中
4、爬虫代码中有详细注释
代码展示
import time
from pymongo import MongoClient
import requests
from lxml import html
class JobSpider():
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1"
}
self.start_url = 'https://msearch.51job.com/job_list.php?keyword=python&jobarea=000000&pageno=1'
self.url_list = 'https://msearch.51job.com/job_list.php?keyword=python&jobarea=000000&pageno={}'
self.client = MongoClient()
self.collection = self.client['test']['wuyou_job']
def get_url_list(self,total_num):
total_num = int(total_num)
page = total_num//50+1 if total_num%50!=0 else total_num//50
return [self.url_list.format(i) for i in range(1,page+1)]
def parse_url(self,url):
time.sleep(0.5)
rest = requests.get(url,headers=self.headers)
return rest.content.decode()
def get_content_list(self,str_html):
str_html = html.etree.HTML(str_html)
job_list = str_html.xpath('//div[@id="pageContent"]/div[@class="list"]/a')
for i in job_list:
detail_url = i.xpath('./@href')[0]
self.parse_detail(detail_url)
def parse_detail(self,detail_url):
time.sleep(0.1)
rest = requests.get(detail_url,headers = self.headers)
str_html = html.etree.HTML(rest.content.decode())
item = {}
item['职位'] = str_html.xpath('//p[@class="jname"]/text()')
item['职位'] = item['职位'][0] if len(item['职位'])>0 else None
item['公司名称'] = str_html.xpath('//div[@class="info"]/h3/text()')
item['公司名称'] = item['公司名称'][0] if len(item['公司名称'])>0 else None
item['公司地点'] = str_html.xpath('//div[@class="jbox"]/div[@class="m_bre"]/span[2]/text()')
item['公司地点'] = item['公司地点'][0] if len(item['公司地点'])>0 else None
item['公司性质'] = str_html.xpath('//div[@class="info"]/div[@class="m_bre"]/span[1]/text()')
item['公司性质'] = item['公司性质'][0] if len(item['公司性质'])>0 else None
item['薪资'] = str_html.xpath('//p[@class="sal"]/text()')
item['薪资'] = item['薪资'][0] if len(item['薪资'])>0 else None
item['学历要求'] = str_html.xpath('//div[@class="jbox"]/div[@class="m_bre"]/span[3]/text()')
item['学历要求'] = item['学历要求'][0] if len(item['学历要求'])>0 else None
item['工作经验'] = str_html.xpath('//div[@class="jbox"]/div[@class="m_bre"]/span[4]/text()')
item['工作经验'] = item['工作经验'][0] if len(item['工作经验'])>0 else None
item['公司规模'] = str_html.xpath('//div[@class="info"]/div[@class="m_bre"]/span[2]/text()')
item['公司规模'] = item['公司规模'][0] if len(item['公司规模'])>0 else None
item['公司类型'] = str_html.xpath('//div[@class="info"]/div[@class="m_bre"]/span[3]/text()')
item['公司类型'] = item['公司类型'][0] if len(item['公司类型'])>0 else None
item['公司福利'] = str_html.xpath('//div[@class="tbox"]/span/text()')
item['公司福利'] = '-'.join(item['公司福利'])
item['发布时间'] = str_html.xpath('//span[@class="date"]/text()')
item['发布时间'] = item['发布时间'][0] if len(item['发布时间'])>0 else None
print(item)
self.save(item)
def save(self,item):
self.collection.insert(item)
def run(self):
rest = requests.get(self.start_url,headers = self.headers)
str_html = html.etree.HTML(rest.content.decode())
total_num = str_html.xpath('//p[@class="result"]/span/text()')[0]
url_list = self.get_url_list(total_num)
for i in url_list:
str_html = self.parse_url(i)
self.get_content_list(str_html)
if __name__ == '__main__':
job = JobSpider()
job.run()
二、数据分析和数据可视化部分
数据分析和数据可视化说明:
1、本博客通过Flask框架来进行数据分析和数据可视化
2、项目的架构图为

代码展示
- 数据分析代码展示(analysis.py)
import re
import pandas as pd
import numpy as np
from pymongo import MongoClient
import pymysql
def salary_process(df):
df['薪资'] = df['薪资'].apply(
lambda x: str(round(float(re.findall('(.*)元', x)[0]) / 1000 * 30, 1)) if x.endswith('元/天') else x)
