

前言
- CIFAR-10介绍
- 下载、分类与读入数据集
* - 数据集下载
- 解压与分类数据集
- 读入数据
- 搭建神经网络
* - 卷积层(Convolutional layer)
- 池化层(Pooling lay)
- 残差网络(Residual Network)
- 全连接层(Fully connected layer)
- 激活函数(Activation function)
- 代码实现
- 模型结构
- 训练与测试模型
* - 损失计算
- 优化器
- 循环训练
- 测试
- 20轮训练结果
- 保存、加载模型
* - 保存模型
- 加载模型
- 实际测试效果
- 参考
正在学习深度学习中,主要用于复习与巩固。欢迎大家批评指正,一起讨论学习,进步。
CIFAR-10介绍
The CIFAR-10 and CIFAR-100 are labeled subsets of the 80 million tiny images dataset. They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton.
CIFAR-10 和 CIFAR-100 是 8000 万个微小图像数据集的标记子集。它们由 Alex Krizhevsky、Vinod Nair 和 Geoffrey Hinton 收集。
The dataset is divided into five training batches and one test batch, each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. The training batches contain the remaining images in random order, but some training batches may contain more images from one class than another. Between them, the training batches contain exactly 5000 images from each class.
数据集分为五个训练批次和一个测试批次,每个批次有 10000 张图像。测试批次恰好包含来自每个类别的 1000 个随机选择的图像。训练批次包含随机顺序的剩余图像,但一些训练批次可能包含来自一个类的图像多于另一个。在它们之间,训练批次恰好包含来自每个类别的 5000 张图像。
Here are the classes in the dataset, as well as 10 random images from each:
以下是数据集中的类,以及每个类的 10 张随机图像


The classes are completely mutually exclusive. There is no overlap between automobiles and trucks. “Automobile” includes sedans, SUVs, things of that sort. “Truck” includes only big trucks. Neither includes pickup trucks.
这些类是完全互斥的。汽车和卡车之间没有重叠。”汽车”包括轿车、SUV 之类的东西。”卡车”只包括大卡车。两者都不包括皮卡车。
; 下载、分类与读入数据集
数据集下载
网页下载:(http://www.cs.toronto.edu/~kriz/cifar.html)
百度网盘连接:链接:https://pan.baidu.com/s/1rwgBPp9fQ33goR77_0sj6Q
提取码:8wpb
包含的文件:

