

@
OC
分享****一种提取不同文件中特定的列并将该列依次添加到新的列表中的方法
简化代码如下所示
:
import pandas as pd
import numpy as np
df=pd.DataFrame(columns=[‘1′,’2′,’3′,’4′,’5′,’6′,’7′,’8′,’9′,’10’,’11’,’12’,’13’,’14’,’15’,’16’],index=range(16))
for i in range(1,17):
df[str(i)]=pd.DataFrame(columns=[str(i)],data=range(i))
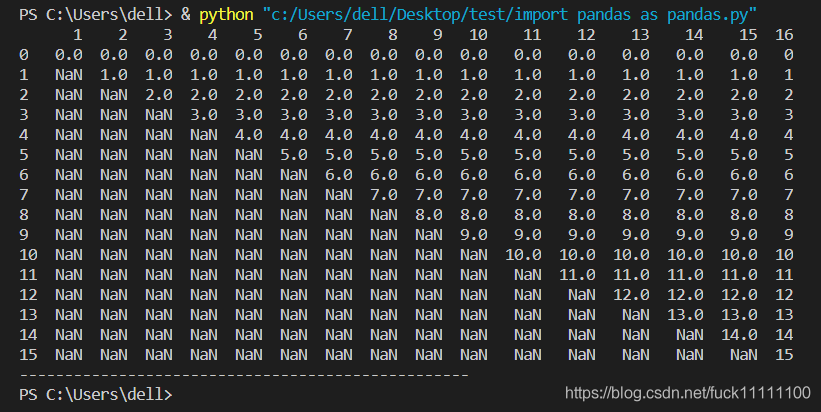
print(df)
显示的结果如下

分段解释
import pandas as pd
import numpy as np
导入需要使用的模块
;
df=pd.DataFrame(columns=[‘1′,’2′,’3′,’4′,’5′,’6′,’7′,’8′,’9′,’10’,’11’,’12’,’13’,’14’,’15’,’16’],index=range(200))
定义一个空列表,定义的方式是只定义列名和行数,定义行数可以根据读取列的最大数取值,如果这里定义的行数小于读取数据的最大行数,那么会有数据丢失的情况
;
for i in range(1,17):
df[str(i)]=pd.DataFrame(columns=[str(i)],data=range(i))
通过for循环来依次将数据添加到我们起初建立的空列表中
;
print(df)
显示列表
可能出现的问题
1
如果不在起初就建立空列表df,在后续使用 df[str(i)]=pd.DataFrame(columns=[str(i)],data=range(i))时会出现
NameError: name ‘df’ is not defined,我们可能想着是本句代码就可以直接顺带定义df的列表类型,其实,本句代码的意思是’range(i)’中的数存放到列表df中列名为’str(i)’的列中,就如同你拿着range(i)这列数据,但是放的时候才发现没有准备好得到盒子,
显示的结果如下:

如果df定义的行数少与数据行数,那就是放的时候才发现数据多放不下,这样默认只放先放进入的,后面放不进去的丢掉;
例如,当定义index=range(5)时,我们将原始的df和赋值后的df都打印出来对比
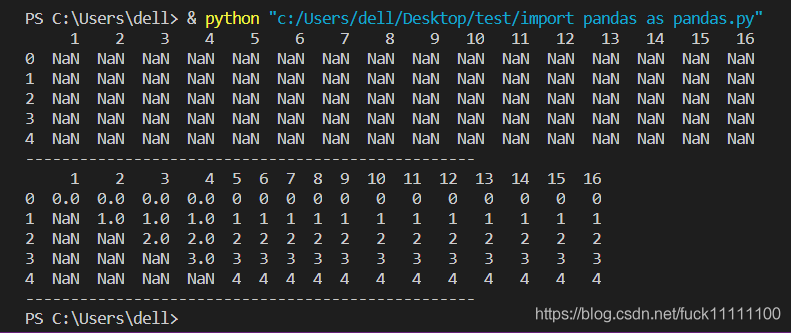
可以发现,空列表df里面均是NaN,即为not a number;而赋值后,列表由于df行数只有5行,多余的数据未实现保存,因此呈现上图的样子;
2
在起初未建立空列表df的情况下,代码写为
for i in range(1,17):
df=pd.DataFrame(columns=[str(i)],data=range(i))
这时,打印出来的df是最后赋值到df中的range(17),并不能完成依次存入的功能,而是每次数据的覆盖,最后留下的 就是最后放入的;
显示的结果如下:
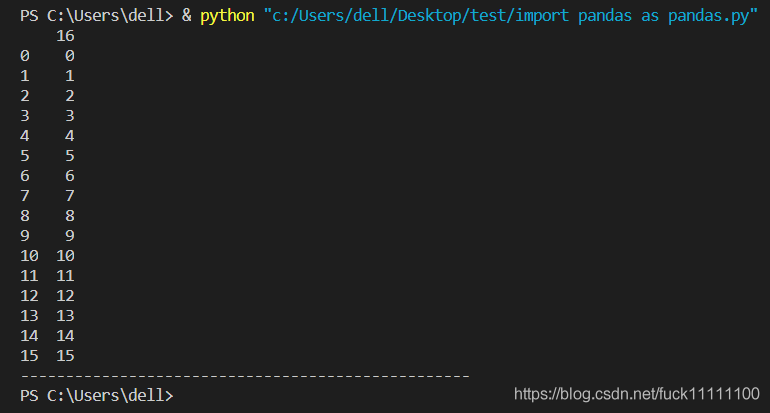
3
在代码
df=pd.DataFrame(columns=[‘1′,’2′,’3′,’4′,’5′,’6′,’7′,’8′,’9′,’10’,’11’,’12’,’13’,’14’,’15’,’16’],index=range(16))
中,可以使用index=range(16)来定义行数;
4
注意防止for后冒号的丢失以及正确的缩进;
Original: https://blog.csdn.net/weixin_33375038/article/details/113979723
Author: 猫盟CFCA
Title: python对表格的操作提取_Python如何将提取的列表逐列添加到新表中,python,取出,表格…
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/754070/
转载文章受原作者版权保护。转载请注明原作者出处!