

本篇博文,首发在AIexplore微信公众号,内容总体相同,均为原创,特此申明。
0.教程代码环境
其他环境也可以,不一定非要一样
python 3.6
numpy 1.19.3
matplotlib 3.2.1
scipy 1.4.1
1.偏度
定义:偏度(skewness),是统计数据分布偏斜方向和程度的度量,或者说是统计数据分布非对称程度的数字特征。
说人话:偏度或偏态系数或偏度系数(Skewness)用来度量分布是否对称,一个分布如果不对称,则被称为偏度。
分布分为三种:对称分布(正态分布)、正偏分布(右偏分布)、负偏分布(左偏分布)
对称分布的特点:左右对称,均值 = 中位数 = 众数,偏度 = 0
正偏分布的特点:右侧长尾,均值 >中位数 >众数,偏度 > 0
负偏分布的特点:左侧长尾,均值 < 中位数 < 众数,偏度 < 0
1.1 绘制三种分布图
1.1.1 使用python代码绘制正态分布:
代码:
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
def plot():
"""
绘制标准的正态分布
draw standard deviation normal distribution
"""
mu = 0.0
sd = 1.0
x = np.linspace(mu - 4 * sd, mu + 4 * sd, 100)
y = stats.norm.pdf(x)
plt.plot(x, y, "g", linewidth = 2)
plt.grid(True)
plt.show()
if __name__ == '__main__':
plot()
分布图:

1.1.2 使用python代码绘制右偏分布:
代码:
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
def plot():
"""
绘制标准的正偏分布
"""
mu = 0.0
sd = 1.0
x = np.linspace(mu - 3 * sd, mu + 5 * sd, 100)
y = stats.norm.pdf(x)
plt.plot(x, y, "g", linewidth = 2)
plt.grid(True)
plt.show()
if __name__ == '__main__':
plot()
分布图:
1.1.3 使用python代码绘制左偏分布:
代码:
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
def plot():
"""
绘制标准的正偏分布
"""
mu = 0.0
sd = 1.0
x = np.linspace(mu - 5 * sd, mu + 3 * sd, 100)
y = stats.norm.pdf(x)
plt.plot(x, y, "g", linewidth = 2)
plt.grid(True)
plt.show()
if __name__ == '__main__':
plot()
分布图:
1.2 偏度计算
计算公式:

有的文章里面计算公式是这样的:

以上公式来自不同的出处,我不是学数学的,因此对这些内容没有太深入的研究(主要是我以前从来没遇到过,知识盲区;如果有学数学的朋友懂这方面知识,可以私聊我给我普及一下),我的理解是公式1和公式2应该没有对错之分,只是”选择”不同罢了(不知道对不对,如有大佬请在评论区修正),那我们计算偏度到底使用哪个公式呢?请继续阅读下文。
具体例子:
一组数据:arr = [1,4,6,8,10,20]
arr的均值和标准差我们使用numpy库直接进行计算 :
均值:
import numpy as np
arr = np.array([1,4,6,8,10,20])
u = arr.mean()
print("均值:", u)

标准差:
标准差分为总体标准差(分母位n)和样本标准差(分母n-1)【为什么分为总体标准差和样本标准差,感兴趣的可以自己找资料研究,在此不深入说明了】
import numpy as np
arr = np.array([1,4,6,8,10,20])
a = arr.std(ddof=1)
print("标准差:", a)
这里我们使用无偏的标准差(不要问为什么,因为用无偏的比较”好”,大家都是用的无偏)。

知道了均值和标准差,就可以带入公式计算偏度了。
那么问题来了,我们应该带入到哪个公式呢?下面我们分别带入到2个公式中,查看一下结果。
使用公式1:
import numpy as np
import pandas as pd
from scipy import stats
arr = np.array([1,4,6,8,10,20])
n = len(arr)
u = arr.mean()
print("均值:", u)
a = arr.std(ddof=1)
print("标准差:", a)
a1 = sum(((arr-u)/a)**3)
a2 = a1*n/((n-1)*(n-2))
print("偏度:", a2)