; 解压与分类数据集
为方便数据处理,将图片按照10个类别存放在各自的文件夹中。
处理后效果图:
分为测试集文件夹和训练集文件夹

测试集和训练集中都包含了10个类别的文件夹

训练集中每个类别有5000张图片,测试集有1000张

代码如下:
import os
from imageio import imsave
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
filename = 'cifar-10-batches-py文件夹的路径'
meta = unpickle(filename + '/batches.meta')
label_name = meta[b'label_names']
print(label_name)
for i in range(len(label_name)):
file = label_name[i].decode()
path = '想要建立文件夹train的路径' + file
isExist = os.path.exists(path)
if not isExist:
os.makedirs(path)
for i in range(1, 6):
content = unpickle(filename + '/data_batch_' + str(i))
for j in range(10000):
img = content[b'data'][j]
img = img.reshape(3, 32, 32)
img = img.transpose(1, 2, 0)
img_name = '建立文件夹train的路径' + label_name[content[b'labels'][j]].decode() + '/batch_' + str(i) + '_num_' + str(j) + '.jpeg'
imsave(img_name, img)
path = '建立文件夹train的路径'
filelist = os.listdir(path)
for item in filelist:
pathnew=os.path.join(path,item)
imagelist = os.listdir(pathnew)
j = 1
for i in imagelist:
src = os.path.join(os.path.abspath(pathnew), i)
dst = os.path.join(os.path.abspath(pathnew), '' + item + '.' + str(j) + '.jpeg')
j = j+1
os.rename(src, dst)
meta1 = unpickle(filename + '/test_batch')
label_name1 = meta[b'label_names']
for i in range(len(label_name1)):
file = label_name1[i].decode()
path = '想要建立文件夹test的路径' + file
isExist = os.path.exists(path)
if not isExist:
os.makedirs(path)
for j in range(10000):
img = meta1[b'data'][j]
img = img.reshape(3, 32, 32)
img = img.transpose(1, 2, 0)
img_name = '建立文件夹test的路径' + label_name[
meta1[b'labels'][j]].decode() + '/batch_' + str(j) + '_num_' + str(j) + '.jpeg'
imsave(img_name, img)
path = '建立文件夹test的路径'
filelist = os.listdir(path)
for item in filelist:
pathnew=os.path.join(path,item)
imagelist = os.listdir(pathnew)
j = 1
for i in imagelist:
src = os.path.join(os.path.abspath(pathnew), i)
dst = os.path.join(os.path.abspath(pathnew), '' + item + '.' + str(j) + '.jpeg')
j = j+1
os.rename(src, dst)
读入数据
transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_path = r'train文件夹路径'
test_path = r'test文件夹路径'
train_dataset = datasets.ImageFolder(train_path,transform=transforms)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataset = datasets.ImageFolder(test_path,transform=transforms)
test_loader = DataLoader(test_dataset , batch_size=64, shuffle=False)
搭建神经网络
深度学习的一般流程为:数据集准备,设计与搭建模型,构造损失和优化器,循环训练与测试(向前传播、反向传播、参数更新)。
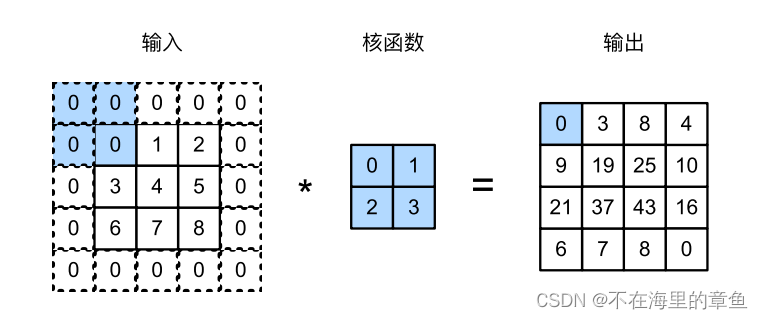
卷积层(Convolutional layer)
在用全连接层处理大尺寸图像时,需要将图像展开全连接,无法获得相邻数据的特征,丢失了空间信息;并且参数过多不易训练与泛化。卷积神经网络可以很好的解决这些问题。(个人对于卷积计算的简单理解就是可以提取图像特征,然后越来越抽象)
在卷积层中,输入张量和卷积核张量通过互相关运算产生输出张量。

torch.nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding)
in_channels :输入图像通道数
out_channels :卷积后的输出通道数
kernel_size : 卷积核尺寸;kernel_size=3,卷积核为3 _3;kernel_size=(3,4),卷积核为3_4.
stride :每次卷积运算的步长,默认为1
padding:在输入的张量周围填充
padding = 2:
池化层(Pooling lay)
池化层可以减少数据的空间大小,参数的数量和计算量也随之减少,一般卷积神经网络之间都会插入池化层。常见的有最大池化(Max Pooling)和平均池化(Avg Pooling)。
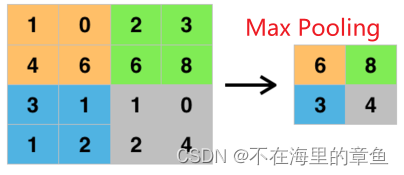
torch.nn.MaxPool2d(kernel_size,stride,padding)
torch.nn.AvgPool2d(kernel_size,stride,padding)
kernel_size : 池化窗口的大小
stride :每次的步长,通常为2
padding:在输入的张量周围填充
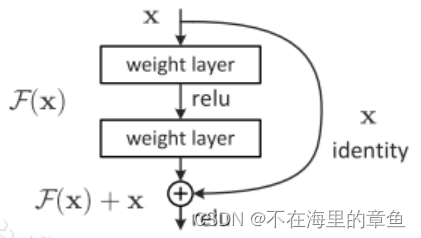
残差网络(Residual Network)
当神经网络模型层数过多的时候,会出现退化问题,即网络层数的增加,在训练集上的准确率却饱和或者下降了,这个又不能解释为过拟合,因为过拟合应该在训练集上表现更好才对。模型未能很好的被优化,靠前面的层未能得到很好的训练。
如果直接让一些层去拟合一个潜在的恒等映射函数H(x)= x,比较困难,这可能就是深层网络难以训练的原因。但是,如果把网络设计为H(x)=F(x)+ x 。我们可以转换为学习一个残差函数F(x)= H(x)一x。只要F(x)= 0,就构成了一个恒等映射H(X)= a。而且,拟合残差肯定更加容易。
F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是F(5)=5.1,引入残差后是H(5)= 5.1,H(5)= F(5)+5,F(5)= 0.1。这里的F’和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如s输出从5.1变到5.2,映射F’的输出增加了2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。 残差的思想都是去掉相同的主体部分,从而突出微小的变化。
; 全连接层(Fully connected layer)
全连接层,是每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的。
其中,x1、x2、x3为全连接层的输入,a1、a2、a3为输出,

