

前言
利用Python实现抓取腾讯视频弹幕,废话不多说。
让我们愉快地开始吧~
开发工具
Python版本: 3.6.4
相关模块:
requests模块;
pandas模块
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
思路分析
本文以爬取电影《革命者》为例,讲解如何爬取腾讯视频的弹幕和评论!
目标网址
https://v.qq.com/x/cover/mzc00200m72fcup.html
抓取弹幕
分析网址
依然进入浏览器的开发者工具进行抓包,当视频播放30秒它就会更新一个json数据包,里面包含我们需要的弹幕数据。
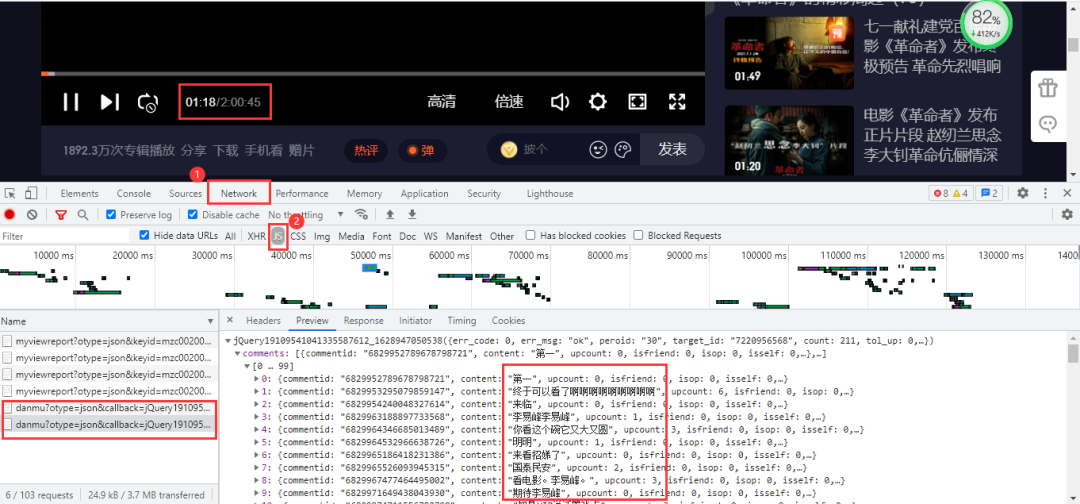

得到准确的URL:
https://mfm.video.qq.com/danmu?otype=json&callback=jQuery19109541041335587612_1628947050538&target_id=7220956568%26vid%3Dt0040z3o3la&session_key=0%2C32%2C1628947057×tamp=15&_=1628947050569\
https://mfm.video.qq.com/danmu?otype=json&callback=jQuery19109541041335587612_1628947050538&target_id=7220956568%26vid%3Dt0040z3o3la&session_key=0%2C32%2C1628947057×tamp=45&_=1628947050572
其中有差别的参数有 timestamp和 _。_是时间戳。timestamp是页数,首条url为15,后面以公差为30递增,公差是以数据包更新时长为基准,而最大页数为视频时长7245秒。依然删除不必要参数,得到URL:
https://mfm.video.qq.com/danmu?otype=json&target_id=7220956568%26vid%3Dt0040z3o3la&session_key=0%2C18%2C1628418094×tamp=15&_=1628418086509
代码实现
import pandas as pd\
import time\
import requests\
\
headers = {\
'User-Agent': 'Googlebot'\
}\
df = pd.DataFrame()\
for i in range(15, 7245, 30):\
url = "https://mfm.video.qq.com/danmu?otype=json&target_id=7220956568%26vid%3Dt0040z3o3la&session_key=0%2C18%2C1628418094×tamp={}&_=1628418086509".format(i)\
html = requests.get(url, headers=headers).json()\
time.sleep(1)\
for i in html['comments']:\
content = i['content']\
print(content)\
text = pd.DataFrame({'弹幕': [content]})\
df = pd.concat([df, text])\
df.to_csv('革命者_弹幕.csv', encoding='utf-8', index=False)
效果展示

