

pandas学习(五)merge
- .concat() 通常用来连接DataFrame对象。默认情况下是对两个DataFrame对象进行纵向连接, 当然通过设置参数,也可以通过它实现DataFrame对象的横向连接。
- .merge() 和pd.concat()不同,pd.merge()只能用于两个表的拼接,而且通过参数名称也能看出连接方向是左右拼接,一个左表一个右表,而且参数中没有指定拼接轴的参数,所以pd.merge()不能用于表的上下拼接。
- .append() ,的默认操作效果跟concat()相同, 都是实现两个DataFrame的纵向连接。事实上可以把它看做concat()的早期版本:
1.数据集1
1.1 创建数据集
raw_data_1 = {
'subject_id': ['1', '2', '3', '4', '5'],
'first_name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
'last_name': ['Anderson', 'Ackerman', 'Ali', 'Aoni', 'Atiches']}
raw_data_2 = {
'subject_id': ['4', '5', '6', '7', '8'],
'first_name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'last_name': ['Bonder', 'Black', 'Balwner', 'Brice', 'Btisan']}
raw_data_3 = {
'subject_id': ['1', '2', '3', '4', '5', '7', '8', '9', '10', '11'],
'test_id': [51, 15, 15, 61, 16, 14, 15, 1, 61, 16]}
data1 = pd.DataFrame(raw_data_1, columns = ['subject_id', 'first_name', 'last_name'])
data2 = pd.DataFrame(raw_data_2, columns = ['subject_id', 'first_name', 'last_name'])
data3 = pd.DataFrame(raw_data_3, columns = ['subject_id','test_id'])
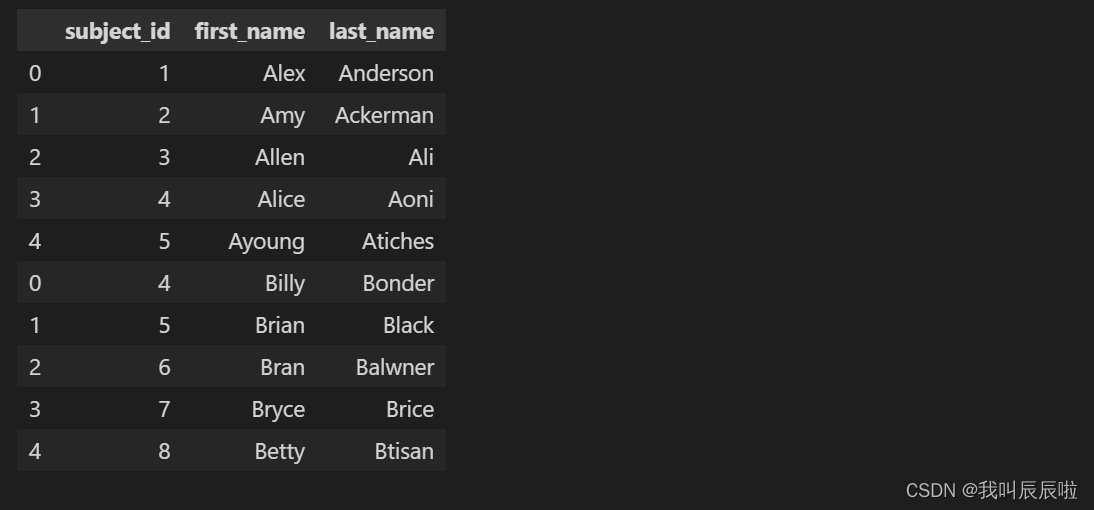
1.2 沿行拼接两个数据集
all_data = pd.concat([data1, data2])
all_data

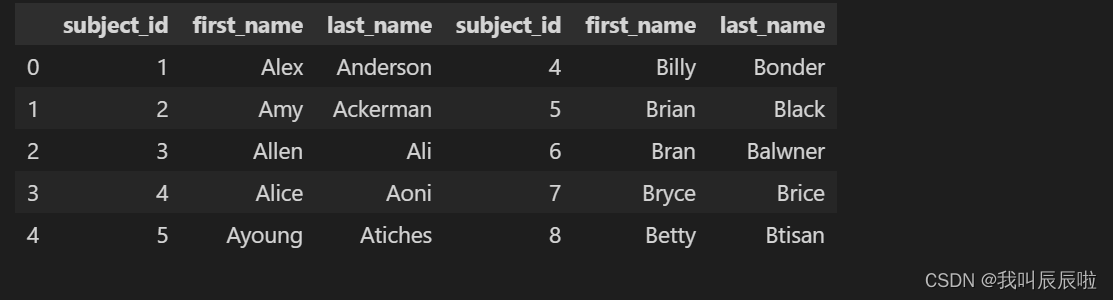
1.3 沿列拼接两个数据集
all_data_col = pd.concat([data1, data2], axis = 1)
all_data_col
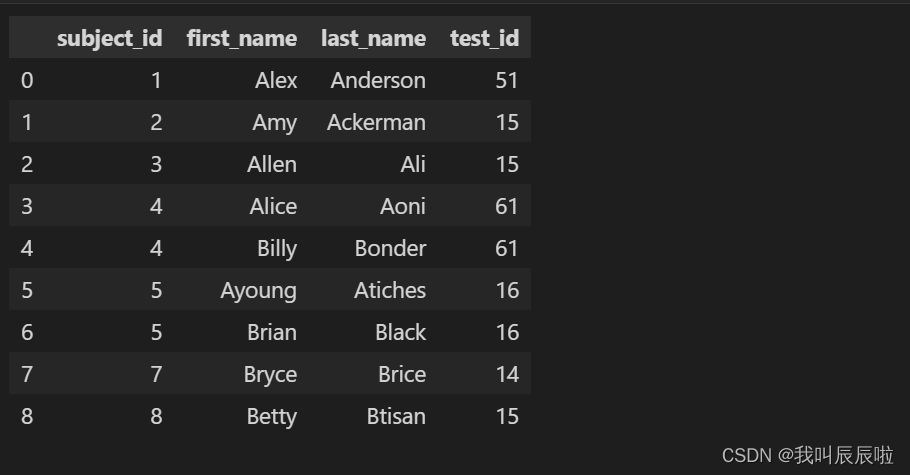
1.4 按subject_id合并数据集
pd.merge(all_data, data3, on='subject_id')
