

文章目录
- MapReduce 工作原理
* - 一、MapReduce工作过程
- 二、MapTask工作原理
- 三、Reduce Task工作原理
- 四、Shuffle工作原理
- 五、MapReduce编程组件
– - 六、MapReduce运行模式
– - 七、MapReduce性能优化策略
–
MapReduce 工作原理
一、MapReduce工作过程
分片、格式化数据源⟹ Longrightarrow⟹执行MapTask⟹ Longrightarrow⟹执行Shuffle过程⟹ Longrightarrow⟹执行ReduceTask过程⟹Longrightarrow⟹写入文件
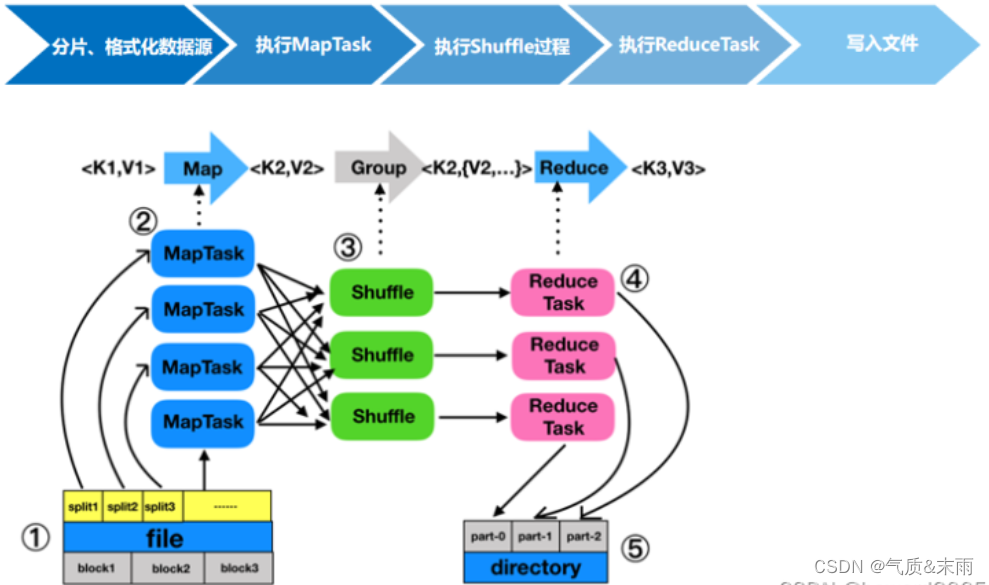

; 二、MapTask工作原理
MapTask作为MapReduce工作流程前半部分,它主要经历5个阶段,分别是Read阶段、Map阶段、Collect阶段、Spill阶段和Combiner阶段。
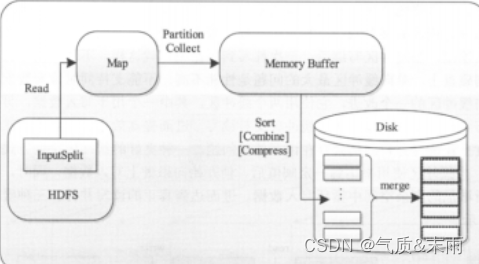
三、Reduce Task工作原理
ReduceTask的工作过程主要经历了5个阶段,分别是Copy阶段、Merge阶段、Sort阶段、Reduce阶段和Write阶段。
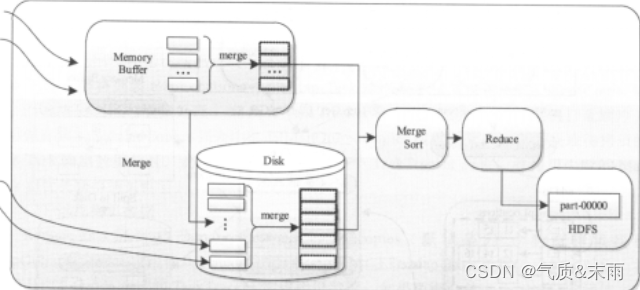
; 四、Shuffle工作原理
Shuffle是MapReduce的核心,它用来确保每个reducer的输入都是按键排序的。它的性能高低直接决定了整个MapReduce程序的性能高低,map和reduce阶段都涉及到了shuffle机制。
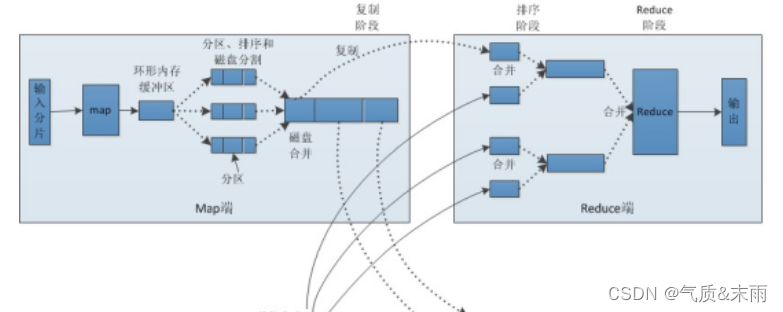
五、MapReduce编程组件
1、inputFormat组件
主要用于描述输入数据的格式,它提供两个功能,分别是数据切分和为Mapper提供输入数据。定义如何读取和分割输入数据。InputFormat是一个类,定义了InputSplit用于把输入数据拆分到任务,并提供RecordReader对象工厂用于读取文件。InputFormat由作业的驱动器直接调用,基于InputSplit来确定map任务执行的数量和位置。