在最后使用全连接层可以进行分类。
注意:在模型的最后一个全连接层不需要使用激活函数。因为计算损失使用的是torch.nn.CrossEntropyLoss,它相当于:softmax + log + nllloss。
激活函数(Activation function)
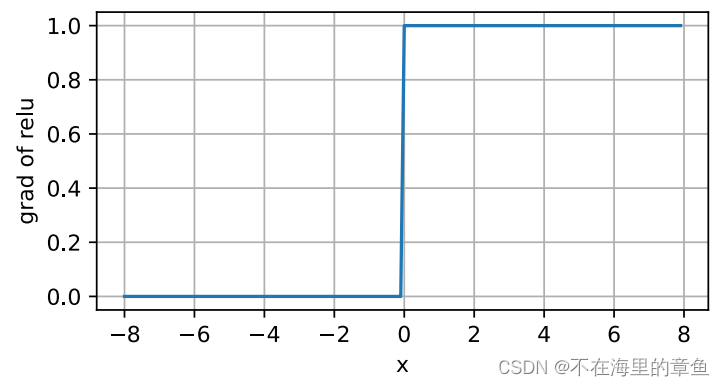
这里使用的是:线性整流(Rectified Linear Units, ReLU)。
ReLU(x)=max(x,0)
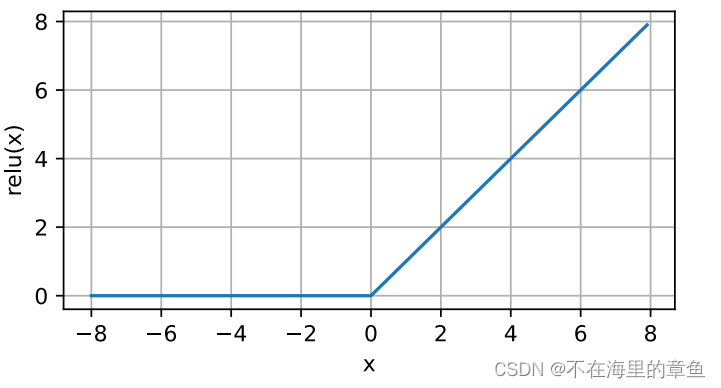
使⽤ReLU的原因是,它求导表现得特别好:要么让参数消失,要么让参数通过。这使得优化表现得更好,并且ReLU减轻了困扰以往神经⽹络的梯度消失问题。
; 代码实现
class ResidualBlock(nn.Module):
def __init__(self,channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels,channels,kernel_size=3,padding=1)
self.conv2 = nn.Conv2d(channels,channels,kernel_size=3,padding=1)
def forward(self,x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(3,16,kernel_size=5)
self.conv2 = torch.nn.Conv2d(16,32,kernel_size=5)
self.mp = torch.nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc1 = torch.nn.Linear(800,512)
self.fc2 = torch.nn.Linear(512, 256)
self.fc3 = torch.nn.Linear(256, 128)
self.fc4 = torch.nn.Linear(128, 10)
def forward(self,x):
batch_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.rblock1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.rblock2(x)
x = x.view(batch_size,-1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = self.fc4(x)
return x
模型结构