df['薪资'] = df['薪资'].apply(lambda x: str(
round((float(re.findall(r'(.*)千', x)[0].split('-')[0]) + float(re.findall(r'(.*)千', x)[0].split('-')[1])) / 2,
1)) if x.endswith('千/月') else x)
df['薪资'] = df['薪资'].apply(lambda x: str(round(
(float(re.findall(r'(.*)万', x)[0].split('-')[0]) + float(re.findall(r'(.*)万', x)[0].split('-')[1])) / 2 * 10,
1)) if len(re.findall(r'万', x)) > 0 and len(re.findall(r'-', x)) > 0 else x)
df['薪资'] = df['薪资'].apply(lambda x: re.findall('(.*)千以下', x)[0] if x.endswith('千以下/月') else x)
df['薪资'] = df['薪资'].apply(lambda x: x if len(re.findall('\d\.\d', x)) > 0 else np.nan)
df['薪资'].dropna(how='any', inplace=True)
df['薪资'] = df['薪资'].astype(np.float)
df.reset_index(drop=True, inplace=True)
return df
def experience_salary(df):
grouped = df.groupby('工作经验')['薪资'].mean().reset_index()
grouped = grouped[(grouped['工作经验'].str.contains('经验'))|(grouped['工作经验'].str.contains('在校生'))]
grouped['薪资'] = grouped['薪资'].apply(lambda x:round(x/10,1))
data = [[i['工作经验'],i['薪资']] for i in grouped.to_dict(orient='records')]
print(data)
return data
def education_salary(df):
grouped = df.groupby('学历要求').mean().reset_index()
grouped['薪资'] = grouped['薪资'].apply(lambda x:round(x/10,1))
grouped = grouped[grouped['学历要求'].str.contains('经验')==False]
data = [[i['学历要求'],i['薪资']] for i in grouped.to_dict(orient='records')]
return data
def city_need(df):
geoCoordMap = {
'海门': [121.15, 31.89],
'鄂尔多斯': [109.781327, 39.608266],
'招远': [120.38, 37.35],
'舟山': [122.207216, 29.985295],
'齐齐哈尔': [123.97, 47.33],
'盐城': [120.13, 33.38],
'赤峰': [118.87, 42.28],
'青岛': [120.33, 36.07],
'乳山': [121.52, 36.89],
'金昌': [102.188043, 38.520089],
'泉州': [118.58, 24.93],
'莱西': [120.53, 36.86],
'日照': [119.46, 35.42],
'胶南': [119.97, 35.88],
'南通': [121.05, 32.08],
'拉萨': [91.11, 29.97],
'云浮': [112.02, 22.93],
'梅州': [116.1, 24.55],
'文登': [122.05, 37.2],
'上海': [121.48, 31.22],
'攀枝花': [101.718637, 26.582347],
'威海': [122.1, 37.5],
'承德': [117.93, 40.97],
'厦门': [118.1, 24.46],
'汕尾': [115.375279, 22.786211],
'潮州': [116.63, 23.68],
'丹东': [124.37, 40.13],
'太仓': [121.1, 31.45],
'曲靖': [103.79, 25.51],
'烟台': [121.39, 37.52],
'福州': [119.3, 26.08],
'瓦房店': [121.979603, 39.627114],
'即墨': [120.45, 36.38],
'抚顺': [123.97, 41.97],
'玉溪': [102.52, 24.35],
'张家口': [114.87, 40.82],
'阳泉': [113.57, 37.85],
'莱州': [119.942327, 37.177017],
'湖州': [120.1, 30.86],
'汕头': [116.69, 23.39],
'昆山': [120.95, 31.39],
'宁波': [121.56, 29.86],
'湛江': [110.359377, 21.270708],
'揭阳': [116.35, 23.55],
'荣成': [122.41, 37.16],
'连云港': [119.16, 34.59],
'葫芦岛': [120.836932, 40.711052],
'常熟': [120.74, 31.64],
'东莞': [113.75, 23.04],
'河源': [114.68, 23.73],
'淮安': [119.15, 33.5],
'泰州': [119.9, 32.49],
'南宁': [108.33, 22.84],
'营口': [122.18, 40.65],
'惠州': [114.4, 23.09],
'江阴': [120.26, 31.91],
'蓬莱': [120.75, 37.8],
'韶关': [113.62, 24.84],
'嘉峪关': [98.289152, 39.77313],
'广州': [113.23, 23.16],
'延安': [109.47, 36.6],
'太原': [112.53, 37.87],
'清远': [113.01, 23.7],
'中山': [113.38, 22.52],
'昆明': [102.73, 25.04],
'寿光': [118.73, 36.86],
'盘锦': [122.070714, 41.119997],
'长治': [113.08, 36.18],
'深圳': [114.07, 22.62],
'珠海': [113.52, 22.3],
'宿迁': [118.3, 33.96],
'咸阳': [108.72, 34.36],
'铜川': [109.11, 35.09],
'平度': [119.97, 36.77],
'佛山': [113.11, 23.05],
'海口': [110.35, 20.02],
'江门': [113.06, 22.61],
'章丘': [117.53, 36.72],
'肇庆': [112.44, 23.05],
'大连': [121.62, 38.92],
'临汾': [111.5, 36.08],
'吴江': [120.63, 31.16],
'石嘴山': [106.39, 39.04],
'沈阳': [123.38, 41.8],
'苏州': [120.62, 31.32],
'茂名': [110.88, 21.68],
'嘉兴': [120.76, 30.77],
