

目录
系列文章
2022李宏毅作业hw1—新冠阳性人员数量预测。_亮子李的博客-CSDN博客
目录
前言 :


但还是试着写写思路吧。git地址 和kaggle网址
https://github.com/xiaolilaoli/lihongyi2022homework/tree/main/2_phoneme
项目:
我的习惯 一般会把一个小项目做成下面的几个模块 这样非常的清晰
第一个就是数据模块 , 这部分的作用是读入数据。 接口输入是数据地址 返回的是各种loader
第二个是模型模块 。没啥好说的 ,就是创造模型。接口输入是特征数和分类数(分类任务), 出口是模型。
第三个是训练模块 。 这一部分要传入训练集 验证集 和超参数。步骤就是 梯度归0 模型前向过程得到预测结果 预测和标签比得到loss loss回传。模型更新。还有一些记录。 训练过后有一个验证过程 , 让模型在验证集上跑 ,最后得到验证集准确率。
第四个是验证模块。一般负责从模型和测试数据出发,得到想要验证的数据 。
第五个是main函数 。 整合各个模块 进行数据模型的传递。
我觉得模块化是非常有必要的 ,我一直想做一个万能模块。特别是数据部分,后来发现,想多了,面对每一个项目 总是免不了微调。大家可以逐渐形成自己的模块。
一: 数据 :

看到 数据一段编码好了的 声音片段 。 每一段是39长度的向量。 然后会给出前后五段的 数据 也就是我们有11*39 = 429 维度的一个特征 根据这个特征去做分类 。 有多少类呢 ?有39类 。数据被放在一个.npy的numpy文件中 。跟上次一样, 先创建一个读数据的dataset
x = np.load(traindataPath)
y = np.load(trainlabelPath)
y = y.astype(np.int)
把x,y读进来 把y转为int型