; 训练与测试模型
model = Net()
损失计算
criterion = torch.nn.CrossEntropyLoss()
优化器
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
循环训练
def train(epoch):
running_loss = 0.0
for batch_idx,data in enumerate(train_loader,0):
inputs,target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299 :
print('[%d,%5d] loss : %.3f' % (epoch + 1,batch_idx + 1,running_loss / 300))
running_loss = 0.0
测试
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs,target = data
outputs = model(inputs)
_, predicted = torch.max(outputs.data,dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
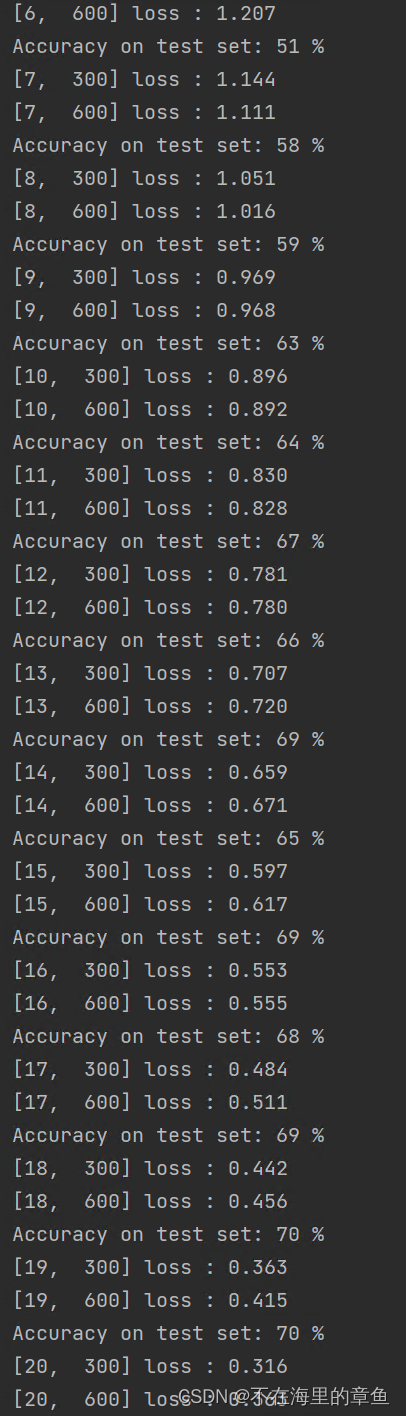
20轮训练结果
; 保存、加载模型
保存模型
保存参数:
torch.save(model.state_dict(), "./model_parameter.pkl")
保存模型
net = Net()
torch.save(net, 'model_name.pth')
加载模型
model = Net()
model_path = r'./model_parameter_cpu.pkl'
checkmodel = torch.load(model_path, 'cpu')
model.load_state_dict(checkmodel)
实际测试效果
model_path = r'./model_parameter_cpu.pkl'
classes = ['airplane','automobile','bird','cat','deer','dog','frog','horse','ship','truck']
def prediect(img_path):
checkmodel = torch.load(model_path, 'cpu')
model.load_state_dict(checkmodel)
torch.no_grad()
img = Image.open(img_path)
img = transforms(img).unsqueeze(0)
outputs = model(img)
_,predicted = torch.max(outputs,1)
print(test_img_path)
print('this picture maybe :', classes[predicted[0]])
if __name__ == '__main__':
prediect(test_img_path)
运行结果:

参考
1、B站刘二大人教程:《PyTorch深度学习实践》完结合集
2、动⼿学深度学习 AstonZhang,ZacharyC.Lipton,MuLi,andAlexanderJ.Smola
Original: https://blog.csdn.net/m0_54567165/article/details/127138945
Author: 不在海里的章鱼
Title: Pytorch深度学习记录:对CIFAR-10的深度学习模型搭建与测试
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/719983/
转载文章受原作者版权保护。转载请注明原作者出处!