'长春': [125.35, 43.88],
'胶州': [120.03336, 36.264622],
'银川': [106.27, 38.47],
'张家港': [120.555821, 31.875428],
'三门峡': [111.19, 34.76],
'锦州': [121.15, 41.13],
'南昌': [115.89, 28.68],
'柳州': [109.4, 24.33],
'三亚': [109.511909, 18.252847],
'自贡': [104.778442, 29.33903],
'吉林': [126.57, 43.87],
'阳江': [111.95, 21.85],
'泸州': [105.39, 28.91],
'西宁': [101.74, 36.56],
'宜宾': [104.56, 29.77],
'呼和浩特': [111.65, 40.82],
'成都': [104.06, 30.67],
'大同': [113.3, 40.12],
'镇江': [119.44, 32.2],
'桂林': [110.28, 25.29],
'张家界': [110.479191, 29.117096],
'宜兴': [119.82, 31.36],
'北海': [109.12, 21.49],
'西安': [108.95, 34.27],
'金坛': [119.56, 31.74],
'东营': [118.49, 37.46],
'牡丹江': [129.58, 44.6],
'遵义': [106.9, 27.7],
'绍兴': [120.58, 30.01],
'扬州': [119.42, 32.39],
'常州': [119.95, 31.79],
'潍坊': [119.1, 36.62],
'重庆': [106.54, 29.59],
'台州': [121.420757, 28.656386],
'南京': [118.78, 32.04],
'滨州': [118.03, 37.36],
'贵阳': [106.71, 26.57],
'无锡': [120.29, 31.59],
'本溪': [123.73, 41.3],
'克拉玛依': [84.77, 45.59],
'渭南': [109.5, 34.52],
'马鞍山': [118.48, 31.56],
'宝鸡': [107.15, 34.38],
'焦作': [113.21, 35.24],
'句容': [119.16, 31.95],
'北京': [116.46, 39.92],
'徐州': [117.2, 34.26],
'衡水': [115.72, 37.72],
'包头': [110, 40.58],
'绵阳': [104.73, 31.48],
'乌鲁木齐': [87.68, 43.77],
'枣庄': [117.57, 34.86],
'杭州': [120.19, 30.26],
'淄博': [118.05, 36.78],
'鞍山': [122.85, 41.12],
'溧阳': [119.48, 31.43],
'库尔勒': [86.06, 41.68],
'安阳': [114.35, 36.1],
'开封': [114.35, 34.79],
'济南': [117, 36.65],
'德阳': [104.37, 31.13],
'温州': [120.65, 28.01],
'九江': [115.97, 29.71],
'邯郸': [114.47, 36.6],
'临安': [119.72, 30.23],
'兰州': [103.73, 36.03],
'沧州': [116.83, 38.33],
'临沂': [118.35, 35.05],
'南充': [106.110698, 30.837793],
'天津': [117.2, 39.13],
'富阳': [119.95, 30.07],
'泰安': [117.13, 36.18],
'诸暨': [120.23, 29.71],
'郑州': [113.65, 34.76],
'哈尔滨': [126.63, 45.75],
'聊城': [115.97, 36.45],
'芜湖': [118.38, 31.33],
'唐山': [118.02, 39.63],
'平顶山': [113.29, 33.75],
'邢台': [114.48, 37.05],
'德州': [116.29, 37.45],
'济宁': [116.59, 35.38],
'荆州': [112.239741, 30.335165],
'宜昌': [111.3, 30.7],
'义乌': [120.06, 29.32],
'丽水': [119.92, 28.45],
'洛阳': [112.44, 34.7],
'秦皇岛': [119.57, 39.95],
'株洲': [113.16, 27.83],
'石家庄': [114.48, 38.03],
'莱芜': [117.67, 36.19],
'常德': [111.69, 29.05],
'保定': [115.48, 38.85],
'湘潭': [112.91, 27.87],
'金华': [119.64, 29.12],
'岳阳': [113.09, 29.37],
'长沙': [113, 28.21],
'衢州': [118.88, 28.97],
'廊坊': [116.7, 39.53],
'菏泽': [115.480656, 35.23375],
'合肥': [117.27, 31.86],
'武汉': [114.31, 30.52],
'大庆': [125.03, 46.58]
};
geoCoordMap = list(geoCoordMap.keys())
df['公司地点'] = df['公司地点'].apply(lambda x:x.split('-')[0] if len(re.findall(r'-',x))>0 else x)
grouped = df.groupby('公司地点')['职位'].count().reset_index()
grouped = grouped[grouped['公司地点'].isin(geoCoordMap)].sort_values('职位',ascending=False)
data = [[i['公司地点'], i['职位']] for i in grouped.to_dict(orient='records')]
return data
def experience_count(df):
grouped = df.groupby('工作经验')['职位'].count().reset_index()
grouped = grouped[(grouped['工作经验'].str.contains('经验'))|(grouped['工作经验'].str.contains('在校生'))]
data = [[i['工作经验'], i['职位']] for i in grouped.to_dict(orient='records')]
return data
def eduction_count(df):
grouped = df.groupby('学历要求')['职位'].count().reset_index()
grouped = grouped[grouped['学历要求'].str.contains('经验')==False]
data = [[i['学历要求'],i['职位']] for i in grouped.to_dict(orient='records')]
print(data)
return data
def welfare_count(df):
welfare = df['公司福利'].str.split('-').tolist()
welfare_list = [j for i in welfare for j in i]
welfare_list = list(set(welfare_list))