class phonemeDataset(Dataset):
def __init__(self, x, y=None):
self.x = torch.tensor(x)
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
def __getitem__(self, index):
if self.y is not None:
return self.x[index].float(), self.y[index]
else:
return self.x[index].float()
def __len__(self):
return len(self.x)
dataset 是非常基础的 init负责把数据读进来 getitem 负责在访问数据集时返回数据 我们返回的是float类型的特征数据 和longtensor的标签 len负责返回长度 。。 用这个文件做数据很简单。直接放完整代码 。 这部分被我放在model.utils 中的data里
import numpy as np
from torch.utils.data import Dataset,DataLoader
import torch
from sklearn.model_selection import train_test_split
class phonemeDataset(Dataset):
def __init__(self, x, y=None):
self.x = torch.tensor(x)
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
def __getitem__(self, index):
if self.y is not None:
return self.x[index].float(), self.y[index]
else:
return self.x[index].float()
def __len__(self):
return len(self.x)
def getDataset(path,mode):
if mode == 'train' or mode == 'trainAndVal':
traindataPath = path + '/' + 'train_11.npy'
trainlabelPath = path + '/' + 'train_label_11.npy'
x = np.load(traindataPath)
y = np.load(trainlabelPath)
# x = x[:, 3*39:8*39]
y = y.astype(np.int)
if mode == 'trainAndVal':
trainAndValset = phonemeDataset(x, y)
return trainAndValset
else:
train_x,val_x, train_y, val_y = train_test_split(x, y, test_size=0.05,shuffle=True,random_state=0)
trainset = phonemeDataset(train_x, train_y)
valset = phonemeDataset(val_x, val_y)
return trainset, valset
elif mode == 'test':
testdataPath = path + '/' + 'test_11.npy'
x = np.load(testdataPath)
# x = x[:, 3*39:8*39]
testset = phonemeDataset(x)
return testset
def getDataLoader(path, mode, batchSize):
assert mode in ['train', 'test', 'trainAndVal']
if mode == 'train':
trainset, valset = getDataset(path, mode)
trainloader = DataLoader(trainset,batch_size=batchSize, shuffle=True)
valloader = DataLoader(valset,batch_size=batchSize, shuffle=True)
return trainloader,valloader
elif mode == 'trainAndVal':
trainAndValset = getDataset(path, mode)
trainAndValloader = DataLoader(trainAndValset,batch_size=batchSize, shuffle=True)
return trainAndValloader
elif mode == 'test':
testset = getDataset(path, mode)
testLoader = DataLoader(testset, batch_size=batchSize, shuffle=False)
return testLoader
二: 模型
很基础的一个模型 就是fc+relu+dropout 我不知道怎么样去改出来一个好模型 只是感觉 都差不多。
这部分被我放在model.utils 中的model里
class myNet(nn.Module):
def __init__(self, inDim, outDim):
super(myNet,self).__init__()
self.fc1 = nn.Linear(inDim, 1024)
self.relu1 = nn.ReLU()
self.drop1 = nn.Dropout(0.5)
self.fc2 = nn.Linear(1024, 1024)
self.relu2 = nn.ReLU()
self.drop2 = nn.Dropout(0.5)
self.fc3 = nn.Linear(1024, 512)
self.relu3 = nn.ReLU()
self.fc4 = nn.Linear(512, outDim)
def forward(self, x):
x = self.fc1(x)
x = self.relu1(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.relu2(x)
x = self.drop2(x)
x = self.fc3(x)
x = self.relu3(x)
x = self.fc4(x)
if len(x.size()) > 1:
return x.squeeze(1)
else:
return x
三 : 训练和评估
这部分和之前几乎一样 。我就不放代码了 可以去git下
undefined
四:main函数和训练过程
超参和模型设置 以及创造loader
def seed_everything(seed=1):
'''
设置整个开发环境的seed
:param seed:
:param device:
:return:
'''
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# some cudnn methods can be random even after fixing the seed
# unless you tell it to be deterministic
torch.backends.cudnn.deterministic = True
#################################################################
batch_size = 512
learning_rate = 1e-4
seed_everything(1)
epoch = 1000
w = 0.00001
device = 'cuda:1' if torch.cuda.is_available() else 'cpu'
##################################################################
dataPath = 'timit_11'
savePath = 'model_save/My'
trainloader, valloader = getDataLoader(dataPath, 'train', batchSize=batch_size)
test_loader = getDataLoader(dataPath, 'test', batchSize=batch_size)
optimizer = optim.SGD(model.parameters() , lr=learning_rate, weight_decay=0.0001,momentum=0.9)
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, eta_min=1e-9, T_0=20)
criterion = nn.CrossEntropyLoss()
创造优化器和loss 然后训练
train_val(model,trainloader,valloader, optimizer=optimizer ,scheduler=scheduler, loss= criterion, epoch=epoch, device=device, save_=savePath)
1 训练过程中 会发现训练集的准确率比测试集还高。 这是因为我们有drop过程。
2 验证准确度会与drop率有关 大家不要迷信准确率。 最后我上面这个模型验证准确在百分之88.5左右就上不去了 。我是训练了 1000个epoch。
3 换了好几个优化器 换了好几个lr 最后结果总是上不去, 然后上传到kaggle 上 得到的分数是 0.741