抓取评论
网页分析
腾讯视频评论数据在网页底部,依然是动态加载的,需要按下列步骤进入开发者工具进行抓包:
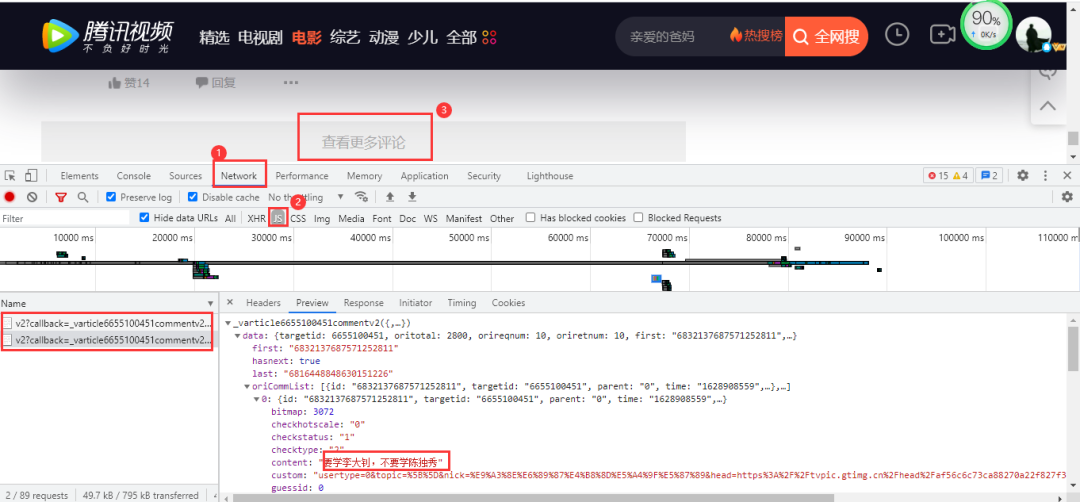
点击查看更多评论后,得到的数据包含有我们需要的评论数据,得到的真实URL:
https://video.coral.qq.com/varticle/6655100451/comment/v2?callback=_varticle6655100451commentv2&orinum=10&oriorder=o&pageflag=1&cursor=0&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1628948867522\
https://video.coral.qq.com/varticle/6655100451/comment/v2?callback=_varticle6655100451commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6786869637356389636&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1628948867523
URL中的参数callback以及_删除即可。重要的是参数 cursor,第一条url参数 cursor是等于0的,第二条url才出现,所以要查找 cursor参数是怎么出现的。经过我的观察, cursor参数其实是上一条url的 last参数:
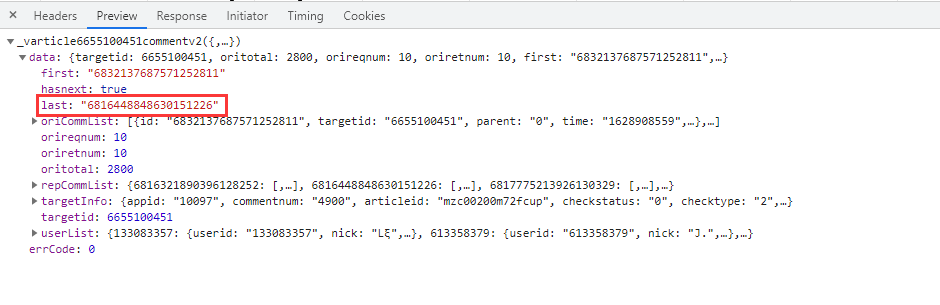
代码实现
import requests\
import pandas as pd\
import time\
import random\
\
headers = {\
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'\
}\
df = pd.DataFrame()\
a = 1\
while a < 281:\
if a == 1:\
url = 'https://video.coral.qq.com/varticle/6655100451/comment/v2?orinum=10&oriorder=o&pageflag=1&cursor=0&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132'\
else:\
url = f'https://video.coral.qq.com/varticle/6655100451/comment/v2?orinum=10&oriorder=o&pageflag=1&cursor={cursor}&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132'\
res = requests.get(url, headers=headers).json()\
cursor = res['data']['last']\
for i in res['data']['oriCommList']:\
ids = i['id']\
times = i['time']\
up = i['up']\
content = i['content'].replace('\n', '')\
text = pd.DataFrame({'ids': [ids], 'times': [times], 'up': [up], 'content': [content]})\
df = pd.concat([df, text])\
a += 1\
time.sleep(random.uniform(2, 3))\
df.to_csv('革命者_评论.csv', encoding='utf-8', index=False)
~完整代码私信获取
效果展示

Original: https://blog.csdn.net/weixin_43649691/article/details/121138546
Author: 小雁子学Python
Title: Python爬虫实战,requests模块,Python实现抓取腾讯视频弹幕评论
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/752699/
转载文章受原作者版权保护。转载请注明原作者出处!