zero_list = pd.DataFrame(np.zeros((len(welfare),len(welfare_list))),columns=welfare_list)
for i in welfare_list:
zero_list[i][df['公司福利'].str.contains(i)] = 1
welfare_nums = zero_list.sum().astype(np.int).sort_values(ascending=False)
welfare_nums = welfare_nums.reset_index()
welfare_nums = welfare_nums.replace(['五险','年终奖','绩效奖','体检'],['五险一金','年终奖金','绩效奖金','定期体检'])[:25]
welfare_nums = welfare_nums.replace(['.*补贴','.*年假','.*旅游','.*双休','.*医疗.*','.*奖金'],['补贴','带薪年假','员工旅游','周末双休','医疗保险','奖金'],regex=True)
welfare_nums.columns = ['员工福利', '数量']
grouped = welfare_nums.groupby('员工福利')['数量'].sum().reset_index()
grouped = grouped.sort_values(by='数量',ascending=False)[:10]
print(grouped)
data = [[i['员工福利'],i['数量']] for i in grouped.to_dict(orient='records')]
print(data)
return data
if __name__ == '__main__':
client = MongoClient()
collection = client['test']['wuyou_job']
jobs = collection.find({}, {'_id': 0})
df = pd.DataFrame(jobs)
df.drop_duplicates(subset=['职位', '公司名称', '公司地点',
'公司性质', '薪资', '学历要求', '工作经验', '公司规模', '公司类型', '公司福利', '发布时间'], keep='first')
df['公司福利'] = df['公司福利'].apply(lambda x: x if len(x) > 0 else np.nan)
df.dropna(how='any', inplace=True)
df = salary_process(df)
print(df.head(1))
print(df.info())
data = welfare_count(df)
conn = pymysql.connect(host='localhost',port=3306,user='root',password='123456',database='wuyou',charset='utf8')
with conn.cursor() as cursor:
try:
sql = 'insert into db_welfare_count(welfare,count) values(%s,%s)'
result = cursor.executemany(sql,data)
print(result)
conn.commit()
except pymysql.MySQLError as error:
print(error)
conn.rollback()
finally:
conn.close()
- 数据库模型文件展示(models.py)
from api_1_0 import db
class ExperienceSalary(db.Model):
__tablename__ = 'db_experience_salary'
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
exp_date = db.Column(db.String(64),nullable=False)
salary = db.Column(db.Float,nullable=False)
class EducationSalary(db.Model):
__tablename__ = 'db_education_salary'
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
edu_level = db.Column(db.String(64),nullable=False)
salary = db.Column(db.Float,nullable=False)
class CityJobs(db.Model):
__tablename__ = 'db_city_jobs'
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
city = db.Column(db.String(64),nullable=False)
count = db.Column(db.Integer,nullable=False)
class ExperienceCount(db.Model):
__tablename__ = 'db_experience_count'
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
exp_date = db.Column(db.String(64),nullable=False)
count = db.Column(db.Integer,nullable=False)
class EducationCount(db.Model):
__tablename__ = 'db_education_count'
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
edu_level = db.Column(db.String(64),nullable=False)
count = db.Column(db.Integer,nullable=False)
class WelfareCount(db.Model):
__tablename__ = 'db_welfare_count'
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
welfare = db.Column(db.String(64),nullable=True)
count = db.Column(db.Integer,nullable=False)
- 配置文件代码展示(config.py)
class Config(object):
SECRET_KEY = 'ma5211314'
SQLALCHEMY_DATABASE_URI = 'mysql://root:123456@localhost:3306/wuyou'
SQLALCHEMY_TRACK_MODIFICATIONS = True
class DevelopmentConfig(Config):
DEBUG = True
class ProjectConfig(Config):
pass
config_map = {'develop':DevelopmentConfig,'project':ProjectConfig}
- 主工程目录代码展示(api_1_0/_ _init__.py)
from flask import Flask
from config import config_map
from flask_sqlalchemy import SQLAlchemy
import pymysql
pymysql.install_as_MySQLdb()