; 2、Mapper组件
Hadoop提供的Mapper类是实现Map任务的一个抽象基类,该基类提供了一个map()方法。mapper执行MapReduce程序第一阶段的用户自定义工作。从实现角度来看,mapper实现以一系列键值对(k1,v1)的形式接收输入数据,这些数据会用于单个map执行。map通常将输入对转换成输出对(k2,v2),后者会被用作洗牌和排序的输入。对于构成总的作业输入的每个map任务而言,mapper的新实例均运行在独立的JVM实例中。这是特意设计,即不为单独的mapper提供以任何方式与其它mapper进行通信的机制。这使得每个map任务的可靠性仅取决于本地机器的可靠性。

3、Reducer组件
Map过程输出的键值对,将由Reducer组件进行合并处理,最终的某种形式的结果输出。reducer负责执行第二阶段作业特定工作的用户提供代码。对于分配给特定reducer的每一个键,reducer的reduce()方法仅被调用一次。该方法接收一个键,以及一个与键关联的所有值的迭代器。迭代器以未定义的顺序返回与键相关的值。典型地,reducer将输入的键值对转换成输出对(k3,v3)。
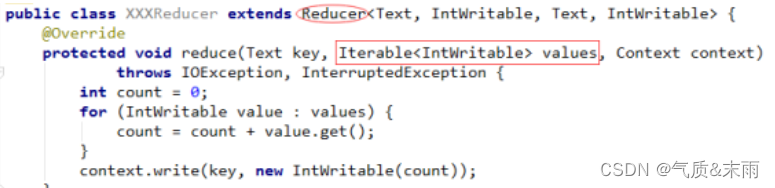
; 4、Partitioner组件
Partitioner组件可以让Map对Key进行分区,从而可以根据不同的key分发到不同的Reduce中去处理,其目的就是将key均匀分布在ReduceTask上。由每个单独mapper产生的中间键空间(k2,v2)的子集会被分配给每个reducer。这些子集(或分区)是reduce任务的输入。每个map任务可能会向任何分区派发键值对。相同键的所有值总要在一起进行reduce,无论它们来自哪个mapper。其结果是,所有map节点必须达成一致,确定由哪个reducer来处理不同的中间数据片段。Partitioner类确定了一个给定的键值对要去向哪一个reducer。默认的Partitioner为每个键计算散列值,并基于这个结果来分配分区
默认的分区是HashPartitioner

