

pandas上
- 1 什么是Pandas
- 2 Series
* - (1)Series对象的创建与类型
- (2)修改类型
- (2)取值
- (3)索引
- (4)索引和值
- (5)unique()的功能
- 2 查看pandas的官方文档
* - (1) 百度 pandas series where
- (2) 翻到下面找到实例
- 3 DataFrame
* - (1)DataFrame对象的创建
– - (2)DataFrame的基本属性与查询情况
- (3)通过位置取切片、值
– - (4)通过df.loc和df.iloc取切片和值
– - (5)DataFrame的值的修改
- (5)DataFrame字符串方法
- (7)缺失数据处理
– - (8)布尔索引
- (9)排序
- (10)常用统计方法
- (11)apply与applymap
- (12)练习
1 什么是Pandas
pandas是一种高性能、易于使用的数据结构和数据分析工具,其有两种主要数据类型:
Series 一维,带标签数组
DataFrame 二维,Series容器
2 Series
(1)Series对象的创建与类型
未指定索引,索引就是0,1,2,3,4……
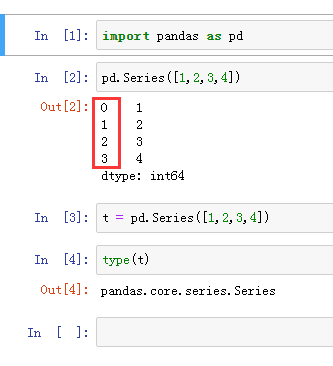

指定索引
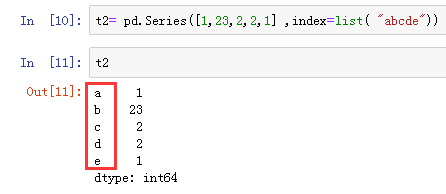
通过字典创建一个Series,此时字典的键就是索引

dtype(‘0’)表示object类型
; (2)修改类型

(2)取值
Series对象可以根据键取值,也可以根据位置取值,其实本质都是根据索引取值

; (3)索引

(4)索引和值

; (5)unique()的功能
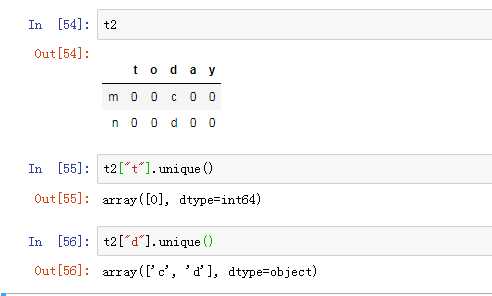
unique()相当于集合操作,即去掉重复,只有Series对象才能调用,DataFrame不行
2 查看pandas的官方文档
以series的where为例
(1) 百度 pandas series where
点击第一个

; (2) 翻到下面找到实例

3 DataFrame
Series对象是一维的,如果数据是二维的,该怎么办?
此时可以使用DataFrame(数据框)来处理,DataFrame是Series的容器。
(1)DataFrame对象的创建
a 通过读取表格创建,行索引与列索引
使用pd.read_csv()方法可以读取数据
import pandas as pd
df = pd.read_csv("./dogNames2.csv")
print(df)
print(type(df))
输出
Row_Labels Count_AnimalName
0 RENNY 1
1 DEEDEE 2
2 GLADIATOR 1
3 NESTLE 1
4 NYKE 1
... ... ...
4159 ALEXXEE 1
4160 HOLLYWOOD 1
4161 JANGO 2
4162 SUSHI MAE 1
4163 GHOST 3
[4164 rows x 2 columns]
<class 'pandas.core.frame.DataFrame'>
0 1 2 …这些都是行索引,Row_Labels和Count_AnimalName则为列索引
DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
b 通过读取JSON文件创建
大数据集通常存储到JSON文件中,或者从JSON文件中读取。

使用 read_json()方法读取
; b 通过字典或列表创建
字典里面嵌列表(以列表为值)