五 后处理 。
很早就得到了这个结果 却差别人一大截。 然后在网上找到了一个大佬做的视频。 【ML2021李宏毅机器学习】作业2 TIMIT phoneme classification 思路讲解_哔哩哔哩_bilibili
然后跟着大佬的思路 (抄他的代码),把结果提了两个点。 然后我来尽量讲一下这个思路 。 实在是太难了 。这个思路就是HMM, hmm是什么 大家可以参考这里。记得跟着这个链接里的算一次。就算没看懂,也要把他是怎么算出结果的。用手把步骤写出来、下面我尽量带大家理解我的想法。好吧 我也不确定我的想法对。
其实hmm感觉上是什么呢 ? 就感觉是天下大势和小家之势的相互关系。 天下有大势,当你实力强时,你就可以不完全被大势挟裹,但是如果你实力微弱,就会被卷入其中。
后处理的代码如下。这串代码非常的难看懂。一定要仔细调试并与上面的例子结合起来看。
1 加载训练标签。
alllength = 451552
#transition matrix
data_root = 'timit_11/train_label_11.npy'
train_label = np.load(data_root)
print('size of train data:{}'.format(train_label.shape))
trans_table = np.zeros((39,39))
train_label = train_label.astype('int')
2 统计转移矩阵。 trains_table[i,j]位置的元素 表示在所有标签里,从i到j的个数。统计后,在每行进行归一化, 就得到从当现在的标签是i 他下一个是其他标签各个的概率。
for i in range(len(train_label)-1):
trans_table[train_label[i], train_label[i+1]] += 1
trans_table_norm = trans_table/ np.sum(trans_table,axis=1,keepdims=True)
3:得到发射矩阵。 这就是小家小势了 。也就是模型预测的置信度多高。如果你模型预测一个结果的置信度是0.99 那么相信天下大势也很难影响你。test_ln_softmax有451552行 每行都是每一类的预测概率。
m = nn.Softmax(dim=1)
test_ln_softmax = m(torch.tensor(raw_output))
test_ln_softmax = np.array((test_ln_softmax))
4:将他们log化 这里应该是为了乘起来快一点。 大家都知道 log的加就相等于数字相乘。反正我们只是比较相对大小。所以这里log后可以用加法代替乘法。
trans_table_norm += 1e-17
trans_table_norm = np.log(trans_table_norm)
test_ln_softmax = test_ln_softmax + 1e-17
test_ln_softmax = np.log(test_ln_softmax)
5: 定义路径和初始状态。
tracking = np.zeros((alllength, 39))
last_state = test_ln_softmax[0]
6: 计算过程 开始计算了 。
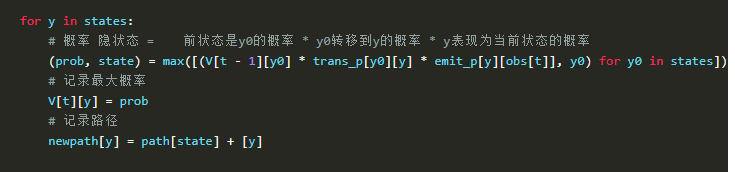
prob = last_state.reshape(39,1) + trans_table_norm + test_ln_softmax[i]
这一句相当于上面例子里的这一段。前一个是y0的概率然后乘以从y0转到yi的概率 再乘以现在这个表现为yi的概率。 我们就得到了在前一个表现为y0的情况下,这个表现为yi的概率。 我们会得到39个。我们来细看 这一句到底是怎么算的。
laststate 就是前面一天 表现为yi的概率 。 长度是39 代表了每一类。但是这里有 reshape(39,1) 就表示变成了39行。 transtabnle是一个39乘以39的矩阵。这两个矩阵相加,就要对latestate进行行扩充。 下面的0 就表示 预测值为0的概率。
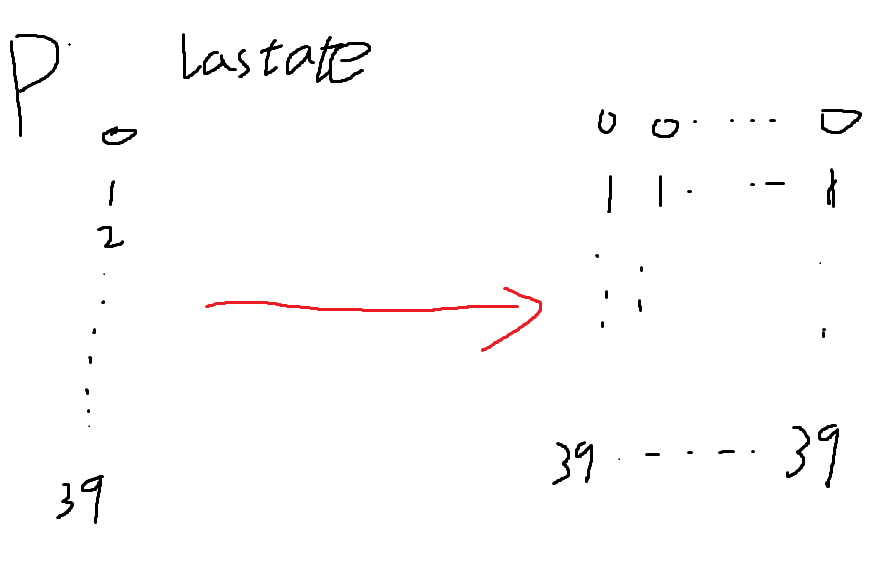
再看 下面两个的相加 我们知道 其实就是相乘 tran的每个位置i,j都是i到j的概率。那么 相加之后的矩阵意思就是 如果上一天是yi 今天表现为yj的概率。