1.5 仅合并在 data1 和 data2 上具有相同”subject_id”的数据
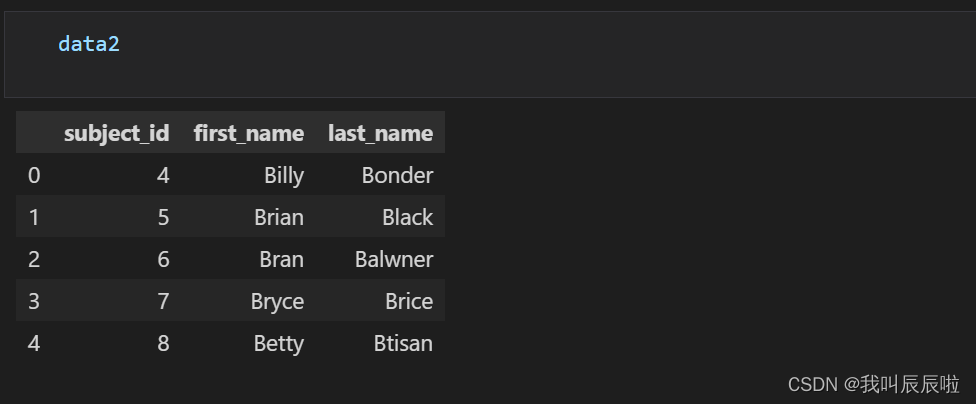
pd.merge(data1, data2, on='subject_id', how='inner')

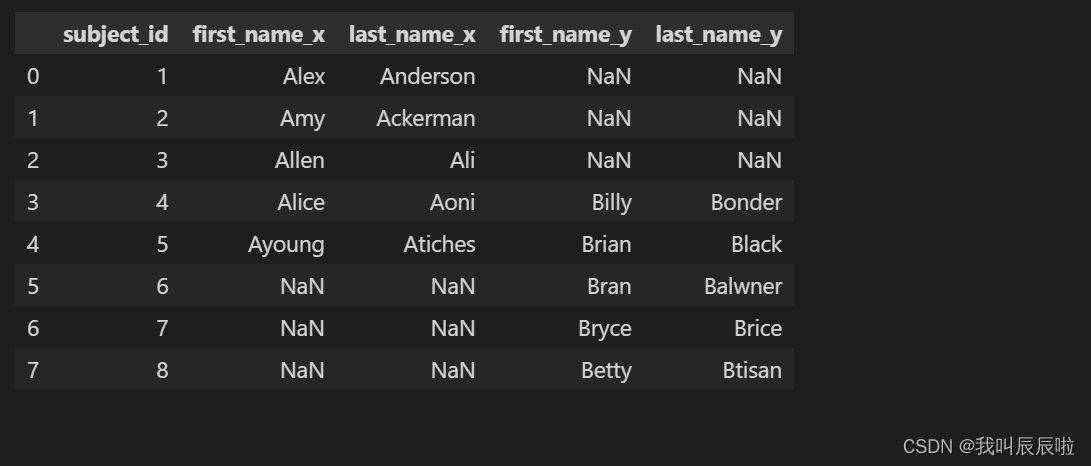
1.6 合并 data1 和 data2 中的所有值,并在可用的情况下使用来自两端的匹配记录。
pd.merge(data1, data2, on='subject_id', how='outer')
2.数据集2
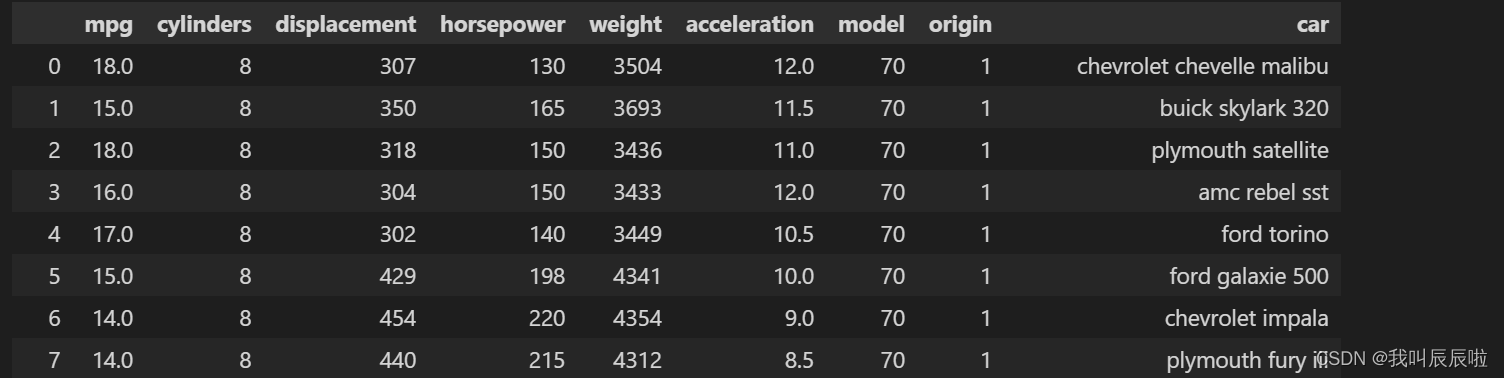
2.1 合并两个数据集
cars = cars1.append(cars2)
cars
2.2 创建一个从 15,000 到 73,000 的随机数序列。
nr_owners = np.random.randint(15000, high=73001, size=398, dtype='l')
nr_owners
Original: https://blog.csdn.net/weixin_44026026/article/details/126338295
Author: 我叫辰辰啦
Title: pandas学习(五)merge
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/679205/
转载文章受原作者版权保护。转载请注明原作者出处!