

Python学习笔记#1:使用genfromtxt读取txt中数据
1. 语法:
numpy.genfromtxt(fname, dtype=
从文本文件加载数据,缺失值按指定处理。
前 skip_header 行之后的每一行都在分隔符处拆分,注释字符之后的字符将被丢弃。
2. 参数:
fname: 文件、str、pathlib.Path、str 列表、生成器
要读取的文件、文件名、列表或生成器。如果文件扩展名是 .gz 或 .bz2 ,则首先解压缩文件。请注意,生成器必须返回字节或字符串。列表中的字符串或由生成器生成的字符串被视为行。
dtype: dtype,可选
结果数组的数据类型。如果为 None,则 dtypes 将由每列的内容单独确定。
comments: str,可选
用于指示注释开始的字符。注释后一行上出现的所有字符都将被丢弃。
delimiter: str、int 或序列,可选
用于分隔值的字符串。默认情况下,任何连续的空格都充当分隔符。也可以提供整数或整数序列作为每个字段的宽度。
skiprows: 整数,可选
在 numpy 1.10 中删除了 skiprows。请改用skip_header。
skip_header: 整数,可选
在文件开头要跳过的行数。
skip_footer: 整数,可选
在文件末尾要跳过的行数。
converters: 可变的,可选的
将列的数据转换为值的一组函数。转换器还可用于为缺失数据提供默认值:converters = {3:lambda s:float(s or 0)}。
missing: 可变的,可选的
在 numpy 1.10 中删除了缺失。请改用missing_values。
missing_values: 可变的,可选的
对应于缺失数据的字符串集。
filling_values: 可变的,可选的
缺少数据时用作默认值的一组值。
usecols: 顺序,可选
要读取的列,0 是第一个。例如,usecols = (1, 4, 5) 将提取第 2、第 5 和第 6 列。
names: {无,真,str,序列},可选
如果 names 为 True,则从前 skip_header 行之后的第一行读取字段名称。此行之前可以有选择地使用注释分隔符。如果名称是逗号分隔名称的序列或single-string,则名称将用于定义结构化数据类型中的字段名称。如果名称为无,则将使用 dtype 字段的名称(如果有)。
excludelist: 顺序,可选
要排除的名称列表。此列表附加到默认列表 [‘return’,’file’,’print’]。排除的名称后附下划线:例如,file 将变为 file_。
deletechars: str,可选
组合了必须从名称中删除的无效字符的字符串。
defaultfmt: str,可选
用于定义默认字段名称的格式,例如 “f%i” 或 “f_%02i”。
autostrip: 布尔型,可选
是否自动从变量中去除空格。
replace_space: 字符,可选
用于替换变量名中的空格的字符。默认情况下,使用’_’。
case_sensitive: {真,假,’upper’, ‘lower’},可选
如果为 True,则字段名称区分大小写。如果为 False 或 ‘upper’,则字段名称将转换为大写。如果’lower’,字段名称将转换为小写。
unpack: 布尔型,可选
如果为 True,则返回的数组被转置,以便可以使用 x, y, z = genfromtxt(…) 解包参数。当与结构化数据类型一起使用时,将为每个字段返回数组。默认为假。
usemask: 布尔型,可选
如果为 True,则返回一个掩码数组。如果为 False,则返回一个常规数组。
loose: 布尔型,可选
如果为 True,则不要为无效值引发错误。
invalid_raise: 布尔型,可选
如果为 True,如果在列数中检测到不一致,则会引发异常。如果为 False,则会发出警告并跳过有问题的行。
max_rows: 整数,可选
要读取的最大行数。不得与skip_footer 同时使用。如果给定,该值必须至少为 1。默认是读取整个文件。
encoding: str,可选
用于解码输入文件的编码。当 fname 是文件对象时不适用。特殊值 ‘bytes’ 启用向后兼容解决方法,确保您在可能的情况下接收字节数组并将 latin1 编码的字符串传递给转换器。覆盖此值以接收 unicode 数组并将字符串作为输入传递给转换器。如果设置为无,则使用系统默认值。默认值为’bytes’。
like: array_like
引用对象以允许创建不是 NumPy 数组的数组。如果作为like 传入的array-like 支持__array_function__ 协议,则结果将由它定义。在这种情况下,它确保创建一个与通过此参数传入的对象兼容的数组对象。
3. 实例
txt文件:(test.in)
a b c d e f
1 2 3 4 5 6
2 3 4 5 6 7
3 4 5 6 7 8
4 5 6 7 8 9
5 6 7 8 9 0
6 7 8 9 0 1
7 8 9 0 1 2
8 9 0 1 2 3
9 0 1 2 3 4
0 1 2 3 4 5
程序:
test.py
!/usr/bin/env python3
# – – coding: utf-8 ––
import numpy as np
data = np.genfromtxt(‘test.in’, delimiter = ”, names=True)
print(data.dtype.names)
print(data)
a = data[‘a’]
b = data[‘b’]
c = data[‘c’]
d = data[‘d’]
e = data[‘e’]
f = data[‘f’]
print(a)
sel_ns=[(a>1)
& (b>1)
& (c>1)
& (d>1)
& (e>1)
& (f>1)
]
print(sel_ns)
a_f = a[tuple(sel_ns)]
print(a_f)
运行结果:
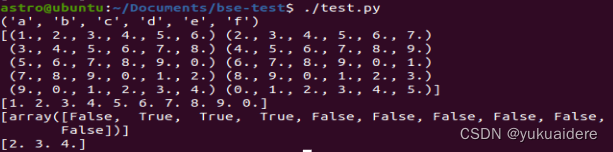

从运行结果可以清晰地分析出genfromtxt的用法。
Original: https://blog.csdn.net/yukuaidere/article/details/126837978
Author: yukuaidere
Title: Python学习笔记#1:使用genfromtxt读取txt中数据
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/759854/
转载文章受原作者版权保护。转载请注明原作者出处!