test_ln_softmax[i] 是一个139长的向量 他每个位置意思是不管天下大势 我表现为 y?的概率 。由于他要和3939的矩阵相加 所以他也要扩充。
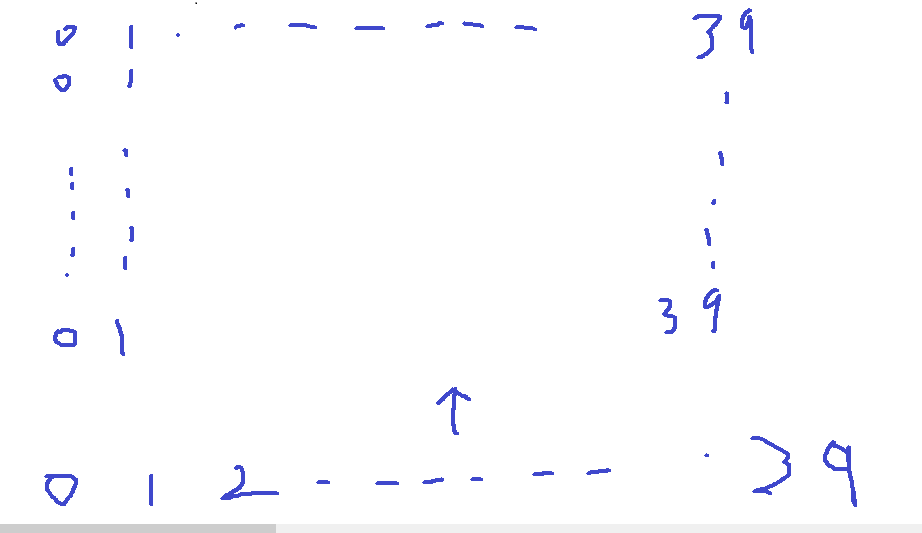

所以这三个矩阵相加 i,j位置的值 就表示 综合了天下大势和小家局势。 后 前一天是i今天是j的概率。
current_state = np.max(prob, axis=0)
取列的最大值。 那么固定的是j的值 如果j=0 就是意思找 昨天预测值是多少时 今天能得到0的概率最高。 此时那个概率的值时多少。 但找齐每一列后 current_state(1,39) 中每一个值的意思就变成了 这天得到预测值j的概率是多大。(我们把最大的那个,选择相信他。)
tracking[i] = np.argmax(prob, axis=0)
列最大值所在行是哪一行。 这个就是位置了。 第j个位置的数字表明 昨天取预测值track【j】时, 今天得到预测值j的概率最大。 也就是统计一个路径。
last_state = current_state
更新状态。也就是把今天概率看成上一天的概率,看下一天。
pred_ls = [np.argmax(raw_output[-1])]
for i in range(0,alllength-1):
back = tracking[alllength-i-1][int(pred_ls[-1])]
pred_ls.append(int(back))
track 是一个 长451551 宽39的矩阵。 有45万行 表示45万天 然后有39 列 第j表示 昨天取预测值track【j】时, 今天得到预测值j的概率最大。
我们选择最后一天的那个数字 带入。 这个数字 就是最后一天的发射值。比如这个值是38(正常大家得到的值应该是25) 我们就要去找 38位的值 发现这一位上还是38 那么意思就是 昨天取38时 今天取38的概率最大。 所以预测值里就要加入38 但这里我们是倒序加入,最后要反过来。
到这里 发现38位上写的 7 说明上天是7 今天取38概率最大。然后找到上天的7 继续这个步骤 。
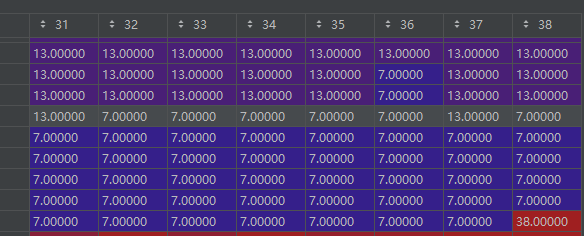

也就是说 按照track这条路去走 是最有可能的 。 所以就取这条路提交。 得到最后的结果。hmm后会比正常提交提高两个百分点左右。
而hmm那个晴天阴天的例子 用第一天的转移用 上面的 代码大概就是 下面这样
import numpy as np
a = np.array([0.06,0.24])
b = np.array([[0.7,0.3],[0.4,0.6]])
c = np.array([0.4,0.3])
print(a.reshape(2,1)*b*c)
Original: https://blog.csdn.net/YI_SHU_JIA/article/details/123576414
Author: 亮子李
Title: hw-2 李宏毅2022年作业2 phoneme识别 单strong-hmm详细解释。
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/760845/
转载文章受原作者版权保护。转载请注明原作者出处!