db = SQLAlchemy()
def create_app(config_name='develop'):
app = Flask(__name__)
config = config_map[config_name]
app.config.from_object(config)
db.init_app(app)
from . import view
app.register_blueprint(view.blue,url_prefix='/show')
return app
- 主程序文件代码展示(manager.py)
import flask
from flask_script import Manager
from api_1_0 import create_app,db
from flask_migrate import Migrate,MigrateCommand
from flask import render_template
app = create_app()
manger = Manager(app)
Migrate(app,db)
manger.add_command('db',MigrateCommand)
@app.route('/')
def index():
return render_template('index.html')
if __name__ == '__main__':
manger.run()
- 视图文件代码展示(api_1_0/views/_ _init__.py,show.py)
_ _init__.py
from flask import Blueprint
from api_1_0 import db,models
blue = Blueprint('job',__name__)
from . import show
show.py
from api_1_0.view import blue
from ..models import EducationCount,EducationSalary,ExperienceCount,ExperienceSalary,WelfareCount,CityJobs
from flask import render_template
'''
将数据转换成列表的形式或者是列表嵌套字典的形式
locals()方法能够以字典的形式返回函数内所有声明的变量
'''
@blue.route('/drawLine')
def drawLine():
exp_data = ExperienceSalary.query.all()
exp_date = [i.exp_date for i in exp_data]
exp_sal = [i.salary for i in exp_data]
edu_data = EducationSalary.query.all()
edu_level = [i.edu_level for i in edu_data]
edu_sal = [i.salary for i in edu_data]
return render_template('showLine.html',**locals())
@blue.route('/drawGeo')
def drawGeo():
city_jobs_data = CityJobs.query.all()
city_job = [{'name':i.city,'value':i.count} for i in city_jobs_data]
return render_template('showGeo.html',**locals())
@blue.route('/drawBar')
def drawBar():
exp_count_data = ExperienceCount.query.all()
exp_date = [i.exp_date for i in exp_count_data]
count = [i.count for i in exp_count_data]
return render_template('showBar.html',**locals())
@blue.route('/drawPie')
def drawPie():
wel_count_data = WelfareCount.query.all()
wel_count = [{'name':i.welfare,'value':i.count} for i in wel_count_data]
edu_count_date = EducationCount.query.all()
edu_count = [{'name':i.edu_level,'value':i.count} for i in edu_count_date]
return render_template('showPie.html', **locals())
- 首页(index.html)
主页简单创建了四个超链接指向对应的图表
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>首页说明</title>
<style>
.container{
width: 100%;
height: 600px;
padding: 40px;
line-height: 60px;
}
ul{
margin: auto;
width: 60%;
}
</style>
</head>
<body>
<div class="container">
<ul>
<li><a href="http://127.0.0.1:5000/show/drawBar" target="_blank"><h3>工作经验与人数分布图</h3></a></li>
<li><a href="http://127.0.0.1:5000/show/drawGeo" target="_blank"><h3>python城市需求地理位置分布图</h3></a></li>
<li><a href="http://127.0.0.1:5000/show/drawLine" target="_blank"><h3>工作经验与薪资关系图&学历与薪资关系图</h3></a></li>
<li><a href="http://127.0.0.1:5000/show/drawPie" target="_blank"><h3>福利类型数量前十占比图&不同学历与求职人数占比图</h3></a></li>
</ul>
</div>
</body>
</html>

- 模板文件代码展示(showBar.html,showLine.html,showGeo.html,showPie.html)
showGeo.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>python城市需求地理位置分布图</title>
<script src="../static/js/echarts.min.js"></script>
<script src="../static/js/jquery.min.js"></script>
<script src="../static/theme/vintage.js"></script>
</head>
<body>
<div class="chart" style="width: 800px;height: 600px;margin: auto"></div>
<script>
// 初始化echarts
var MyCharts = echarts.init(document.querySelector('.chart'),'vintage')
// 获取视图函数传入数据并转换成json格式
var city_job = {{ city_job|tojson }}
var geoCoordMap = {
'海门':[121.15,31.89],
'鄂尔多斯':[109.781327,39.608266],