列表里面嵌字典,每一条记录以字典的形式作为列表的一个元素,即列表里有多个字典,每个字典只记录一条数据

如果某些字段有缺失,则系统自动用NaN 代替,NaN类似于np.nan
c 通过numpy对象创建列表
import pandas as pd
import numpy as np
t = pd.DataFrame(np.arange(12).reshape((2,6)))
print(t)
print(type(t))
输出
0 1 2 3 4 5
0 0 1 2 3 4 5
1 6 7 8 9 10 11
<class 'pandas.core.frame.DataFrame'>
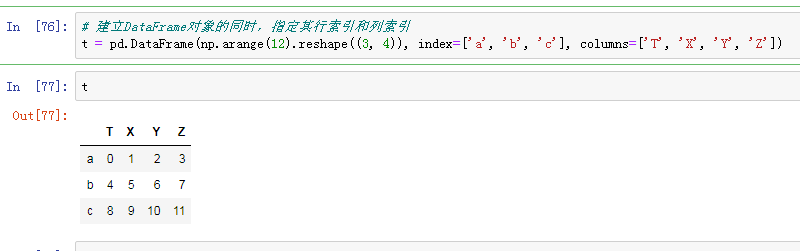
也可以在建立DataFrame对象的同时,指定其行索引和列索引
(2)DataFrame的基本属性与查询情况
和一个ndarray一样,我们通过shape,ndim,dtype了解这个ndarray的基本信息

df.head(3)和df.tail(3)返回的类型并不为Series,而是DataFrame,df.describe只有对数值型(int、float)的字段有效
import pandas as pd
data = pd.read_csv("datasets_IMDB-Movie-Data.csv")
print(data.info())
输出

可以看到,数据公有12个字段,前10个字段都有1000个数据,最后两个不到1000,因此最后两个字段有缺失。
(3)通过位置取切片、值
a 取行(不要求掌握)
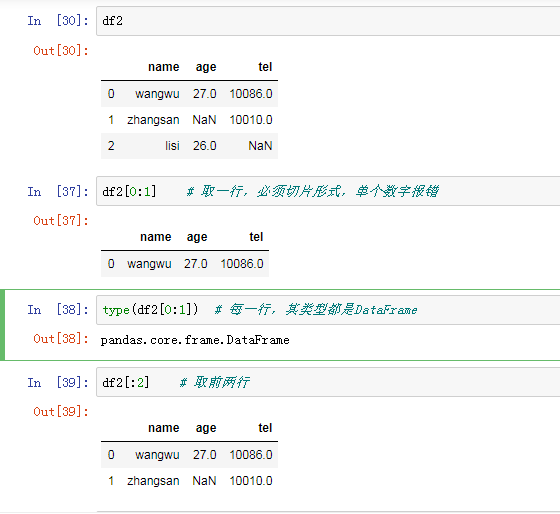
; b 取列
方括号里面是字段

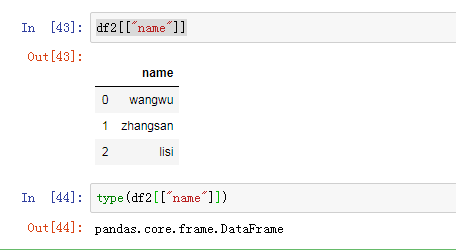
取DataFrame的一列,若是一对方括号,则其类型是Series,若是两对方括号,则其类型为DataFrame

c 取值(不要求掌握)

; (4)通过df.loc和df.iloc取切片和值
a df.loc 通过标签索引取数据
df.loc[行标签,列标签]


取某个具体位置的值,结果可能是字符串型,也可能是numpy的数值型
; b df.iloc 通过位置获取行数据


同df.loc相似,切片也是闭合型的。
如果取行,则t.iloc[2:,],列位置处的冒号可以省略,但如果取列,那么行位置处的冒号不能省略


无论df.loc还是df.iloc,取某个具体位置的值,结果可能是字符串型,也可能是numpy的数值型,去某一行或某一列,则是Series对象,取不同行列的多个值,则是DataFrame对象。
(5)DataFrame的值的修改