5、Combiner组件
Combiner组件的作用就是对Map阶段的输出的重复数据先做一次合并计算,然后把新的(key,value)作为Reduce阶段的输入。一个可选的处理步骤,用于优化MapReduce作业执行。如果存在的话,组合器在mapper之后、reducer之前运行。一个Combiner类的实例在每个map任务和部分reduce任务中运行。组合器接收mapper实例派发的所有数据作为输入,并尝试着组合有着相同键的值,从而缩小键空间,同时减少了需要排序的键(不必要的数据)的数量。接下来,组合器的输出会被排序并发送到reducer。
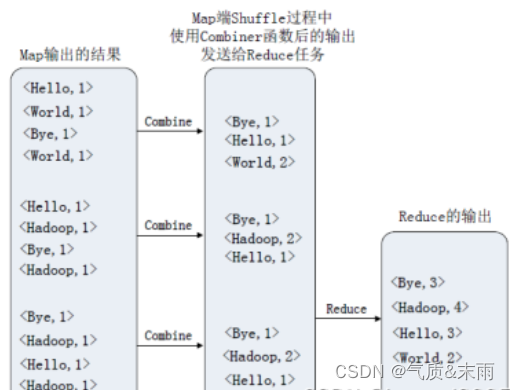
; 6、OutputFormat组件
OutputFormat是一个用于描述MapReduce程序输出格式和规范的抽象类。OutputFormat管理作业输出(作业输出由reducer生成,如果reducer不存在,则由mapper生成)的写方式。OutputFormat的职责是定义输出数据的位置以及用于保存结果数据的RecordWriter
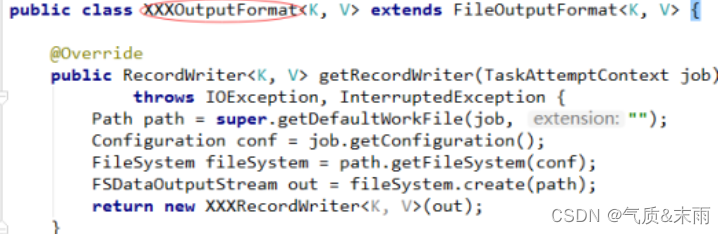
六、MapReduce运行模式
1、本地运行模式
在当前的开发环境模拟MapReduce执行环境,处理的数据及输出结果在本地操作系统
2、集群运行模式
把MapReduce程序打成一个Jar包,提交至Yarn集群上去运行任务。由于Yarn集群负责资源管理和任务调度,程序会被框架分发到集群中的节点上并发的执行,因此处理的数据和输出结果都在HDFS文件系统中。
七、MapReduce性能优化策略
使用Hadoop进行大数据运算,当数据量极其大时,那么对MapReduce性能的调优重要性不言而喻,尤其是Shuffle过程中的参数配置对作业的总执行时间影响特别大,我们可以从五个方面对MapReduce程序进行性能调优,分别是数据输入、Map阶段、Reduce阶段、Shuffle阶段和其他调优属性方面。
1、数据输入
在执行MapReduce任务前,将小文件进行合并,大量小文件会产生大量的map任务,增大map任务装载次数,而任务装载较耗时,从而导致MapReduce运行速度较慢。因此采用CombineTextInputFormat来作为输入,解决输入端大量的小文件场景。
2、Map阶段
减少溢写(spill)次数
减少合并(merge)次数
在map之后,不影响业务逻辑前提下,先进行combine处理,减少 I/O
3、Reduce阶段
合理设置map和reduce数
设置map、reduce共存
规避使用reduce
合理设置reduce端的buffer
4、Shuffle阶段
Shuffle阶段的调优就是给Shuffle过程尽量多地提供内存空间,以防止出现内存溢出现象,可以由参数mapred.child.java.opts来设置,任务节点上的内存大小应尽量大。
5、其它调优属性
MapReduce还有一些基本的资源属性的配置,这些配置的相关参数都位于mapred-default.xml文件中,我们可以合理配置这些属性提高MapReduce性能,例如合理设置MapTask、ReduceTask等参数。
Original: https://blog.csdn.net/m0_72168501/article/details/128309169
Author: 气质&末雨
Title: MapReduce 工作原理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/723948/
转载文章受原作者版权保护。转载请注明原作者出处!