'招远':[120.38,37.35],
'舟山':[122.207216,29.985295],
'齐齐哈尔':[123.97,47.33],
'盐城':[120.13,33.38],
'赤峰':[118.87,42.28],
'青岛':[120.33,36.07],
'乳山':[121.52,36.89],
'金昌':[102.188043,38.520089],
'泉州':[118.58,24.93],
'莱西':[120.53,36.86],
'日照':[119.46,35.42],
'胶南':[119.97,35.88],
'南通':[121.05,32.08],
'拉萨':[91.11,29.97],
'云浮':[112.02,22.93],
'梅州':[116.1,24.55],
'文登':[122.05,37.2],
'上海':[121.48,31.22],
'攀枝花':[101.718637,26.582347],
'威海':[122.1,37.5],
'承德':[117.93,40.97],
'厦门':[118.1,24.46],
'汕尾':[115.375279,22.786211],
'潮州':[116.63,23.68],
'丹东':[124.37,40.13],
'太仓':[121.1,31.45],
'曲靖':[103.79,25.51],
'烟台':[121.39,37.52],
'福州':[119.3,26.08],
'瓦房店':[121.979603,39.627114],
'即墨':[120.45,36.38],
'抚顺':[123.97,41.97],
'玉溪':[102.52,24.35],
'张家口':[114.87,40.82],
'阳泉':[113.57,37.85],
'莱州':[119.942327,37.177017],
'湖州':[120.1,30.86],
'汕头':[116.69,23.39],
'昆山':[120.95,31.39],
'宁波':[121.56,29.86],
'湛江':[110.359377,21.270708],
'揭阳':[116.35,23.55],
'荣成':[122.41,37.16],
'连云港':[119.16,34.59],
'葫芦岛':[120.836932,40.711052],
'常熟':[120.74,31.64],
'东莞':[113.75,23.04],
'河源':[114.68,23.73],
'淮安':[119.15,33.5],
'泰州':[119.9,32.49],
'南宁':[108.33,22.84],
'营口':[122.18,40.65],
'惠州':[114.4,23.09],
'江阴':[120.26,31.91],
'蓬莱':[120.75,37.8],
'韶关':[113.62,24.84],
'嘉峪关':[98.289152,39.77313],
'广州':[113.23,23.16],
'延安':[109.47,36.6],
'太原':[112.53,37.87],
'清远':[113.01,23.7],
'中山':[113.38,22.52],
'昆明':[102.73,25.04],
'寿光':[118.73,36.86],
'盘锦':[122.070714,41.119997],
'长治':[113.08,36.18],
'深圳':[114.07,22.62],
'珠海':[113.52,22.3],
'宿迁':[118.3,33.96],
'咸阳':[108.72,34.36],
'铜川':[109.11,35.09],
'平度':[119.97,36.77],
'佛山':[113.11,23.05],
'海口':[110.35,20.02],
'江门':[113.06,22.61],
'章丘':[117.53,36.72],
'肇庆':[112.44,23.05],
'大连':[121.62,38.92],
'临汾':[111.5,36.08],
'吴江':[120.63,31.16],
'石嘴山':[106.39,39.04],
'沈阳':[123.38,41.8],
'苏州':[120.62,31.32],
'茂名':[110.88,21.68],
'嘉兴':[120.76,30.77],
'长春':[125.35,43.88],
'胶州':[120.03336,36.264622],
'银川':[106.27,38.47],
'张家港':[120.555821,31.875428],
'三门峡':[111.19,34.76],
'锦州':[121.15,41.13],
'南昌':[115.89,28.68],
'柳州':[109.4,24.33],
'三亚':[109.511909,18.252847],
'自贡':[104.778442,29.33903],
'吉林':[126.57,43.87],
'阳江':[111.95,21.85],
'泸州':[105.39,28.91],
'西宁':[101.74,36.56],
'宜宾':[104.56,29.77],
'呼和浩特':[111.65,40.82],
'成都':[104.06,30.67],
'大同':[113.3,40.12],
'镇江':[119.44,32.2],
'桂林':[110.28,25.29],
'张家界':[110.479191,29.117096],
'宜兴':[119.82,31.36],
'北海':[109.12,21.49],
'西安':[108.95,34.27],
'金坛':[119.56,31.74],
'东营':[118.49,37.46],
'牡丹江':[129.58,44.6],
'遵义':[106.9,27.7],
'绍兴':[120.58,30.01],
'扬州':[119.42,32.39],
'常州':[119.95,31.79],
'潍坊':[119.1,36.62],
'重庆':[106.54,29.59],
'台州':[121.420757,28.656386],
'南京':[118.78,32.04],
'滨州':[118.03,37.36],
'贵阳':[106.71,26.57],
'无锡':[120.29,31.59],
'本溪':[123.73,41.3],
'克拉玛依':[84.77,45.59],
'渭南':[109.5,34.52],
'马鞍山':[118.48,31.56],
'宝鸡':[107.15,34.38],
'焦作':[113.21,35.24],
'句容':[119.16,31.95],
'北京':[116.46,39.92],
'徐州':[117.2,34.26],
'衡水':[115.72,37.72],
'包头':[110,40.58],
'绵阳':[104.73,31.48],
'乌鲁木齐':[87.68,43.77],
'枣庄':[117.57,34.86],
'杭州':[120.19,30.26],
'淄博':[118.05,36.78],
'鞍山':[122.85,41.12],
'溧阳':[119.48,31.43],
'库尔勒':[86.06,41.68],
'安阳':[114.35,36.1],
'开封':[114.35,34.79],
'济南':[117,36.65],
'德阳':[104.37,31.13],
'温州':[120.65,28.01],
'九江':[115.97,29.71],
'邯郸':[114.47,36.6],
'临安':[119.72,30.23],
'兰州':[103.73,36.03],
'沧州':[116.83,38.33],
'临沂':[118.35,35.05],
'南充':[106.110698,30.837793],
'天津':[117.2,39.13],
'富阳':[119.95,30.07],
'泰安':[117.13,36.18],
'诸暨':[120.23,29.71],
'郑州':[113.65,34.76],