可以直接对pandas的某个元素直接复制np.nan,如果是numpy对象,则需要先该数据类型为浮点型
; (5)DataFrame字符串方法

先将DataFrame对象中的字符串列筛选出来,然后 .str.方法名(…),返回的结果是Series。
例如
import pandas as pd
import numpy as np
df = pd.read_csv("./dogNames2.csv")
print(df.head(10))
print(50*'*')
df2 = df["Row_Labels"].str.lower()
print(df2.head(10))
输出
Row_Labels Count_AnimalName
0 RENNY 1
1 DEEDEE 2
2 GLADIATOR 1
3 NESTLE 1
4 NYKE 1
5 BABY GIRL 3
6 EVVIE 1
7 AMADEUS 1
8 FINLEY 4
9 C.C. 1
**************************************************
0 renny
1 deedee
2 gladiator
3 nestle
4 nyke
5 baby girl
6 evvie
7 amadeus
8 finley
9 c.c.
Name: Row_Labels, dtype: object
(7)缺失数据处理
a 判断数据是否为NaN:pd.isnull(df),pd.notnull(df)
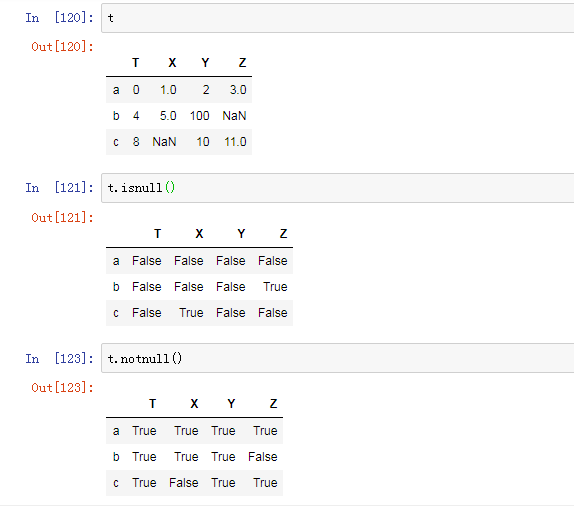
; b NaN的处理
处理方式1:删除NaN所在的行列dropna (axis=0, inplace=False),inplace表示原地修改,不生成新对象
t = pd.DataFrame({'T':[0, 4, 8], 'X':[1.0, 5.0, np.nan], 'Y':[2, 6, 10], 'Z':[3.0, np.nan, 11.0]})
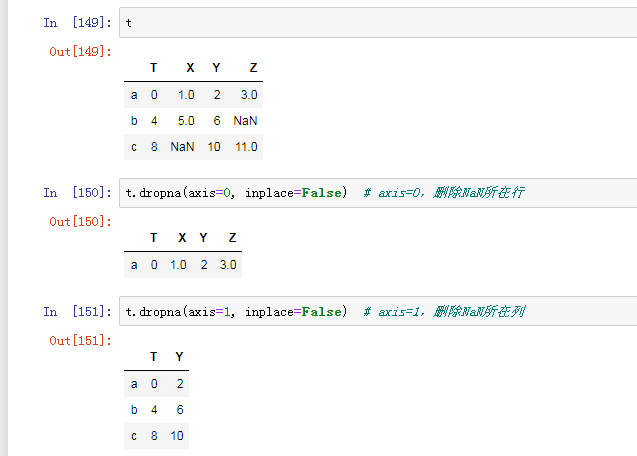
如果不加参数,则删除NaN所在的行

处理方式2:填充数据,t.fillna(t.mean()),填充均值,t.fillna(t.median()),填充中位数,t.fillna(0)填充0
t.mean(),t.median()是对列求均值和中位数,是除NaN之外的值的均值和中位数


(8)布尔索引
回到之前狗的名字的问题上,假如我们想找到所有的使用次数超过700并且名字的字符串的长度大于4的狗的名字,应该怎么选择?
直接在中括号中添加条件,&表示且,|表示或

例如
import pandas as pd
import numpy as np
file_path = "datasets_IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
print(df["Year"]==2015)
输出
0 False
1 False
2 False
3 False
4 False
...
995 True
996 False
997 False
998 False
999 False
Name: Year, Length: 1000, dtype: bool
df[“Year”]==2015返回的是一个以逻辑值构成的Series对象。
中括号里如果是由逻辑值组成的Series对象,那么就是对行进行筛选

