

Excel的vlookup功能在数据量太大的前提下就挺难用的,所以还是需要pandas搞定
下面是用pandas实现匹配的方法
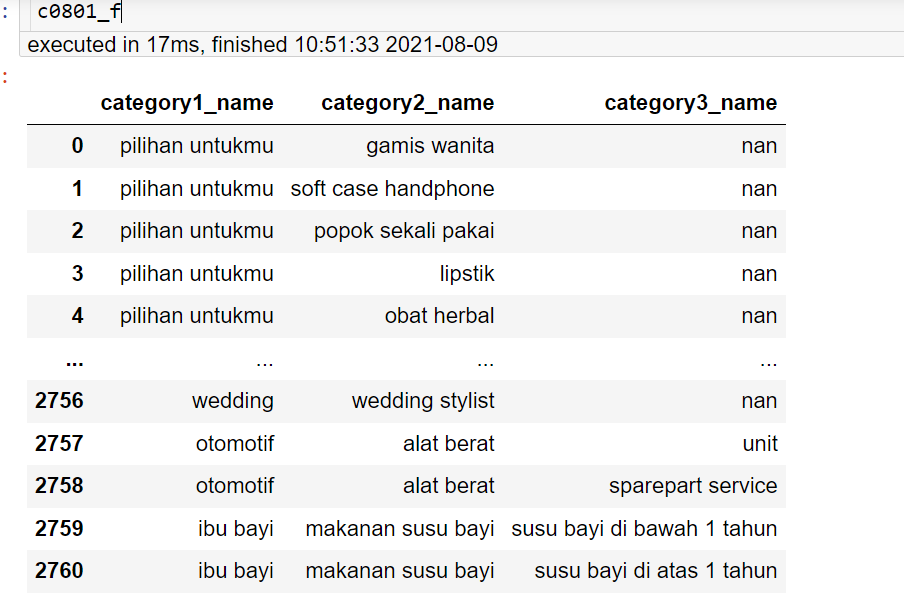
如下图,假如我有一个表 全是印尼文 A

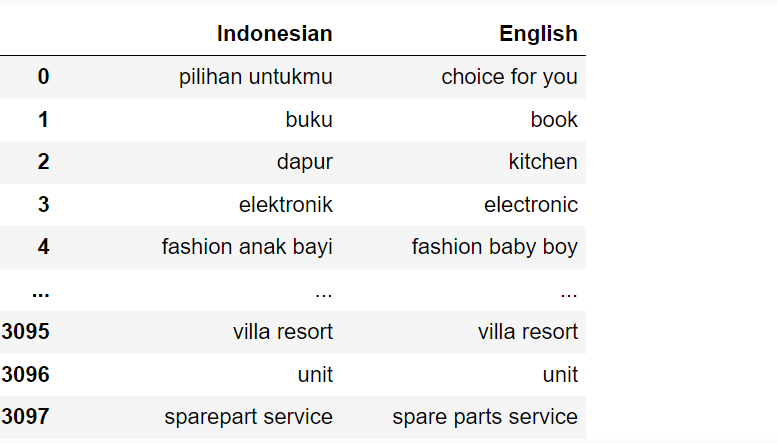
有另一张在google sheet上翻译出来的表 B
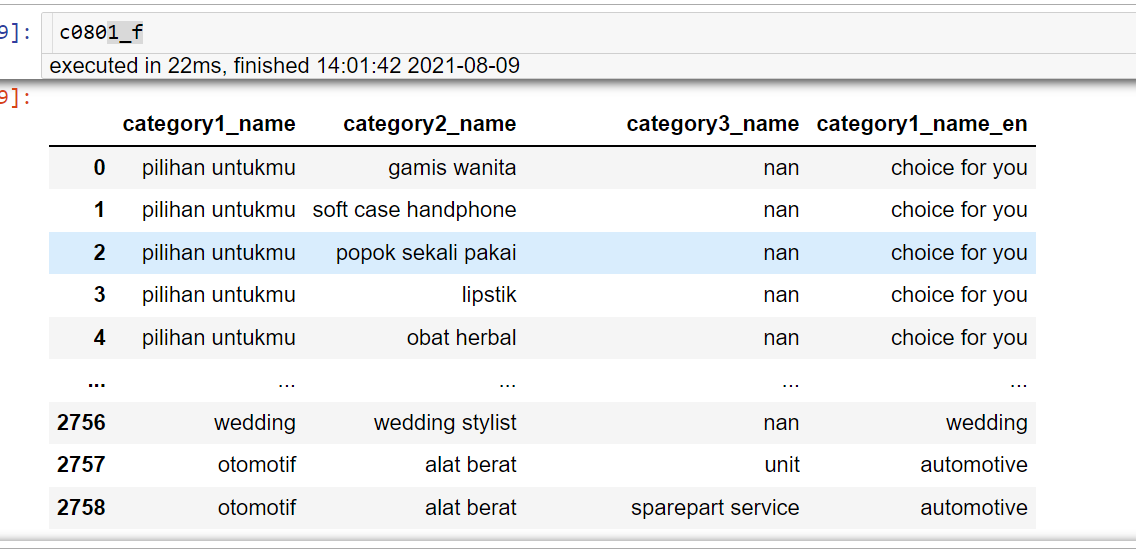
现在我想匹配第一张表 category1_name 的英文版本
1. dict + apply 我觉得最好的方法
首先将翻译的那张表转成字典形式
import pandas as pd
dict1 = dict(zip(trans['Indonesian'],trans['English']))