'哈尔滨':[126.63,45.75],
'聊城':[115.97,36.45],
'芜湖':[118.38,31.33],
'唐山':[118.02,39.63],
'平顶山':[113.29,33.75],
'邢台':[114.48,37.05],
'德州':[116.29,37.45],
'济宁':[116.59,35.38],
'荆州':[112.239741,30.335165],
'宜昌':[111.3,30.7],
'义乌':[120.06,29.32],
'丽水':[119.92,28.45],
'洛阳':[112.44,34.7],
'秦皇岛':[119.57,39.95],
'株洲':[113.16,27.83],
'石家庄':[114.48,38.03],
'莱芜':[117.67,36.19],
'常德':[111.69,29.05],
'保定':[115.48,38.85],
'湘潭':[112.91,27.87],
'金华':[119.64,29.12],
'岳阳':[113.09,29.37],
'长沙':[113,28.21],
'衢州':[118.88,28.97],
'廊坊':[116.7,39.53],
'菏泽':[115.480656,35.23375],
'合肥':[117.27,31.86],
'武汉':[114.31,30.52],
'大庆':[125.03,46.58]
};
var convertData = function (data) {
var res = [];
for (var i = 0; i < data.length; i++) {
var geoCoord = geoCoordMap[data[i].name];
if (geoCoord) {
res.push({
name: data[i].name,
value: geoCoord.concat(data[i].value)
});
}
}
return res;
}
$.get('../static/json/map/my_china.json',function (ret){
echarts.registerMap('chinaMap',ret)
var option = {
geo:{
type:'map',
map:'chinaMap',
roam:true,
label:{
show:true,
fontSize:10,
},
itemStyle: {
color: 'Moccasin'
},
zoom:2
},
series:[
{
data: convertData(city_job),
type: 'effectScatter',
rippleEffect: {
scale: 2 // 设置涟漪动画的缩放比例
},
itemStyle:{
color:'red'
},
coordinateSystem:'geo',
label:{
show: true,
position:'bottom',
formatter:function (rst)
{
return '城市:'+rst.name+'\n所需岗位:'+rst.value[2]
}
}
}
],
}
MyCharts.setOption(option)
})
</script>
</body>
</html>
图表可以进行缩放进行详细查看

结论:
中国东部以及东南部对Python人才的需求量大,其中以北京、上海、广州、深圳最为突出。
showBar.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>工作经验的人数分布图</title>
<script src="../static/js/echarts.min.js"></script>
<script src="../static/theme/vintage.js"></script>
</head>
<body>
<div class="chart" style="width: 800px;height: 600px;margin: auto"></div>
<script>
// 初始化echarts
var myCharts = echarts.init(document.querySelector('.chart'),'vintage')
// 获取视图函数传入数据并转换成json格式
var exp_date = {{ exp_date|tojson }}
var count = {{ count|tojson }}
var option = {
title:{
text:'工作经验的人数分布图',
textStyle:{
fontSize:21,
fontFamily:'楷体'
}
},
xAxis:{
type:'category',
data:exp_date,
axisLabel:{
interval:0,
rotate:40,
margin:10
}
},
yAxis:{
type:'value',
scale:true
},
tooltip:{
trigger:'item',
triggerOn:'mousemove',
formatter:function (rst){
return '工作经验:'+rst.name+''+'所需岗位:'+rst.value+'个'
}
},
legend:{
name: ['人数']
},
series:[
{
name:'人数',
type:'bar',
data:count,
label:{
show:true,
rotate: 40,
position:'top',
distance:10
},
}
]
}
myCharts.setOption(option)
</script>
</body>
</html>
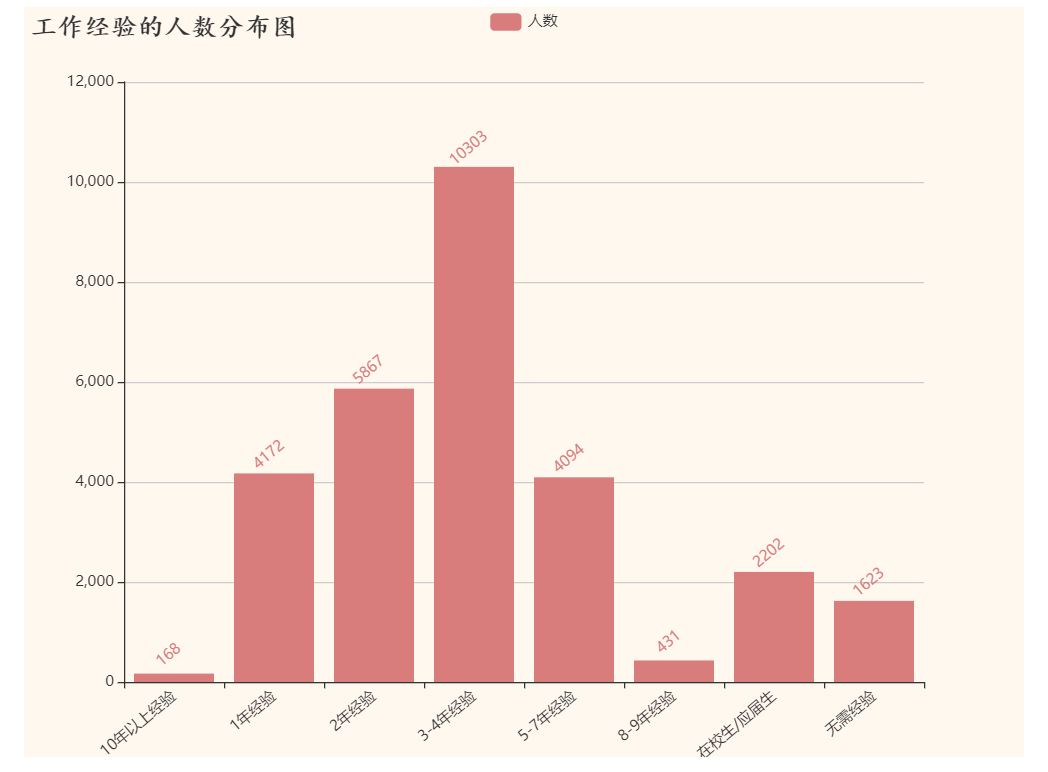
结论:
Python人才需求主要集中在3-4年工作经验,市场对Python工作经验较高的人才需求较少。
showLine.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>工作经验与薪资关系图&学历与薪资关系图</title>
<script src="../static/js/echarts.min.js"></script>
<script src="../static/theme/dark.js"></script>
<script src="../static/theme/my_theme.js"></script>
<script src="../static/theme/vintage.js"></script>
<style>
.chart-group{
width: 100%;
height: 1000px;
padding: 50px;
display: flex;
justify-content: space-evenly;
margin: auto;
}
.chart1{
width: 600px;
height: 400px;
}
.chart2{
width: 600px;
height: 400px;
}
</style>
</head>
<body>
<div class="chart-group">
<div class="chart1"></div>
<div class="chart2"></div>
</div>
<script>
// 初始化echarts
var myCharts1 = echarts.init(document.querySelector('.chart1'),'vintage')
var myCharts2 = echarts.init(document.querySelector('.chart2'),'vintage')
// 获取视图函数传入数据并转换成json格式
var exp_date = {{ exp_date|tojson }}
var exp_sal = {{ exp_sal|tojson }}