但中括号里不能直接用逻辑值,而是应该用Series对象,否则会报错
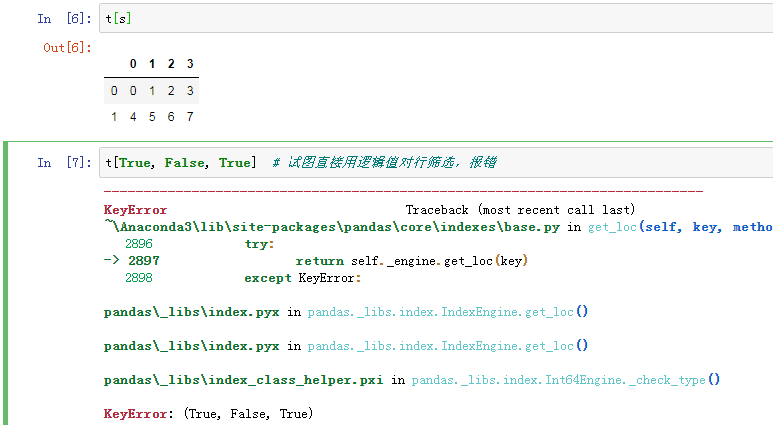
(9)排序
df.sort_values(by="Count_AnimalName",ascending=True)
不止DataFrame,Series对象也能调用这个方法,Series调用这个方法时不需要by
Count_AnimalName是排序所依据的字段
ascending表示是否升序,默认为True
(10)常用统计方法
除了刚刚介绍的df.mean(),df.median(),还有df.max(),df.min(),同样是统计每个字段的

还可以使用df.idxmax和df.idxmin返回最大最小值所在的行索引

df.idxmax和df.idxmin返回的是Series对象

老版本的pandas是通过ser.argmax和ser.argmin来实现这种功能,但是这两种方法只能被Series对象调用,不能被DataFrame对象调用,即必须先对DataFrame对象先去行或列。
; (11)apply与applymap



(12)练习
假设现在我们有一组从2006年到2016年1000部最流行的电影数据,我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
import pandas as pd
import numpy as np
file_path = "datasets_IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
print(df.head(1))
print(80 * '*')
print(df["Rating"].mean())
print(80 * '*')
print(len(set(df["Director"].tolist())))
输出
Rank Title ... Revenue (Millions) Metascore
0 1 Guardians of the Galaxy ... 333.13 76.0
[1 rows x 12 columns]
********************************************************************************
6.723199999999999
********************************************************************************
644
假如要统计这1000部电影的参演演员总数,则代码为
import pandas as pd
file_path = "datasets_IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
temp_actors_list = df["Actors"].str.split(", ").tolist()
actors_list = [i for j in temp_actors_list for i in j]
actors_num = len(set(actors_list))
print(actors_num)
输出
2015
actors_list = [i for j in temp_actors_list for i in j]可能比较难读懂,这是两个循环嵌套,看下面代码的注释,就能明白
import pandas as pd
file_path = "datasets_IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
print(df["Actors"].str.split(", "))
print(80 * '*')
print(type(df["Actors"].str.split(", ")))
print(80 * '*')
temp_actors_list = df["Actors"].str.split(", ").tolist()
actors_list = [i for j in temp_actors_list for i in j]
actors_num = len(set(actors_list))
print(actors_num)
输出:
0 [Chris Pratt, Vin Diesel, Bradley Cooper, Zoe ...
1 [Noomi Rapace, Logan Marshall-Green, Michael F...
2 [James McAvoy, Anya Taylor-Joy, Haley Lu Richa...
3 [Matthew McConaughey,Reese Witherspoon, Seth M...
4 [Will Smith, Jared Leto, Margot Robbie, Viola ...
...
995 [Chiwetel Ejiofor, Nicole Kidman, Julia Robert...
996 [Lauren German, Heather Matarazzo, Bijou Phill...
997 [Robert Hoffman, Briana Evigan, Cassie Ventura...
998 [Adam Pally, T.J. Miller, Thomas Middleditch,S...
999 [Kevin Spacey, Jennifer Garner, Robbie Amell,C...
Name: Actors, Length: 1000, dtype: object
********************************************************************************
<class 'pandas.core.series.Series'>
********************************************************************************
2015
Original: https://blog.csdn.net/weixin_44457930/article/details/114707669
Author: weixin_44457930
Title: pandas上
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/753483/
转载文章受原作者版权保护。转载请注明原作者出处!