然后直接用apply函数映射过去
c0801_f['category1_name_en'] = c0801_f['category1_name'].apply(lambda x: dict1[x])
如果你的表因为找不到对应的值而报错,可以用get调用方法,则找不到的值默认None
c0801_f['category1_name_en'] = c0801_f['category1_name'].apply(lambda x: dict1.get(x))
完成
而且这样还可以随意apply到任何列上,很方便~
2. merge
还是刚刚那两张表
但是我得把翻译表第一列换成和表A一样的名字,不然不能merge
然后按照表A left merge
trans = trans.rename(columns={'Indonesian':'category1_name'})
c0801_f = c0801_f.merge(trans,on='category1_name',how='left')
最后也是一样的结果
3. join
还是这两张表
pandas 的 join 官方文档上有一个例子,写了这两句话
If we want to join using the key columns, we need to set key to be the index in both df and other. The joined DataFrame will have key as its index.
Another option to join using the key columns is to use the on parameter. DataFrame.join always uses other’s index but we can use any column in df. This method preserves the original DataFrame’s index in the result.
也就是说我们可以指定表里的一列为index, 然后根据这列index去join
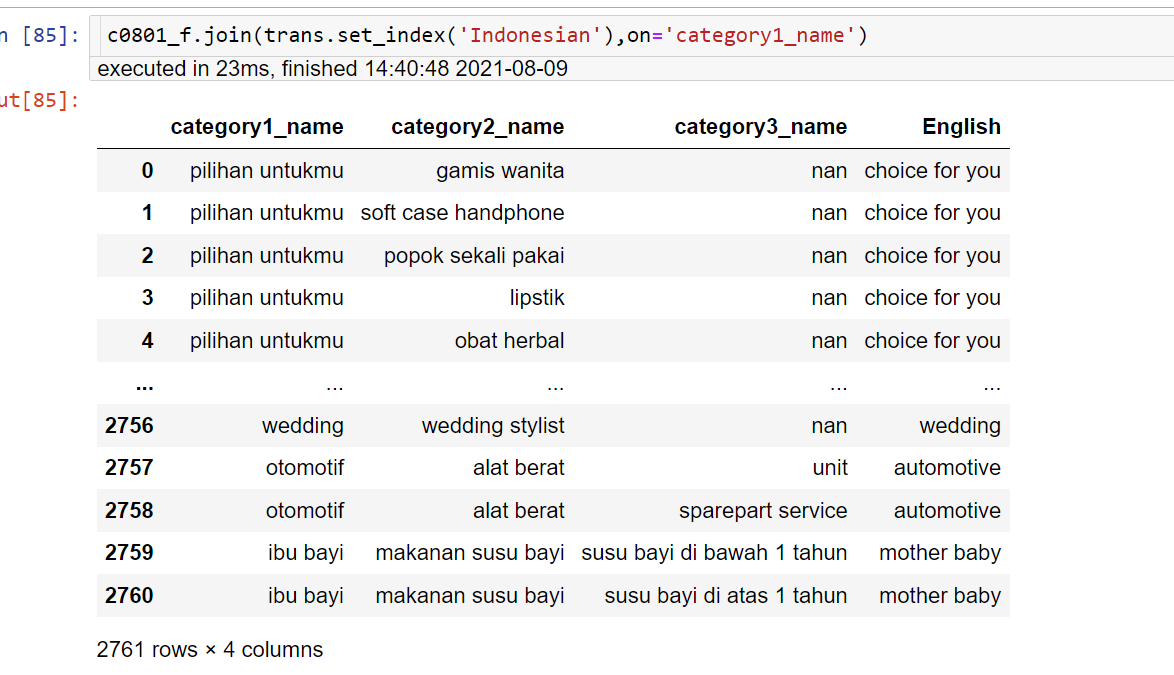
c0801_f.join(trans.set_index('Indonesian'),on='category1_name')
这样就不用给表A改名了hhhhhh
Original: https://blog.csdn.net/EvaHoo/article/details/119537027
Author: 德德德真的是我
Title: Pandas 实现excel类似vlookup 的匹配功能 (apply, merge, join)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/740724/
转载文章受原作者版权保护。转载请注明原作者出处!