var edu_level = {{ edu_level|tojson }}
var edu_sal = {{ edu_sal|tojson }}
function getOption(category,data,desc){
var option = {
title:{
text : desc,
textStyle:{
fontFamily:'楷体',
fontSize:21
}
},
xAxis:{
type:'category',
data:category,
axisLabel:{
interval:0,
rotate:40,
margin:10
}
},
yAxis:{
type:'value',
scale:true
},
legend:{
name:['工资水平']
},
tooltip:{
trigger:'axis',
triggerOn:'mousemove',
formatter: function (rst){
if(desc=="工作经验与薪资关系图"){
return '工作经验:'+rst[0].name+''+'每月薪资:'+rst[0].value+'k/月'
}else{
return '学历:'+rst[0].name+''+'每月薪资:'+rst[0].value+'k/月'
}
}
},
series:[
{
name:'工资水平',
type:'line',
data:data,
label:{
show:true
},
smooth:true,
markPoint:{
data:[
{
name:'最大值',
type:"max",
symbolSize:[40,40],//容器大小
symbolOffset:[0,-20],//位置偏移,
label:{
show:true,
formatter:function (rst){
return rst.name
}
}
},
{
name:'最小值',
type:'min',
symbolSize:[40,40],//容器大小
symbolOffset:[0,-20],//位置偏移
label:{
show:true,
formatter:function (rst){
return rst.name
}
}
}
]
},
markLine:{
data:[
{
name:'平均值',
type:'average',
label:{
formatter:function (rst)
{
return rst.name+":\n"+rst.value
}
}
}
]
}
}
]
}
return option
}
var option1 = getOption(exp_date,exp_sal,'工作经验与薪资关系图')
var option2 = getOption(edu_level,edu_sal,'学历与薪资关系图')
myCharts1.setOption(option1)
myCharts2.setOption(option2)
</script>
</body>
</html>
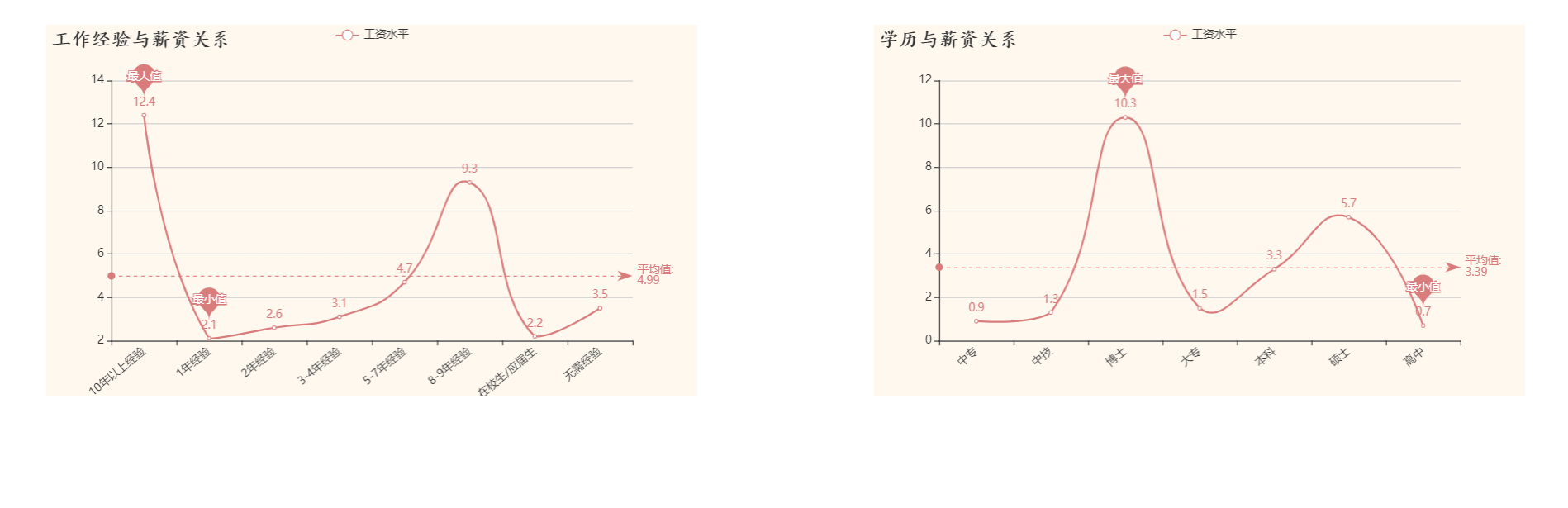
结论:
工作经验和学历与薪资呈正相关,工作经验越丰富工资越高,学历越高工资越高。
showPie.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>福利类型数量前十占比&不同学历与求职人数占比</title>
<script src="../static/js/echarts.min.js"></script>
<script src="../static/theme/dark.js"></script>
<script src="../static/theme/my_theme.js"></script>
<script src="../static/theme/vintage.js"></script>
<style>
.chart-group{
width: 100%;
height: 1000px;
padding: 50px;
display: flex;
justify-content: space-evenly;
margin: auto;
}
.chart1{
width: 600px;
height: 400px;
}
.chart2{
width: 600px;
height: 400px;
}
</style>
</head>
<body>
<div class="chart-group">
<div class="chart1"></div>
<div class="chart2"></div>
</div>
<script>
// 初始化echarts
var myCharts1 = echarts.init(document.querySelector('.chart1'),'vintage')
var myCharts2 = echarts.init(document.querySelector('.chart2'),'vintage')
// 获取视图函数传入数据并转换成json格式
var wel_count = {{ wel_count|tojson }}
var edu_count = {{ edu_count|tojson }}
var value = []
function getOption(data,desc){
var option = {
title:{
text : desc,
textStyle:{
fontFamily:'楷体',
fontSize:21
},
},
tooltip:{
trigger:'item',
triggerOn:'mousemove',
formatter:function(rst){
if(desc=="工作经验的人数分布图"){
return '福利类型:'+rst.name+''+'企业数量:'+rst.value+'个'+''+'占比:'+rst.percent+"%"
}else{
return '学历:'+rst.name+''+'所需岗位:'+rst.value+'人'+''+'占比:'+rst.percent+"%"
}
}
},
legend:{
name:['人数占比'],
orient: 'vertical',
bottom:10,
right:10,
},
series:[
{
name:'人数占比',
type:'pie',
data:data,
label:{
show:true
},
roseType:'radius',
selectedMode:'multiple',
selectedOffset: 10
}
]
}
return option
}
var option1 = getOption(wel_count,'福利类型数量前十占比')
var option2 = getOption(edu_count,'学历人数占比图')
myCharts1.setOption(option1)
myCharts2.setOption(option2)
</script>
</body>
</html>
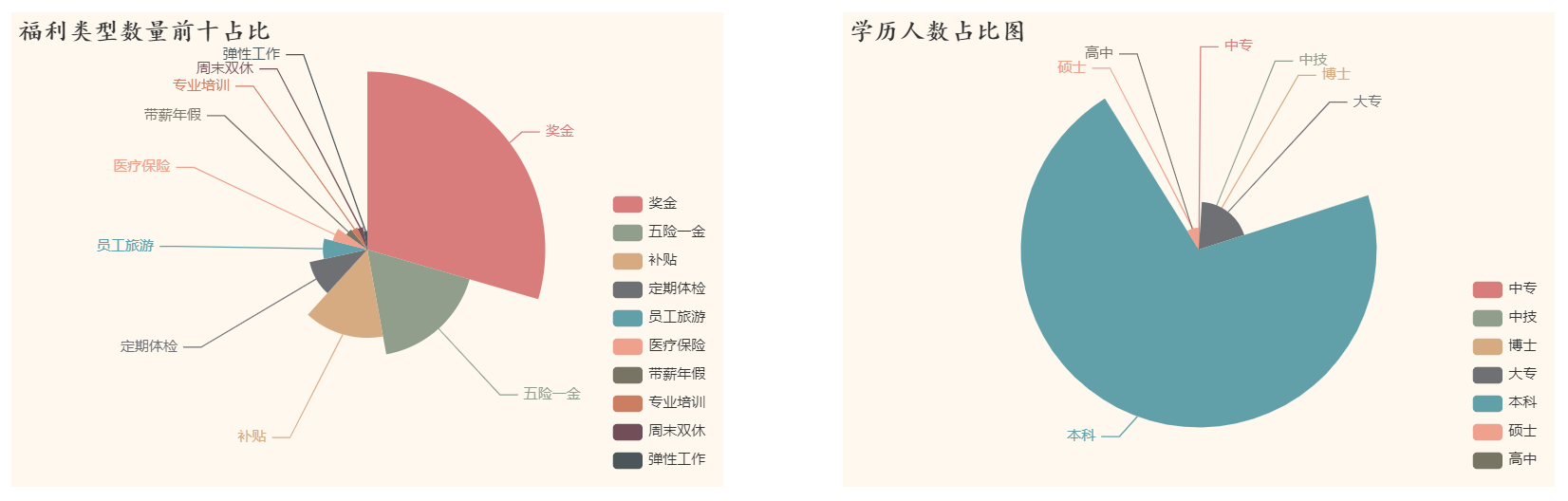
结论:
福利类型前十中,奖金的占比超过了总占比的四分之一;学历人数中Python岗位对本科人数的需求占据总需求半数以上,对高学历和低学历的需求相对较少。
以下项目源码,希望能够帮助你们,如有疑问,下方评论
flask项目代码链接
Original: https://blog.csdn.net/qq_45821420/article/details/112663825
Author: 专业的小马哥
Title: Python爬虫实战+数据分析+数据可视化(前程无忧招聘信息)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/749586/
转载文章受原作者版权保护。转载请注明原作者出处!