使用公式2:
import numpy as np
import pandas as pd
from scipy import stats
arr = np.array([1,4,6,8,10,20])
n = len(arr)
u = arr.mean()
print("均值:", u)
a = arr.std(ddof=1)
print("标准差:", a)
a1 = sum(((arr-u)/a)**3)
a2 = a1/n
print("偏度:", a2)

可以看到使用不同公式计算得到的偏度不同:
公式1得到的偏度:1.2737636108819756
公式2得到的偏度:0.7076464504899865
不同公式得到的偏度肯定是不一样的,那我们到底应该采用哪一个偏度值呢?下面我们使用python科学计算包直接计算偏度:
使用pandas计算:
import numpy as np
import pandas as pd
arr = np.array([1,4,6,8,10,20])
print("--------使用pandas计算偏度和峰度--------")
data = pd.DataFrame(arr)
print("标准差:", data[0].std())
print("偏度:", data[0].skew())

可以看到,标准差6.5853372477547923,使用的是无偏标准差;偏度1.2737636108819759,和公式1计算的结果相同。从侧面验证了pandas库使用的是无偏标准差+公式1来计算偏度。
使用scipy计算:
import numpy as np
from scipy import stats
arr = np.array([1,4,6,8,10,20])
print("--------使用scipy计算偏度和峰度--------")
print("标准差:", stats.tstd(arr, ddof=1))
d = stats.skew(arr, bias=False)
print("偏度:", d)

可以看到,标准差6.585337247754792,使用的是无偏标准差;偏度1.2737636108819756,和公式1计算结果、pandas库计算结果相同。再次验证了应该使用公式1来计算偏度。
2.峰度
定义:峰度(peakedness;kurtosis)又称峰态系数。表征概率密度分布曲线在平均值处峰值高低的特征数。
说人话:峰度反映了峰部的尖度,用来度量数据在中心聚集程度,峰度越大分布图越尖,峰度越小分布图越矮胖。
2.1 绘制三种不同峰度的分布图
代码:
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
def plot():
"""
draw standard deviation normal distribution
"""
mu = 0.0
sd1 = 1.0
sd2 = 2.0
sd3 = 3.0
x = np.linspace(mu - 3 * sd1, mu + 3 * sd1, 50)
y = stats.norm.pdf(x)
plt.plot(x, y, "r", linewidth = 2)
x2 = np.linspace(mu - 6 * sd1, mu + 6 * sd1, 50)
y2 = stats.norm.pdf(x2, mu, sd2)
plt.plot(x2, y2, "g", linewidth = 2)
x3 = np.linspace(mu - 10 * sd1, mu + 10 * sd1, 50)
y3 = stats.norm.pdf(x3, mu, sd3)
plt.plot(x3, y3, "b", linewidth = 2)
plt.grid(True)
plt.show()
if __name__ == '__main__':
plot()
分布图:
相同均值,不同标准差的正态分布曲线
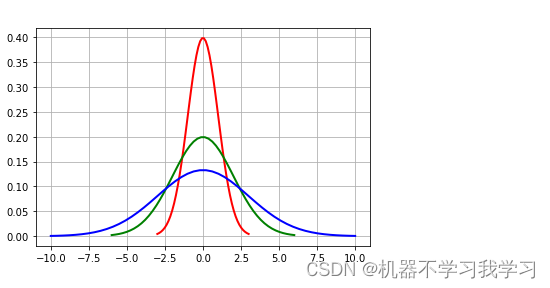
红色线条标准差是1,绿色线条标准差是2,蓝色线条标准差是3。
标准差越小,曲线越陡
标准差越大,曲线越平缓
红色线条:尖峰
绿色线条:中锋
蓝色线条:低峰
对于正态分布来说峰度=3,部分统计软件会给出超额峰度,超额峰度=峰度-3。
中锋分布的超额峰度=0, 尖峰分布的超额峰度>0,低峰分布的超额峰度<0。
2.2 峰度计算
峰度的计算公式,我也看到好几个版本,我想应该和偏度的计算类似,因此不再纠结它的计算公式,直接使用pandas或scipy进行计算。
代码:
import numpy as np
import pandas as pd
from scipy import stats
arr = np.array([1,4,6,8,10,20])
print("--------使用scipy计算偏度和峰度--------")
print("标准差:", stats.tstd(arr, ddof=1))
d = stats.skew(arr, bias=False)
print("偏度:", d)
e = stats.kurtosis(arr, bias=False)
print("峰度:", e)
print("--------使用pandas计算偏度和峰度--------")
data = pd.DataFrame(arr)
print("标准差:", data[0].std())
print("偏度:", data[0].skew())
print("峰度:", data[0].kurt())
结果:

3.整体代码
import numpy as np
import pandas as pd
from scipy import stats
arr = np.array([1,4,6,8,10,20])
print("--------使用scipy计算偏度和峰度--------")
print("标准差:", stats.tstd(arr, ddof=1))
d = stats.skew(arr, bias=False)
print("偏度:", d)
e = stats.kurtosis(arr, bias=False)
print("峰度:", e)
print("--------使用pandas计算偏度和峰度--------")
data = pd.DataFrame(arr)
print("标准差:", data[0].std())
print("偏度:", data[0].skew())
print("峰度:", data[0].kurt())
print("--------自己通过代码计算偏度和峰度,方式 1--------")
n = len(arr)
u = arr.mean()
print("均值", u)
a = arr.std(ddof=1)
print("标准差:", a)
a1 = sum(((arr-u)/a)**3)
a2 = a1*n/((n-1)*(n-2))
print("偏度:", a2)
print("--------自己通过代码计算偏度和峰度,方式 2--------")
list_v = []
for v in arr:
q = (v-u)**3
list_v.append(q)
b1 = sum(list_v)
b2 = b1/(a**3)
b3 = b2*n/((n-1)*(n-2))
print("偏度:", b3)
4.附录
我们也可以使用Excel直接计算一组数据的偏度和峰度。
Excel中的数据如下:

计算A1、A2、A3、A4、A5、A6数据的偏度和峰度。
偏度计算公式:=SKEW(A1:A6)
峰度计算公式:=KURT(A1:A6)
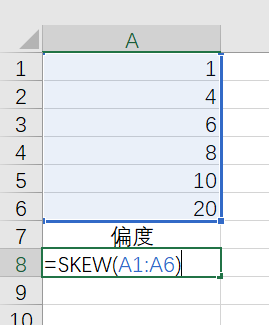
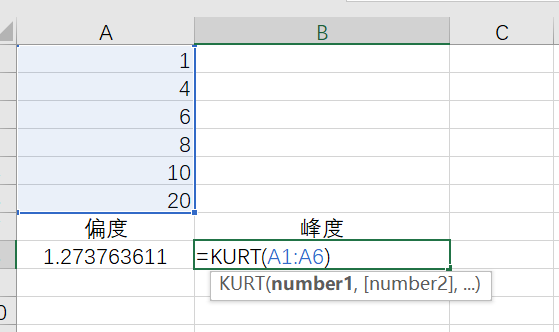
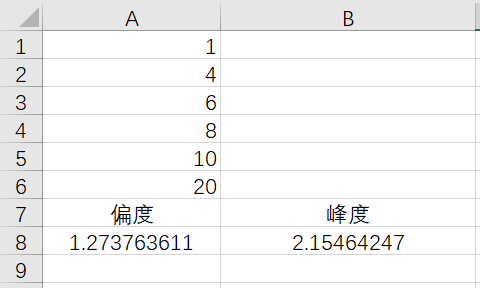
偏度1.2737,再一次验证了使用无偏标准差和公式1计算;峰度2.1546。
; 参考资料:
- https://blog.csdn.net/weixin_36236293/article/details/102632084
- https://zhidao.baidu.com/question/133028474.html
- https://blog.csdn.net/qq_36523839/article/details/88671873
- https://zhuanlan.zhihu.com/p/346810231
- https://zhuanlan.zhihu.com/p/84614017
Original: https://blog.csdn.net/AugustMe/article/details/127012415
Author: 机器不学习我学习
Title: 【python】计算偏度和峰度
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/763651/
转载文章受原作者版权保护。转载请注明原作者出处!